Предложение с обращением / Предложение / Синтаксис и синтаксический разбор / Справочник по русскому языку для начальной школы
Главная
Справочники
Справочник по русскому языку для начальной школы
Синтаксис и синтаксический разбор
Предложение
Предложение с обращением
В предложениях, особенно побудительных, очень часто используются обращения.
Обращение — это слово или сочетание слов, называющее того, к кому обращаются с речью.
Обращение обычно является именем существительным в именительном падеже (Здравствуй, солнце!), или сочетанием существительного с прилагательным (Здравствуй, солнце ясное!).
Запомни, что обращение не является членом предложения!
В устной речи обращения особо выделяются голосом.
На письме обращения всегда выделяются запятыми:
Если обращение стоит в начале предложения, то оно отделяется запятой.
Например: Мама, можно мне почитать еще немного?
Если обращение стоит в середине предложения, то оно выделяется запятыми с обеих сторон.
Например: На этот раз, Толя, я тебя обязательно обгоню!
Если обращение стоит в конце предложения, то запятая ставится перед обращением.
Например: До новых встреч, дорогие ребята!
Обращение может отделяться восклицательным знаком, если произносится с сильным чувством. В этом случае после восклицательного знака следующее слово пишется с заглавной буквы.
Например:Мама! Я так соскучилась по тебе!
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Виды предложения по цели высказывания
Предложения и их эмоциональная окраска (интонация)
Главные члены предложения – подлежащее и сказуемое
Второстепенные члены предложения
Предложения распространенные и нераспространенные
Однородные члены предложения
Простое и сложное предложения
Предложения с прямой речью
Словосочетание
Предложение
Синтаксис и синтаксический разбор
Правило встречается в следующих упражнениях:
1 класс
Страница 7,
Климанова, Рабочая тетрадь
2 класс
Упражнение 229,
Полякова, Учебник, часть 2
3 класс
Упражнение 25,
Канакина, Рабочая тетрадь, часть 1
Упражнение 26,
Канакина, Рабочая тетрадь, часть 1
Упражнение 88,
Канакина, Рабочая тетрадь, часть 1
Упражнение 168,
Канакина, Горецкий, Учебник, часть 2
Упражнение 19,
Климанова, Бабушкина, Учебник, часть 1
4 класс
Упражнение 19,
Канакина, Горецкий, Учебник, часть 1
Упражнение 161,
Канакина, Рабочая тетрадь, часть 2
Упражнение 20,
Климанова, Бабушкина, Учебник, часть 1
Упражнение 22,
Климанова, Бабушкина, Учебник, часть 1
Упражнение 23,
Климанова, Бабушкина, Учебник, часть 1
Упражнение 2,
Климанова, Бабушкина, Учебник, часть 1
Упражнение 412,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 486,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 594,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 731,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
5 класс
Упражнение 215,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 218,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 356,
Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Кастельно Франсис (1812–1880), французский путешественник о русской армии:
«Дух войск показался мне превосходным; люди сильны, хорошо вытренированны, полны мужества, с прекрасными, светлыми и кроткими глазами.»
Яков Рейтенфельс, посол римского папы в Москве в 1670–1673 гг.:
«Мосхи весьма способны переносить всякого рода трудности, так как их тела закалены от рождения холодом. Они спокойно переносят суровость климата и нисколько не страшатся выходить с открытою головою под снег или дождь, равно как и на зной, словом, в какую бы то ни было погоду. Дети трех-четырех лет от роду, зачастую, в жесточайшие морозы, ходят босые, еле прикрытые полотняною одеждою и играют на дворе, бегая взапуски. Последствием сего являются знаменитые закаленные тела, и мужчины, хоть и не великаны по росту, но хорошо и крепко сложенные, из которых иные, совершенно безоружные, иногда вступают в борьбу с медведями и, схватив за уши, держат их, пока те не выбьются из сил; тогда они им, вполне подчиненным и лежащим у ног, надевают намордник. Калек или возбуждающих жалость несчастных, обладающих каким-либо природным недостатком, меж них встречается крайне мало…»
Арабский путешественник Абу-Обейд-Абдаллахала Бекри о русских банях:
«И не имеют они купален, но устраивают себе дом из дерева и законопачивают щели его зеленоватым мхом. В одном из углов дома устраивают очаг из камней, а на самом верху, в потолке, открывают окно для выхода дыма. В доме всегда имеется ёмкость для воды, которой поливают раскалившийся очаг, и поднимается тогда горячий пар. А в руках у каждого связка сухих ветвей, которой, махая вокруг тела, приводят в движение воздух, притягивая его к себе… И тогда поры на их теле открываются и текут с них реки пота, а на их лицах – радость и улыбка».
Корб Иоанн (1670–1741) – австрийский дипломат, секретарь австрийского посла Гвариента о свадебном обряде:
«По окончании обряда (венчания) невеста падает в ноги жениху и касается головой его сапог в знак покорности, в свою очередь жених покрывает ее полою кафтана, свидетельствуя этим, что он принимает ее под свое покровительство».
Предложения с обращениями — ПРЕДЛОЖЕНИЯ С ОБРАЩЕНИЯМИ, ВВОДНЫМИ КОНСТРУКЦИЯМИ И МЕЖДОМЕТИЯМИ
Объяснительные диктанты
I
1) Любите живопись, поэты! (Н. Заболоцкий) 2) Дорогая, сядем рядом, поглядим в глаза друг другу. (С. Есенин) 3) Наша обязанность, моя милая, исправить его ошибку. (Л. Толстой) 4) Здравствуй, князь ты мой прекрасный! (А. Пушкин) 5) Я люблю тебя, жизнь! (К. Ваншенкин) 6) Здравствуй, племя младое, незнакомое! (А. Пушкин) 7) Что, дремучий лес, призадумался? (А. Кольцов)
• Выделите обращения. Определите, какую роль (звательную, изобразительную, оценочную) выполняет обращение в каждом примере.
• Укажите предложения с риторическим обращением.
• Найдите слово, в котором правописание согласной в приставке зависит от последующего согласного звука.
• Найдите слово с неизменяемой приставкой.
• Выделите приставки в словах предложений 6 и 7, объясните их правописание.
• Среди предложений 2—4 найдите слова, в которых происходит оглушение звонкого согласного.
II
• Послушайте шуточное стихотворение Р. Куликовой. Как оно построено?
Дедушка-медведушка
— Дедушка-медведушка,
Миленький ты мой,
В хор меня не приняли,
Успокой.
— Разве это горюшко?
Ну и молодёжь…
Ты без хора, внученька,
Хорошо ревёшь.
• Запишите текст стихотворения под диктовку. Выделите обращения.
• Проведите синтаксический разбор предложения 1. Какое это предложение по количеству грамматических основ? А по составу грамматических основ? Укажите способ выражения сказуемого в простых частях данной сложной конструкции и определите вид односоставных предложений.
• Укажите в тексте стихотворения все частицы, определите их разряд.
• Проведите фонетический разбор слова ревёшь. Объясните причину несоответствия количества букв и звуков в данном слове. Найдите ещё слова в тексте стихотворения, в которых количество букв и звуков не совпадает. Объясните причину такого несоответствия в каждом конкретном примере.
III
• Послушайте поэтические строки А. Блока. О чём они?
* * *
О, весна без конца и без краю —
Без конца и без краю мечта!
Узнаю тебя, жизнь! Принимаю!
И приветствую звоном щита!
Принимаю тебя, неудача,
И удача, тебе мой привет!
В заколдованной области плача,
В тайне смеха — позорного нет!
• Запишите поэтические строки А. Блока под диктовку. Выделите обращения. Как они должны быть оформлены с точки зрения пунктуации?
• Найдите причастие, выделите в нём причастную орфограмму и объясните её правописание. Разберите причастие по составу, проведите морфологический разбор.
• ТР. Напишите небольшое сочинение-рассуждение на тему: “Мои размышления после прочтения поэтических строк А. Блока “О, весна без конца и без краю…””
IV
1) Край любимый! Сердцу снятся
Скирды солнца в водах лонных. (С. Есенин)
2) Россия! Сердцу милый край! (С. Есенин)
3) Слушают ракиты Посвист ветряной…
Край ты мой забытый,
Край ты мой родной!.. (С. Есенин)
4) Богат мой край родной славными сыновьями. 5) Люблю мой край, спокойный, скромный, полный невысказанного очарования. 6) Изучай свой край, его природу, его историю, жизнь людей. 7) Моя берегиня — мой край родной.
• Определите, чем является слово край в записанных предложениях. Укажите синтаксический статус слова край в каждом конкретном примере.
V
Салют Победы
Салютами встречая День Победы,
Мы свято чтим героев имена
И слушаем рассказ отцов и дедов
О том, какой бедой была война…
Цветы весны — вам, рыцари сражений,
За то, что наша родина живёт,
За то, что вы не стали на колени,
А в битвах постояли за неё.
Вас никогда потомки не забудут!
Из года в год с живыми вы в строю.
И на поверках выкликаться будут
Богатыри, погибшие в бою.
Греми, салют, из тысячи орудий!
Мир, торжествуй победу над войной,
Чтоб вечно были радостными люди
И небо голубым над головой.
(Е. Викулин)
• Обоснуйте расстановку знаков препинания.
• ТР. Дайте письменный развёрнутый ответ на вопрос: “Какова роль риторических обращений в тексте стихотворения Е. Викулина “Салют Победы”? (Ключ: Риторическое обращение — синтаксическая фигура, в которой в форме обращения к неодушевлённым предметам, явлениям, отвлечённым понятиям выражается различное отношение автора к тому, о чём говорится. Риторические обращения придают речи торжественность, патетичность, выразительность.)
Выборочные диктанты
I
1) Хорошо, друзья, приятно, сделав дело, ко двору — в батальон идти обратно из разведки поутру. (А. Твардовский) 2) Мои друзья — книги. 3) Друзья мои, не умирайте. (Вл. Соколов) 4) Учитель! перед именем твоим позволь смиренно преклонить колени! (Н. Некрасов) 5) Мой брат — учитель. 6) Иван Иваныч, учитель биологии, любил проводить уроки на природе.
• Найдите предложения с обращениями. Обращения выделите.
• В каком предложении обращение выделяется восклицательным знаком? Объясните данный выбор.
• Укажите синтаксический статус слова учитель в предложениях 5 и 6.
• Среди предложений 4—6 найдите прямые дополнения, подчеркните, укажите способ их выражения.
II
• Послушайте стихотворение. Назовите его автора.
* * *
Сыпь, тальянка, звонко, сыпь, тальянка, смело!
Вспомнить, что ли, юность, ту, что пролетела?
Не шуми, осина, не пыли, дорога.
Пусть несётся песня к милой до порога.
Пусть она услышит, пусть она поплачет:
Ей чужая юность ничего не значит.
Ну, а если значит — проживёт, не мучась,
Где ты, моя радость? Где ты, моя участь?
Лейся, песня, пуще, лейся, песня, звянше.
Всё равно не будет то, что было раньше.
За былую силу, гордость и осанку
Только и осталась песня под тальянку.
(С. Есенин)
• Запишите под диктовку.
• Найдите предложения, в составе которых есть обращения. Как они выделяются на письме?
• Охарактеризуйте обращения, которые встретились в стихотворении С.А. Есенина: распространённое или нераспространённое, простое или риторическое.
• ТР. Напишите небольшое сочинение-рассуждение на тему: “Роль риторических обращений в стихотворении С.А. Есенина ““Сыпь, тальянка, звонко…””
Творческие диктанты
I
• Составьте со словом “родина” или со словом “друг” предложения так, чтобы данное слово являлось: 1) обращением; 2) подлежащим; 3) сказуемым; 4) приложением.
II
• Запишите предложения.
1) Учитель поинтересовался, каковы у ребят планы на весенние каникулы. 2) Одноклассники спросили у Кати, пойдёт ли она с ними в краеведческий музей. 3) Классный руководитель посоветовал пятиклассникам познакомиться с книгой Порудоминского “Моя первая Третьяковка”.
• Преобразуйте записанные предложения таким образом, чтобы в них было использовано обращение.
Предложения с обращениями. 5-й класс
Цель урока: повторить и закрепить сведения об
обращении.
Образовательные задачи:
повторить определение понятия “обращение”;
дать представление об использовании обращения
в речи;
закрепить постановку знаков препинания в
предложении с обращением;
повторить постановку знаков препинания при
однородных членах и в сложном предложении.
Оборудование: компьютер, мультимедийный
проектор, экран, карточки с заданиями, таблица
“Составление схемы предложения с обращением”.
Ход урока
I. Организационный момент.
Сегодня, ребята, мы продолжим с вами работать
над темой “Обращение”.
Начнем с игры “Составь предложение”. Решив ряд
задач, вы должны из нескольких компонентов
составить предложение, которое будете
записывать в тетрадь, по мере выполнения каждого
задания. Несколько человек будут выполнять
индивидуальные задания по карточкам.
II. Работа с карточками. (Приложение 1)
III.
Синтаксическая пятиминутка. Игра “Составь
предложение”. (Приложение 2)
Итак, прочитайте, какое предложение у вас
получилось.
Опустились легкие снежинки на тропинки.
IV. Закрепление материала.
1. Анализ предложений.
Задание. Переделайте полученное
предложение так, чтобы подлежащее стало
обращением. Выполните синтаксический разбор
данного предложения.
Легкие снежинки, опуститесь на тропинки.
2. Фронтальный опрос:
а) Обращение является членом предложения?
б) Входит обращение в грамматическую основу
предложения?
в) Как же вы будете отличать подлежащее от
обращения? Назовите отличительные признаки.
Подлежащее входит в грамматическую основу, от
сказуемого можно задать вопрос к подлежащему, а
обращение не входит в грамматическую основу, к
нему нельзя задать вопрос от сказуемого.
Обращения произносятся с особой интонацией,
после обращения нужно делать паузу.
3. Запись предложений на доске.
Ребята, а ведь подлежащее и обращение имеют и
общие признаки. Давайте запишем еще несколько
предложений и разберемся в этом.
Школьники соблюдают правила дорожного
движения. – Соблюдайте, школьники, правила
дорожного движения.
Друзья прочитают интересную книгу о покорении
космоса. – Прочитайте интересную книгу о
покорении космоса, друзья.
Вопрос: Назовите общие признаки (Выражены
существительными в именительном падеже, могут
стоять в любом месте в предложении).
Физкультминутка (упражнение для глаз)
4. Комментированное письмо.
Да, ребята,
Всем нам при обращении
Поможет обращение.
К людям, звездам или птицам
Можно смело обратиться.
Только, друг, не забывай:
Запятые расставляй. (А.Косоговский)
Задание. Запишите предложения, объясните
постановку знаков препинания и нарисуйте схемы.
1. Братцы, что он про меня сочиняет?
2. Ты, Пилюлькин, все трудишься, все другим
помогаешь?
3. Я вам открою тайны здешних мест, друзья.
Вывод: Итак, обращения выделяются запятыми.
Если обращения стоят в начале или в конце
предложения, то выделяются одной запятой, если в
середине – двумя.
5. Выборочный диктант (с последующей проверкой).
Мы с вами, ребята, разобрали предложения, в
которых в роли обращения употребляли
собственные имена существительные. Но в
поэтической речи в роли обращения встречаются
существительные, которые обозначают неживые
предметы.
Задание. Из предложений, которые я вам буду
читать, выписать обращения.
1. Серебристая дорога, ты зовешь меня куда?
2. Я вижу вас, родные степи.
3. Расцветай, наш край родной.
4.
Я люблю тебя, Россия.
Сыпь ты, черемуха, снегом.
Вывод: Обращение может состоять как из одного
слова, так и из сочетания слов.
6. Творческая работа в группах.
Задание. Составьте диалог, употребив
обращения:
1 гр. – “В библиотеке”
2 гр. – “В музее”
3 гр. – “В магазине”
4 гр. – “В гостях”
Вывод: обращения в устной речи выделяются
интонационно.
7. Работа с сигнальными карточками.
Задание. Я читаю вам предложение, а вы
показываете мне ту карточку, схема которой
соответствует структуре указанного предложения.
1. Прощай, любимый город.
2. Добро пожаловать, скворцы.
3. Прилетели птицы и наполнили лес своим пением.
4. Небо медленно заволокли тучи, и по лесу прошел
ветер.
5. Вылезайте, муравьи, после зимней стужи.
6. Ребята, охраняйте птиц.
V. Подведение итогов. Выставление оценок.
1. Что такое обращение?
2. Как обращения выделяются на письме?
3. Чем выражены обращения?
4. Какое место в предложении могут занимать
обращения?
5. Назовите отличительные признаки обращения и
подлежащего.
VI. Работа с тестом (Приложение 3)
А теперь проверим, как вы усвоили изученный
материал: поработаем с тестами.
VII. Объяснение домашнего задания.
Часто по обращению можно понять, каков тот
человек, который обращается, и тот, к кому
обращаются. Обращением можно выразить ласку,
доброту, заботу и наоборот, злость, недовольство.
Очень часто обращение раскрывает героя
произведения.
Ваша задача дома выписать предложения с
обращениями из “Сказки о мертвой царевне и семи
богатырях”, конкретно — с обращениями к
волшебному зеркалу. Посмотреть, как изменяется
характер обращений к одному и тому же предмету в
зависимости от настроения говорящего.
Приложение 1
Карточка 1
Задание. Найдите обращения, расставьте знаки
препинания. Назовите басню.
Соседка перестань срамиться, тебе ль с слоном
возиться.
Послушай-ка дружище! Ты, сказывают, петь великий
мастерище.
Друзья К чему весь этот шум? Я, ваш старинный
сват и кум, пришел мириться к вам, совсем не ради
ссоры…
Ну, что ж Хавронья там ты видела такого?
Карточка 2
Задание. Найдите обращения, расставьте знаки
препинания. Назовите басню.
Как милый Петушок поешь, ты громко, важно!
Как смеешь ты наглец нечистым рылом здесь
чистое мутить питье мое с песком и илом?
А вы друзья как ни садитесь, все в музыканты не
годитесь.
Чем кумушек считать трудиться, не лучше ль на
себя кума оборотиться?
Карточка 3
Задание. Найдите обращения, расставьте знаки
препинания. Назовите басню.
Смотри-ка кум милый, что это там за рожа?
Спой светик не стыдись! Что, ежели сестрица при
красоте такой и петь ты мастерица!
Досуг мне разбирать вины твоей щенок!
А ты Кукушечка мой свет как тянешь плавно и
протяжно…
Приложение 2
Задание. Составьте предложение, решив ряд
задач.
Из предложения Парашютисты опустились в
центре стадиона взять сказуемое.
Из предложения Вдруг послышались легкие шаги взять определение.
Добавить подлежащее из предложения На щеках
тают снежинки.
Взять существительное, выступающее в роли
дополнения
Тропинки в саду засыпали листья.
(Употребить данное существительное в
винительном падеже с предлогом на).
Приложение 3
Вариант 1
Задание. Найдите предложения с обращениями,
знаки препинания не расставлены.
I.
С добрым утром дорогие друзья”
Лес пахнет дубом и сосной.
Ласково мерцали звезды в вышине.
Ребята берегите природу!
Догорай костер дотла.
II.
Садись Гунька сейчас я тебя рисовать буду.
Послушайте братцы какие я стихи сочинил.
Незнайка очень не любил касторку.
Слушай Незнайка выручи меня отсюда.
Назад Булька!
Вариант 2
Задание. Найдите предложения с обращениями,
знаки препинания не расставлены.
I.
Благослови нас на подвиг родная земля!
Друзья давайте жить честно.
Принесите мне книгу о животных.
Сердечный друг ты не здорова?
К утру мороз крепчал.
II.
Жили волшебники в прежние времена.
Ой Тотошка какой ты смешной.
Элли скорей сюда.
Тотошка убежал в дом.
Это прада сударыня?
Решение на Задание 393 из ГДЗ по Русскому языку за 8 класс: Ладыженская Т.А.
Выпишите предложения с междометием О, употреблённым только вместе с обращением. Расставьте недостающие знаки препинания.
1. О рьяный конь о конь морской С бледно-зелёной гривой, То смирный ласково-ручной То бешено-игривый!
2. Всё прошло всё взяли годы — Поддался и ты судьбе, О Дунай — и пароходы Нынче рыщут по тебе.
3. Как хорошо ты о море ночное — Здесь лучезарно, там сизо-темно…
4. О буйные ветры Скорее, скорей! Скорей нас сорвите С докучных ветвей!
5. И любо мне и сладко мне И мир в моей груди Дремотою обвеян я, — О время погоди!
6. Я очи знал, — о эти очи! Как я любил их, знает Бог!(Ф. Тютчев)
Порядок разбора
Синтаксический разбор предложения, осложнённого обращениями, вводными и вставными конструкциями, грамматически не связанными с членами предложения, проводится в том порядке, какой определён в § 28 «Синтаксический разбор двусоставного предложения» и в § 38 «Синтаксический разбор односоставного предложения». Дополнения вносятся в пункт 4. В нём указывается, что предложение осложнено обращением, вводными и вставными конструкциями.Образец разбора
1. Опять я ваш, о юные друзья! (А. Пушкин)Устный разбор
Это предложение повествовательное, восклицательное. Грамматическая основа — я (подлежащее), ваш (сказуемое), значит, оно простое, двусоставное. В предложении есть второстепенные члены, поэтому оно распространённое. Предложение осложнено распространённым обращением (о юные друзья).
Подлежащее — я, выражено личным местоимением. Сказуемое — ваш, именное сказуемое, выражено местоимением. О юные друзья — словосочетание, являющееся обращением, оно грамматически не связано с членами предложения.Письменный разбор
2. Казалось, снег идти хотел. (А. Пушкин)Устный разбор
Это предложение повествовательное, невосклицательное. Грамматическая основа — снег (подлежащее), хотел идти (сказуемое). В предложении нет второстепенных членов, поэтому оно нераспространённоё. Предложение осложнено вводным словом (казалось), обозначает неуверенность.
Подлежащее — снег, выражено существительным. Сказуемое — хотел идти, составное глагольное сказуемое, выражено глаголом-связкой (хотел) и глаголом в неопределённой форме (идти). Казалось — вводное слово, грамматически не связано с членами предложения.Письменный разбор
Синтаксический и пунктуационный разбор предложения со словами, словосочетаниями и предложениями
1. Шестнадцатое апреля
ТЕМА: Синтаксический и пунктуационный разбор предложения со словами , словосочетаниями и предложениями , грамматически не связанными с членами предложения
2. Цели урока:
• повторить и систематизировать материал по теме «Предложения с вводными конструкциями, обращениями и междометиями»; • закрепить знания о постановке знаков препинания в осложненных предложениях и умение производить синтаксический и пунктуационный разбор предложений с вводными конструкциями, обращениями и междометиями. 1. Повторите, почему мы считаем, что междометия, обращения, вводные и вставные конструкции не связаны с членами предложения? 2. Работа с учебником: § 64 рассмотреть порядок и образец синтаксического и пунктуационного разбора осложнённых предложений
3.
В чём различие употреблений выделенных слов ? Выполните синтаксический разбор предложений. • По синему небу и обилию света чувствуется наступление весны . • Сегодня , чувствуется ,к вечеру будет дождь. • Они прошли довольно близко , но , кажется , не заметили нас. • Озеро с высоты кажется огромным зеркалом.
4. Спишите предложение . Запишите цифрами ответ (на месте каких цифр должны стоять запятые.)
5. Вставьте после выделенных слов вводные конструкции и запишите полученные предложения
• Пароход отчалил и пошел вверх по темной реке.(Я это увидел, когда оглянулся) • Лодка застыла на тихой воде.(Казалось) • Асфальтовое шоссе проходило неподалеку от дома.(К нашему несчастью) • В ручье виднелись пестрые камешки.(Вода была очень прозрачной) • Ночью было страшно (Ух) Проверьте: Пароход (я это увидел, когда оглянулся) отчалил и пошел вверх по темной реке. Лодка, казалось, застыла на тихой воде. Асфальтовое шоссе, к нашему несчастью, проходило неподалеку от дома. В ручье — вода была очень прозрачной — виднелись пестрые камешки. Ночью ( Ух!) было страшно.
6. Составьте по картинке предложение с обращением и выполните его пунктуационный разбор
7. Составьте предложение со вставной конструкцией (Длинношее животное) и произведите его синтаксический разбор.
8. Составьте по картинке предложение с вводным словом и сделайте его пунктуационный разбор
Цели урока:1. Знать определение понятия и об использовании обращения в речи. Уметь находить обращения в предложении; отличать от подлежащего; составлять с ними предложения; выразительно читать предложения с обращением.
Белки готовят на зиму разнообразный корм: орехи, шишки, грибы.
3.Индивидуальнаяработа.
Расставить знаки препинания в предложениях и объяснить.
а ) Декабрь год кончает а зиму начинает.
б ) Пришвин писатель.
Пушкин поэт.
Васнецов художник.
Вывод: Какие члены предложения называются однородными?
Какова роль обобщающих слов в речи?
Когда ставится тире между подлежащим и сказуемым?
III. Объяснение новой темы.
Запись на доске.
1.Ребята бережно обращаются с учебниками.
2.Ребята, бережно обращайтесь с учебниками.
Выразительное чтение предложений, соблюдая интонацию. Разбор по членам предложений.
Анализ второго предложения.
Вывод: Второе предложениес обращением.
Обращение – это слово или сочетание слов, называющее того, к кому обращаются с речью.
Где стоит обращение?
Преобразуйте предложение так, чтобы обращение стояло в середине и в конце. Объяснить знаки препинания.
Запишите в тетради.
Слово учителя: Если обращение стоит в начале предложения и произносится с восклицательной интонацией, то после него ставится восклицательный знак.
Ребята! Бережно обращайтесь с учебниками.
Разберите предложение по членам.
Вывод: Обращение не входит в грамматическую основу предложения, к нему нельзя задать вопрос от сказуемого. Следовательно, не является членом предложения. Роль обращения обычно выполняет существительное в Им.п.
Работа с учебником
IY.Физкультминутка.
Y.Закрепление.
Беседа с классом.
Слово учителя. Ребята, часто по обращению можно понять, каков тот человек, который обращается, и тот, к кому обращаются. Обращением можно выразить ласку, доброту, заботу говорящего. Очень часто обращение раскрывает героя произведения.
Вспомните отрывки из «Сказки о мертвой царевне и семи богатырях» А.С.Пушкина, где встречаются обращения: «свет мой, зеркальце», «мерзкое стекло».
— С какими словами обращается царевна, Елисей? Как это характеризует их?(ответы детей).
YI. Словарная работа. Объяснить правописание.
Здравствуйте, пожалуйста, до свидания, спасибо, благодарю,
извините.
Ситуация в библиотеке. Составить предложения, с которыми вы обратились к библиотекарю. Используйте обращения и записанные вами вежливые слова.
Итог урока.
1.Что такое обращение? Какова роль в предложении?
2.Как выделяются обращения на письме?
Домашнее задание.
Найдите в сказках А.С.Пушкина примеры с обращениями.
Ответьте на вопрос: кто и при каких обстоятельствах какие формы выбирает? Как это характеризует говорящего?
(PDF) Разбор предложений
220 Джерард Кемпен
Знаменитая неоднозначность основного предложения и сокращенного относительного предложения (MC / RRC)
, приведенная в (7), служит для иллюстрации синтаксических и экстрасинтаксических
факторов, которые считаются управлять ходом процесса синтаксического анализа предложений. Первый элемент
в списке ниже представляет собой сложную систему синтаксической обработки
стратегий, разработанную Фрейзером и ее сотрудниками (см. Frazier & Fodor, 1978;
Frazier & Clifton, 1996).Пункты 2–5 недавно использовались McRae, Spivey-Knowlton и Tanenhaus (в печати) в имитационном исследовании модели
. Я ссылаюсь на
этих публикаций для обсуждения и указателей на вспомогательную экспериментальную литературу
.
1. Принципы парсинга. Одна из ключевых стратегий обработки, предложенная Фрейзером, — это
, называемая минимальным вложением. Пытаясь интегрировать новый ввод в текущее синтаксическое дерево
, процессор сначала предпочитает вложение с наименьшим числом синтаксических узлов
.В рамках грамматического формализма, лежащего в основе модели
Фрейзера, это анализ, в котором неоднозначный глагол (raced, floated) является конечным глаголом
в главном предложении. Еще один важный принцип — позднее закрытие (см. Ниже).
2. Тематическая подгонка. С точки зрения (7d / e) мошенники с большей вероятностью будут играть тематическую роль пациента
в событии ареста, чем роль агента.
3. Относительная морфологическая частота. Некоторые неоднозначные формы глаголов (включая raced
и floated) чаще используются как главные глаголы прошедшего времени, другие — как причастия прошедшего времени
.
4. Частота биграмм. Строка Verb + ed, за которой следует предлог by, поддерживает
пассивную конструкцию RRC.
5. Конфигурационная предвзятость. Первая строка NP + из конечных глаголов в предложении предпочтительно
интерпретируется как открытие основного предложения.
6. Относительная частота структуры аргументов (лексический фрейм). Глаголы типа race и float
чаще используются как непереходные глаголы (без прямого аргумента объекта)
, чем как переходные глаголы (Trueswell, 1996).
7. Ссылочная неоднозначность. Ссылочно неоднозначный контекст дискурса имеет тенденцию смещать
синтаксический анализатор в сторону анализа, который разрешает неоднозначность. Например, анализ RRC
мчащегося мимо сарая или плывущего по реке может помочь определить уникальный референт
для лошади или лодки в контексте нескольких лошадей или лодок
Повторный анализ. Когда синтаксический анализатор обнаруживает информацию, сигнализирующую о том, что текущая строка
была неправильно проанализирована, будет предпринята попытка повторного анализа.Однако очень мало известно о стратегиях диагностики и восстановления парсера
, о динамике процесса ревизии структуры
и о потребляемых им ресурсах (см. Некоторые обсуждения в Mitchell, 1994 и Gorrell,
1995). . Frazier & Rayner (1982) в новаторском исследовании исследовали
Разбор предложения — документация Graphbrain 0.4.4-dev
Преобразование предложения на естественном языке в гиперребро — самая фундаментальная и квинтэссенция задачи, которую можно выполнить с помощью Graphbrain.
Начнем с создания парсера, в данном случае для английского языка:
из импорта graphbrain.parsers *
парсер = create_parser (lang = 'ru')
Инициализация анализатора требует загрузки потенциально больших языковых моделей. Это может занять от нескольких секунд до минуты. Давайте присвоим некоторый текст переменной, в данном случае простое предложение:
text = "Тест Тьюринга, разработанный Аланом Тьюрингом в 1950 году, является тестом машинного интеллекта."
Наконец, давайте проанализируем текст и выведем результат:
parses = парсер.анализировать (текст)
для разбора в парсах:
edge = parse ['main_edge']
печать (edge.to_str ())
Вызов метода parse () для объекта синтаксического анализатора возвращает набор синтаксических анализов — по одному на предложение. Каждый объект синтаксического анализа представляет собой словарь, где main_edge содержит гиперребро, которое непосредственно соответствует предложению. Объекты с гиперребром имеют метод to_str () , который можно использовать для создания строкового представления. Приведенный выше код должен вызвать печать одного гиперребра на экране.
Поэкспериментируйте с изменением текста, который передается объекту синтаксического анализатора, и посмотрите, что произойдет.
Работа с блокнотами
Блокноты
Jupyter — это особенно удобный способ выполнения исследовательских вычислений с помощью Python, который очень популярен для научных приложений. Graphbrain не исключение. Блокнот, соответствующий этому руководству, можно найти здесь:
Обратите внимание, как импортировать служебные функции, которые существуют специально для работы с ноутбуками:
от graphbrain.импорт записной книжки *
Функция show () позволяет лучше визуализировать гиперребры. В приведенном выше примере мы могли бы заменить вызов print () на show (edge) и получить что-то вроде этого:
(is / Pd. sc. | f — 3s- / en (: / J /. (the / Md / en
(+ / B.am /. turing / Cp.s / en test / Cc.s / en ))
(разработан / P.ax. (+ / B.am /. Alan / Cp.s / en turing / Cp.s / en))
Функция show () предоставляет несколько стилей визуализации, а также возможность уменьшения визуального беспорядка за счет отображения только корней атомов. См. Подпись функции для получения всех подробностей.
Утраченное искусство построения диаграмм приговоров
Время от времени мои друзья из Facebook испытывают ностальгию и публикуют культурные артефакты из прошлого нашей когорты.Одним из основных телевизионных продуктов 1970-х годов, который мы вспоминаем с любовью, были обучающие видеоролики, которые показывались в рекламных паузах во время субботних утренних мультфильмов. «Schoolhouse Rock» дебютировал в январе 1973 года на канале ABC. Первый сезон был посвящен обучению детей основам математики. Второй сезон, начавшийся в сентябре того же года, взял на себя проблемы грамматики, сосредоточив большое внимание на синтаксическом анализе предложений. Я признаю, что когда я встречаю определенные слова для частей речи, я все равно слышу тексты.И когда я редактирую текст, эти тексты песен действительно помогли мне в работе. Например, «Междометия показывают возбуждение или эмоции и обычно отделяются от предложения восклицательным знаком или запятой, когда чувство не такое сильное» и «Соединение-соединение: какова ваша функция? Соединение слов, фраз и предложений », настроенных на запоминающиеся мелодии, спасло меня от упорных ошибок. (Хотя не все, как могут утверждать мои редакторы.) Когда два года спустя дебютировал «рок Конституции», он помог мне преуспеть в изучении обществознания в седьмом классе.Я до сих пор помню, что тест просил нас написать слова в преамбуле; Я слышал, как почти все в классе пели эту песню, пока мы писали слова.
Я упоминаю, насколько ценными были эти учебные инструменты, потому что еще один из моих любимых подходов к языку превратился в творческое произведение искусства. Call Me Ishmael — это коллекция открыток, которые иллюстрируют вступительные строки из великих литературных произведений посредством диаграмм предложений. Мне нравились те дни в классе, когда мы составляли схемы предложений.Они запечатлели в вашей памяти, как различные части речи действуют при построении предложений.
Диаграмма предложений — это средство, с помощью которого предложение анализируется и представляется структурой строк, которые устанавливают взаимосвязь между словами в предложении. Возможно, лучший способ представить это как «карту» предложения. В 1847 году Стивен Уоткинс Кларк опубликовал книгу, в которой показал карту предложений в виде серии пузырей. Его визуализация выглядела неэлегантно, и в 1877 году Рид и Келлог изменили пузыри на серию линий.Система Рейда-Келлогга была принята школьными округами по всей стране, и в течение десятилетий после этого школьники обучались части речи с помощью построения диаграмм.
Чтобы продемонстрировать, как составлять схемы предложений, рассмотрим следующие примеры. (Для получения дополнительной информации о построении диаграмм предложений см. Эти указания.)
Начало диаграммы — прямая линия.
Первая цель — установить подлежащее и сказуемое, то есть, кто выполняет действие, и выполняемое действие.Проведите линию между существительным и глаголом, как я сделал с этим простым предложением, состоящим из существительного и глагола.
Серхио Агуэро забивает.
Слева — «Серхио Агуэро». Справа — «баллы».
Глагол to score может действовать как непереходный глагол, которому не нужен объект для выполнения действия, или он может действовать как переходный глагол, где глагол принимает объект, с которым выполняется действие.
Итак, если мы изменим предложение на «Серхио Агуэро забивает голы», его можно представить в виде прямой линии со второй вертикальной линией, помещенной после глагола. Прямой объект стоит на одной строке с существительным и глаголом.
Диаграммы усложняются с добавлением слов, которые изменяют другие слова в предложении. Прилагательные изменяют существительные, поэтому, чтобы указать прилагательное, изменяющее подлежащее, нарисуйте диагональную линию и напишите прилагательное (я) на диагональной линии (ах).
Собственники действуют как прилагательные и обозначаются таким же образом. Со стороны предиката, если прилагательные используются для описания прямого объекта, нарисуйте диагональные линии, чтобы указать эти прилагательные под этой частью диаграммы.
Игрок команды «Манчестер Сити» Серхио Агуэро забивает множество творческих голов.
Здесь «Манчестер Сити» — притяжательное. Прилагательное «блестящий». А «цели» — это прямой объект глагола, который описывается двумя прилагательными «многие» и «творческий».
При построении предложений с прямыми объектами на элемент, с которым выполняется действие, может влиять сам по себе, взаимодействует ли другой человек с этим объектом. Например, «Вы можете сделать подарок своему другу», в котором «подарок» — это прямой объект, который дается «другу», который действует как косвенный объект. Таким образом, глагол «давать» принимает как прямой, так и косвенный объект. Косвенный объект будет показан на диаграмме предложения диагональной линией, отходящей от глагола.
Иногда, однако, это действие может быть изменено с помощью предлога, а не косвенного объекта. Это модификация глагола.Например, при изменении этого предложения обратите внимание на то, что делает предлог:
Блестящий игрок «Манчестер Сити» Серхио Агуэро забивает множество творческих голов против других команд Премьер-лиги.
Здесь предлог «против» изменяет глагол, указывая, что действие совершается с чем-то, но оно оказывает влияние на глагол через то, что называется «предложной фразой».
Чтобы обозначить предложную фразу, напишите диагональную черту от глагола со словом «против».Объект предложной фразы — «команды», а прилагательные, описывающие команды, — это прилагательные «Премьер-лига» и «другие».
Предложения могут также содержать более одного подлежащего или может быть более одного глагола. Я поискал в литературе пример более сложного предложения, которое, я должен признать, потребовало времени, чтобы разбить его, чтобы я понял, как каждое слово функционирует в этом предложении от П.Д. Джеймс Дети мужчин.
Западная наука и западная медицина не подготовили нас к размаху и унижению этой окончательной неудачи.
Здесь есть два предмета — западная наука и западная медицина — и два объекта предлогов, которые сами имеют предложную фразу, изменяющую их. Рассмотрим эту диаграмму того, как я разбирал предложение Джеймса.
Чтобы изобразить это предложение, я использовал пунктирную линию, чтобы обозначить союз — «и» — который соединяет два существительных. За глаголом следует прямое дополнение. Предлогная фраза, которая начинается с предлога «за», имеет двойной объект фразы «величие и унижение».И снова пунктирная линия используется для обозначения соединения. Сама эта предложная фраза видоизменяется предложной фразой «этой окончательной неудачи», которая изображена в виде диагональной линии от двойного объекта.
Предложения могут быть дополнительно усложнены добавлением придаточных предложений, независимых предложений, которые связаны с союзами или пунктуацией, или повествовательными предложениями и множеством других примеров, когда некоторая часть предложения остается невысказанной. И чем сложнее предложение, тем сложнее и красивее диаграмма, отображающая предложение.
Открытки Зови меня Измаил
По Pop Chart Lab
Также доступны с:
Вот почему коллекция открыток Call Me Ishmael , которые содержат вступительные предложения из двадцати четырех великих литературных произведений, являются отличным подарком для любителей языков. Сами предложения почитаются за красоту их построения, выбор слов и ритм, создаваемый при чтении вслух. Рассмотрение их как многослойных диаграмм становится еще одним способом оценить гениев, стоящих за этими словами.
Тщательно разбираем наши слова — CSMonitor.com
В журналистике три точки данных могут составить тренд. Я собираюсь снизить планку здесь: если в одном утреннем выпуске новостей я дважды слышу один и тот же необычный глагол в совершенно разных контекстах, возможно, это стоит отметить.
Это случилось на днях, и глагол parse .В своем первоначальном значении parse , как говорят глаголы, является довольно специализированным, лексическим эквивалентом ножа для рыбы.
Но проверив в Интернете, я обнаружил, что parse отображается в самых разных контекстах.
«Исследователи пытаются понять значение решения секретного режима выпустить в эфир сильно отредактированную версию« Bend It Like Beckham »о молодом футболисте, который оказался между этим видом спорта и ожиданиями ее южноазиатской семьи», — сообщает Los Angeles Times. часовой версии фильма, транслируемой правительством Северной Кореи.
Обозреватель National Journal Элиза Ньюлин Карни недавно написала: «Мы предоставим ученым-конституционистам возможность проанализировать, может ли лидер большинства Гарри Рид, штат Невада, возобновить первый законодательный день в Сенате (который начался 5 января), когда сенаторы снова соберутся 24 января, получив 51 голос «.
Не так давно компания TradingMarkets.com сообщила, что «Motorola Solutions представляет решения нового поколения для розничной торговли». В рассказе о новом портативном компьютере говорится, что он «предлагается с дополнительным бортовым механизмом синтаксического анализа для чтения и анализа штрих-кодов PDF417 на водительских правах в США.
Я сделаю небольшое отступление, чтобы отметить, что двигатель прошел долгий путь с начала XIV века, когда он означал просто «механическое устройство». Сегодняшние «двигатели», скорее всего, будут виртуальными штуковинами, линиями компьютеров. код, в конечном счете. Но синтаксический анализ тоже прошел некоторое расстояние.
Parse восходит к 1550-м годам, когда он означал «изложить части речи в предложении». Среднеанглийский pars , от старофранцузского, было существительным, означающим «часть речи». Следуя схеме, все еще широко распространенной сегодня, pars существительное превратилось в parse глагол.(Если вам не нравится, как я глагол существительное, мы можем поговорить позже.)
Когда студенты 16-го века разбирали предложения, это было в ответ на вопрос, все еще задаваемый на латыни: Quae pars orationis? «Какая часть речи?»
Я никогда не изучал латынь, но я знаю ораторское искусство , когда вижу его. Внезапно задача придирчивого грамматика по анализу предложений и составлению диаграмм оказывается связана с ораторским искусством, и не зря эта базовая классификация слов называется «части речи ».«Цицерон, Цезарь, Марк Антоний, вы слушаете?
В настоящее время буквальный процесс синтаксического анализа оставил нам полезную метафору для анализа, так же как стереотипы, когда-то считавшиеся респектабельной квалифицированной профессией, теперь стали полезным термином для обозначения дурной привычки
Когда наблюдатели из Северной Кореи «разбирают» призыв Пхеньяна к «Бекхэму», они анализируют его. Обозреватель Национального журнала г-жа Карни использовала «синтаксический анализ» аналогичным образом, но контекст подсказывает решение, основанное на классификации: Уловка мистера Рейда либо конституционна, либо нет.
«Его предложения не разбираются». Так коллега успокоил какого-то общественного деятеля, который несколько лет назад вызывал у нас изжогу. Он имел в виду, что этот человек не был слишком умным, но конкретным подтекстом было то, что его публичные высказывания не выдерживали грамматического анализа, не говоря уже о политическом анализе.
Похоже, что английский майор говорит: «Эта собака не будет охотиться». Помните тот? И теперь, когда я размышляю, этот коллега был специалистом по английскому языку. Это разбирает?
Google раздает инструмент, который использует для понимания языка, Parsey McParseface
.
Передайте привет Парси МакПарсфейс.
Да, чтобы заставить вас обратить внимание на то, что в противном случае было бы довольно сложным и занудным, Google использует дань уважения Боути Макбоатфейсу за один из программных инструментов, которые он выпускает сегодня. Но не просто смейтесь (или стоните) над названием, то, что Google дает разработчикам и исследователям, — это большое дело. Сегодня он открывает исходный код того, что он называет SyntaxNet, и компонента для него, мистер МакПарсфейс. Это некоторые из инструментов, которые Google использует для понимания естественного языка, когда вы вводите его в поле или разговариваете с Google Now.
SyntaxNet — это общая структура для синтаксического анализа предложений, называемая «синтаксическим синтаксическим анализатором». Parsey McParseface — это англоязычный плагин для SyntaxNet. Google утверждает, что он может правильно определять предметы, объекты, глаголы и другие грамматические строительные блоки предложений, а также (или, в некоторых случаях, лучше), как обученные лингвисты, достигая 94-процентной точности в новостных статьях на английском языке.
Понимание грамматической структуры предложения — ключ к тому, чтобы помочь компьютеру действовать в соответствии с их значением. В качестве простого примера вы можете сказать: «Дайте мне время в Париже». В зависимости от того, как вы разбираете это предложение, оно может означать «Скажите мне, который час в Париже» или может означать «Когда я буду в Париже, скажите мне, который час». Возможность даже определить, какое из этих значений является предполагаемым, является сверхсложным процессом для компьютера, и он не может даже запуститься, если не сможет проанализировать различные грамматические части предложения.
Чтобы понять это, Google говорит, что «SyntaxNet применяет нейронные сети к проблеме неоднозначности», а затем использует «Поиск луча» для одновременного применения вероятностей к нескольким возможным значениям, прежде чем выбрать правильное значение.
У Google была проблема с открытым исходным кодом со своей платформой машинного обучения TensorFlow. После того, как в прошлом году был открыт исходный код для него, а затем исследователи получили возможность использовать несколько компьютеров, теперь он выпускает другие компоненты, построенные на той же платформе. Google сообщает, что «выпуск включает в себя весь код, необходимый для обучения новых моделей SyntaxNet на ваших собственных данных, а также Parsey McParseface, анализатор английского языка, который мы подготовили для вас и который вы можете использовать для анализа английского текста.«
Лингвистические особенности
· Документация по использованию spaCy
Разумная обработка необработанного текста затруднена: большинство слов встречаются редко, и это
общее для слов, которые выглядят совершенно по-разному, чтобы означать почти одно и то же.
Одни и те же слова в разном порядке могут означать совсем другое.
Даже разделение текста на полезные словесные единицы может быть трудным во многих случаях.
языков. Хотя некоторые проблемы можно решить, начав только с исходных
символов, обычно лучше использовать лингвистические знания, чтобы добавить полезные
Информация.Именно для этого и предназначен spaCy: вы вводите необработанный текст,
и получите объект Doc , который поставляется с различными
аннотации.
После токенизации spaCy может анализировать и тег для данного Doc . Это где
поступает обученный конвейер и его статистические модели, которые позволяют spaCy делает прогнозы, из которых тег или метка наиболее вероятно применимы в данном контексте.
Обученный компонент включает двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку —
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Лингвистические аннотации доступны как Токен атрибутов. Как и многие библиотеки НЛП, spaCy кодирует все строки в хеш-значения , чтобы уменьшить использование памяти и улучшить
эффективность. Итак, чтобы получить удобочитаемое строковое представление атрибута, мы
необходимо добавить подчеркивание _ к его имени:
import spacy
nlp = spacy. load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
печать (токен.текст, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
Текст: Исходный текст слова.
Лемма: Основная форма слова.
POS: Простой UPOS
тег части речи.
Тег: Подробный тег части речи.
Dep: Синтаксическая зависимость, то есть отношение между токенами.
Форма: Форма слова — заглавные буквы, знаки препинания, цифры.
— это альфа: Является ли токен альфа-символом?
is stop: Является ли токен частью стоп-листа, т. Е. Наиболее частыми словами
язык?
Текст
Lemma
POS
Tag
Dep
Shape
alpha
stop
Apple N 70
Apple N 70
Apple N 70
Apple nsubj
Xxxxx
True
Ложь
is
be
AUX
9036 9036 9036 9036 9070
True
внешний вид
внешний вид
VERB
VBG
ROOT
xxx703 903 903 903 False
при
ADP
IN
Prep
xx
True
True
покупка
покупка
VERB 90хх 9036
True
False
U. K.
u.k.
PROPN
NNP
соединение
X.X.
Ложь
Ложь
запуск
запуск
NOUN
NN
dobj
False 9036
для
для
ADP
IN
Prep
xxx
True $
70 9036 9036 9036
$
Quantmod
$
Ложь
Ложь
1
НОМЕР
1
9036 d
Ложь
Ложь
миллиардов
миллиардов
НОМЕР
CD
pobj
xxxx
0 Истинный 9069 теги и ярлыки
Большинство тегов и ярлыков выглядят довольно абстрактно, и они различаются между
языков. spacy.explain покажет вам краткое описание - например, spacy.explain ("VBZ") возвращает "глагол, настоящее время в единственном числе в третьем лице".
Используя встроенный визуализатор дисплея spaCy, вот что
наше примерное предложение и его зависимости выглядят следующим образом:
scheme Схема тега части речи
Для списка назначенных мелкозернистых и крупнозернистых тегов части речи
по моделям spaCy на разных языках, см. задокументированные схемы этикеток
в каталоге моделей.
Флективная морфология - это процесс, с помощью которого корневая форма слова
изменен путем добавления префиксов или суффиксов, определяющих его грамматическую функцию
но не меняйте его часть речи. Мы говорим, что лемма (корневая форма) является наклонен (модифицированный / комбинированный) с одним или несколькими морфологическими признаками от до
создать форму поверхности. Вот несколько примеров:
Контекст
Поверхность
Лемма
POS
Морфологические особенности
Я читал газету
читал
Verorm 70
читал 70
= Ger
Я не смотрю новости, я читаю газету
читаю
читаю
VERB
VerbForm = Fin , Mood = Ind , Tense = Pres
Я прочитал газету вчера
прочитал
прочитал
ГЛАГОЛ
VerbForm = Fin , Mood = Ind , Tense = Прошлое
9000 функций сохранены MorphAnalysis под токеном . морф , который
позволяет получить доступ к индивидуальным морфологическим признакам.
📝 Что стоит попробовать
Измените «Я» на «Она». Вы должны увидеть, что морфологические признаки меняются
и укажите, что это местоимение от третьего лица.
Для языков с относительно простыми морфологическими системами, таких как английский, spaCy
может назначать морфологические признаки с помощью подхода, основанного на правилах, который использует токен текста и мелкозернистые теги части речи для создания
грубые теги части речи и морфологические особенности.
Тегер части речи назначает каждому токену детализированную часть речи
тег . В API эти теги известны как Token.tag . Они выражают
часть речи (например, глагол) и некоторое количество морфологической информации, например
что глагол имеет прошедшее время (например, VBD для глагола прошедшего времени в Penn
Treebank).
Для слов, крупнозернистый POS которых не установлен предыдущим процессом,
таблица сопоставления отображает мелкозернистые теги в
крупнозернистые POS-теги и морфологические особенности.
Лемматизатор — это компонент конвейера, который обеспечивает поиск
и основанные на правилах методы лемматизации в настраиваемом компоненте. Личность
язык может расширить лемматизатор как часть его
языковые данные.
В отличие от spaCy v2, модели spaCy v3 , а не , предоставляют леммы по умолчанию или переключение
автоматически между поиском и леммами на основе правил в зависимости от того,
находится в стадии разработки. Чтобы иметь леммы в Doc , конвейер должен включать Lemmatizer компонент. Компонент лемматизатора
настроен на использование одного режима, такого как «поиск» или «правило» на
инициализация.«Правило» для режима требует, чтобы Token.pos был установлен предыдущим
составная часть.
Данные для лемматизаторов spaCy распространяются в пакете данные-поисковые запросы . В
при условии, что обученные конвейеры уже включают все необходимые таблицы, но если вы
создаете новые конвейеры, вы, вероятно, захотите установить spacy-lookups-data для предоставления данных при инициализации лемматизатора.
Поисковый лемматизатор
Для конвейеров без теггера или морфологизатора можно использовать поисковый лемматизатор.
добавляется в конвейер, пока предоставляется таблица поиска, обычно через данные-поисковые запросы .В
лемматизатор поиска ищет форму поверхности токена в таблице поиска без
ссылка на часть речи или контекст токена.
При обучении конвейеров, которые включают компонент, который назначает часть речи
теги (морфологизатор или теггер с отображением POS),
лемматизатор на основе правил может быть добавлен с помощью таблиц правил из данные пространственного поиска :
Детерминированный лемматизатор, основанный на правилах, отображает форму поверхности в лемму в
свет заданной ранее крупнозернистой части речи и морфологического
информация, не обращаясь к контексту токена. Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
приобретен из WordNet.
spaCy имеет быстрый и точный синтаксический анализатор зависимостей, а также богатый набор функций.
API для навигации по дереву.Синтаксический анализатор также поддерживает границу предложения
обнаружение и позволяет вам перебирать базовые словосочетания с существительными или «фрагменты». Ты можешь
проверьте, был ли проанализирован объект Doc путем вызова doc.has_annotation ("DEP") , который проверяет, имеет ли атрибут Token.dep установлено, возвращает логическое значение. Если результат Ложь , предложение по умолчанию
итератор вызовет исключение.
📖Схема меток зависимостей
Для списка меток синтаксических зависимостей, назначенных моделями spaCy в
разных языках, см. схемы этикеток, задокументированные в
каталог моделей.
Отрезки существительных
Отрезки существительных — это «базовые словосочетания» — плоские фразы, в которых есть существительное в качестве своего
глава. Вы можете представить себе существительное как существительное плюс слова, описывающие существительное.
— например, «пышная зеленая трава» или «крупнейший в мире технологический фонд». К
получить куски существительного в документе, просто перебрать Док. Имя_пункты .
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
для куска в док.noun_chunks:
print (chunk.text, chunk.root.text, chunk.root.dep_,
chunk.root.head.text)
Текст: Исходный текст фрагмента существительного.
Корневой текст: Исходный текст слова, соединяющего кусок существительного с
остальная часть синтаксического анализа.
Root dep: Отношение зависимости, соединяющее корень с его головкой.
Текст заголовка корневого токена: Текст заголовка корневого токена.
Текст
корень.text
root.dep_
root.head.text
Автономные автомобили
легковые автомобили
nsubj
shift
страхование ответственности
doh10370
производители
производители
pobj
к
Навигация по дереву синтаксического анализа
spaCy использует термины head и child для описания слов , связанных
единственная дуга в дереве зависимостей.Термин dep используется для дуги
метка, которая описывает тип синтаксического отношения, которое связывает ребенка с
голова. Как и в случае с другими атрибутами, значение .dep является хеш-значением. Ты можешь
получить строковое значение с .dep_ .
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
для токена в документе:
print (token.text, token.dep_, token.head.text, token.head.pos_,
[ребенок для ребенка в жетоне.дети])
Текст: Исходный текст токена.
Dep: Синтаксическое отношение, связывающее дочерний элемент с головой.
Текст заголовка: Исходный текст токена головы.
Head POS: Тег части речи токен-головки.
Потомки: Непосредственные синтаксические зависимости токена.
Текст
Dep
Головной текст
Головной POS
Детский
Автономный
amod
автомобили 70
nsubj
сдвиг
VERB
Автономный
сдвиг
ROOT
сдвиг
VERB
9036 ответственность
NOUN
ответственность
dobj
shift
VERB
страхование
к
70
производителей
pobj
к
ADP
Поскольку синтаксические отношения образуют дерево, каждое слово имеет ровно одно
голова . Таким образом, вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ сопоставить дугу
проценты - снизу:
импорт прост.
из spacy.symbols import nsubj, VERB
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
глаголы = набор ()
для possible_subject в документе:
if possible_subject.dep == nsubj и possible_subject.head.pos == ГЛАГОЛ:
verbs.add (possible_subject.глава)
печать (глаголы)
Если вы попытаетесь найти соответствие сверху, вам придется повторить итерацию дважды. Один раз за голову,
а потом снова через детей:
глаголы = []
для possible_verb в документе:
если возможно_verb.pos == ГЛАГОЛ:
для possible_subject в possible_verb.children:
если возможно_subject.dep == nsubj:
verbs.append (возможно_глагол)
перерыв
Для перебора дочерних элементов используйте атрибут token. children , который
предоставляет последовательность объектов Token .
Итерация по локальному дереву
Есть еще несколько удобных атрибутов для итерации по локальному дереву.
дерево из жетона. Token.lefts and Token.rights Атрибуты обеспечивают последовательности синтаксических
дочерние элементы, которые появляются до и после токена. Обе последовательности в предложении
заказывать. Также есть два целочисленных атрибута: Token.n_lefts и Token.n_rights , дающий количество левых и правых
дети.
импорт прост.
nlp = простор.load ("en_core_web_sm")
doc = nlp («ярко-красные яблоки на дереве»)
print ([token.text для токена в doc [2] .lefts])
print ([token.text для токена в doc [2] .rights])
печать (документ [2] .n_lefts)
печать (документ [2] .n_rights)
импорт просторный
nlp = spacy.load ("de_core_news_sm")
doc = nlp ("schöne rote Äpfel auf dem Baum")
print ([token.text для токена в doc [2] .lefts])
print ([token.text для токена в doc [2] .rights])
Вы можете получить целую фразу по ее синтаксическому заголовку, используя Жетон.атрибут поддерева . Это возвращает заказанный
последовательность жетонов. Вы можете подняться на дерево с помощью Token.ancestors атрибут, и проверьте доминирование с помощью Token.is_ancestor
Проективное и непроективное
Для английских конвейеров по умолчанию дерево синтаксического анализа выглядит следующим образом: проективный , что означает отсутствие перекрестных скобок. Жетоны
возвращенный . поддерево , следовательно, гарантированно будет непрерывным. Это не
верно для немецких трубопроводов, у которых много
непроективные зависимости.
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Владельцы кредитных и ипотечных счетов должны подавать свои запросы»)
root = [токен для токена в документе if token.head == токен] [0]
subject = list (root.lefts) [0]
для потомка в subject.subtree:
утверждать, что субъект является потомком или субъектом. is_ancestor (потомок)
print (Потомок.текст, Потомок.dep_, Потомок.n_lefts,
Потомок.n_rights,
[ancestor.text для предка в потомке .ancestors])
Текст
Dep
n_lefts
n_rights
предки
Credit
nmod 9036
и
куб.
счет
конъюнктура
1
0
Кредит, держатели, представить
держатели
9036 9036 70
9036
Наконец, .Атрибуты left_edge и .right_edge могут быть особенно полезны,
потому что они дают вам первый и последний токены поддерева. Это
Самый простой способ создать объект Span для синтаксической фразы. Обратите внимание, что .right_edge дает токен внутри поддерева - поэтому, если вы используете его как
конечная точка диапазона, не забудьте +1 !
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Владельцы кредитных и ипотечных счетов должны подавать свои запросы»)
span = doc [doc [4].left_edge.i: документ [4] .right_edge.i + 1]
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (диапазон)
для токена в документе:
print (token.text, token.pos_, token.dep_, token.head.text)
Текст
POS
Dep
Head text
Владельцы кредитных и ипотечных счетов
NOUN
должны представить
nsub370j 9036 9036 9036
aux
представить
отправить
VERB
ROOT
представить
0
NOUN
dobj
submit
Анализ зависимостей может быть полезным инструментом для извлечения информации ,
особенно в сочетании с другими прогнозами, такими как
названные объекты.В следующем примере извлекаются деньги и
значения валюты, то есть сущности, помеченные как ДЕНЬГИ , а затем использует зависимость
выполните синтаксический анализ, чтобы найти именную фразу, к которой они относятся - например, «Чистая прибыль» → «9,4 миллиона долларов» .
импорт прост.
nlp = spacy.load ("en_core_web_sm")
nlp.add_pipe ("merge_entities")
nlp.add_pipe ("merge_noun_chunks")
ТЕКСТЫ = [
«Чистая прибыль составила 9,4 миллиона долларов по сравнению с 2,7 миллиона долларов в предыдущем году»,
«Выручка превысила двенадцать миллиардов долларов, а убыток составил 1 миллиард долларов.",
]
для документа в nlp.pipe (ТЕКСТЫ):
для токена в документе:
если token.ent_type_ == "ДЕНЬГИ":
если token.dep_ in ("attr", "dobj"):
subj = [w вместо w в token.head.lefts, если w.dep_ == "nsubj"]
если subj:
print (subj [0], "->", токен)
elif token.dep_ == "pobj" и token.head.dep_ == "Prep":
print (token.head.head, "->", токен)
📖Комбинирование моделей и правил
Дополнительные примеры того, как написать логику извлечения информации на основе правил, которая
использует прогнозы модели, сделанные различными компонентами,
см. руководство по использованию на
совмещение моделей и правил.
Визуализация зависимостей
Лучший способ понять анализатор зависимостей spaCy - интерактивный. Делать
это проще, spaCy поставляется с модулем визуализации. Вы можете сдать Doc или
список объектов Doc для отображения и запуска displacy.serve для запуска веб-сервера или displacy.render для создания необработанной разметки.
Если вы хотите знать, как писать правила, которые подключаются к синтаксису
конструкции, просто вставьте предложение в визуализатор и посмотрите, как spaCy
аннотирует это.
Подробнее и примеры см.
руководство по визуализации spaCy. Вы также можете протестировать
Отображение в нашей онлайн-демонстрации.
Отключение парсера
В обученных конвейерах, предоставляемых spaCy, парсер загружается и
включен по умолчанию как часть
стандартный технологический конвейер.Если тебе не нужно
любую синтаксическую информацию следует отключить парсер. Отключение
парсер заставит spaCy загружаться и работать намного быстрее. Если вы хотите загрузить парсер,
но необходимо отключить его для определенных документов, вы также можете контролировать его использование на
объект нлп . Для получения дополнительной информации см. Руководство по использованию на
отключение компонентов конвейера.
spaCy имеет чрезвычайно быструю систему распознавания статистических объектов, которая
назначает метки смежным участкам токенов.По умолчанию
обученные конвейеры могут идентифицировать множество именованных и числовых
юридические лица, включая компании, местоположения, организации и продукты. Ты можешь
добавить произвольные классы в систему распознавания сущностей и обновить модель
с новыми примерами.
Распознавание именованных объектов 101
Именованные объекты - это «объекты реального мира», которым присвоено имя, например
человек, страна, продукт или название книги. spaCy может распознавать различные
типы именованных сущностей в документе, запрашивая модель для
предсказание .Поскольку модели являются статистическими и сильно зависят от
примеры, на которых они обучались, это не всегда работает идеально и может
потребуются некоторые настройки позже, в зависимости от вашего варианта использования.
Именованные сущности доступны как свойство ents в Doc :
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для Ent в док. центрах:
print (ent.text, ent.start_char, ent.end_char, ent.label_)
Текст: Исходный текст объекта.
Начало: Индекс начала объекта в Doc .
End: Указатель конца объекта в Doc .
Метка: Метка объекта, т.е. тип.
Текст
Начало
Конец
Этикетка
Описание
Apple
0
5
ORG
Компании, учреждения, учреждения.
Великобритания
27
31
GPE
Геополитическое образование, то есть страны, города, государства.
1 миллиард долларов
44
54
ДЕНЬГИ
Денежное выражение, включая ед.
Используя встроенный визуализатор дисплея spaCy, вот что
Наш примерное предложение и его именованные сущности выглядят так:
Доступ к аннотациям и меткам сущностей
Стандартный способ доступа к аннотациям сущностей - это doc.энц Свойство, которое создает последовательность из Span объектов. Лицо
Тип доступен либо как хеш-значение, либо как строка с использованием атрибутов ent.label и ent.label_ . Объект Span действует как последовательность токенов, поэтому
вы можете перебирать объект или индексировать его. Вы также можете получить текстовую форму
целого объекта, как если бы это был один токен.
Вы также можете получить доступ к аннотациям объекта токена, используя жетон.ent_iob и token.ent_type атрибутов. token.ent_iob указывает
независимо от того, начинается ли объект, продолжается или заканчивается на теге. Если тип объекта не установлен
на токене он вернет пустую строку.
Схема IOB
I - Токен внутри объекта.
O - Токен - это за пределами объекта.
B - Токен - это начало объекта.
Схема BILUO
B - Токен - это начало мульти-токен-объекта.
I - Токен внутри мульти-токен-объекта.
L - Токен - это последний токен для объекта с несколькими токенами.
U - Токен представляет собой единицу с одним токеном, объект .
O - Toke - это за пределами объекта.
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Сан-Франциско рассматривает вопрос о запрете роботов для доставки тротуаров")
ents = [(e.text, e.start_char, e.end_char, e.label_) для e в документах]
печать (энц)
ent_san = [doc [0] .text, doc [0] .ent_iob_, doc [0] .ent_type_]
ent_francisco = [документ [1] .text, doc [1] .ent_iob_, doc [1] .ent_type_]
печать (ent_san)
печать (ent_francisco)
Текст
ent_iob
ent_iob_
ent_type_
Описание
San
San
3
GP
Франциско
1
I
«GPE»
внутри организации
считает
2
0 70 организация
запрещающая
2
O
""
вне организации
тротуар
2 70
2 70 9036
вне организации
доставка
2 903 70
O
""
вне объекта
роботов
2
O
"" 365
Чтобы гарантировать, что последовательность аннотаций токенов остается неизменной, вы должны
установить аннотации сущностей на уровне документа .Однако вы не можете писать
непосредственно к атрибутам token.ent_iob или token.ent_type , поэтому самый простой
способ установки сущностей - использовать функцию doc.set_ents и создайте новый объект как Span .
импорт прост.
из spacy.tokens import Span
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("fb нанимает нового вице-президента по глобальной политике")
ents = [(e.text, e.start_char, e.end_char, e.label_) для e в документах]
print ('До', энц)
fb_ent = Span (doc, 0, 1, label = "ORG")
orig_ents = список (док.энц)
doc.set_ents ([fb_ent], по умолчанию = "без изменений")
doc.ents = orig_ents + [fb_ent]
ents = [(e.text, e.start, e.end, e.label_) для e в документах]
print ('После', энц)
Имейте в виду, что Span инициализируется начальным и конечным токенами индексы, а не смещения символов. Чтобы создать диапазон из смещений символов, используйте Doc.char_span :
fb_ent = doc.char_span (0, 2, label = "ORG")
Установка аннотаций сущностей из массива
Вы также можете назначить аннотации сущностей с помощью док.from_array метод. Для этого следует включить
атрибуты ENT_TYPE и ENT_IOB в массиве, который вы импортируете
из.
импортный номер
импортный простор
из spacy.attrs импортировать ENT_IOB, ENT_TYPE
nlp = spacy.load ("en_core_web_sm")
doc = nlp.make_doc («Лондон - большой город в Великобритании.»)
print («До», док.)
заголовок = [ENT_IOB, ENT_TYPE]
attr_array = numpy.zeros ((len (документ), len (заголовок)), dtype = "uint64")
attr_array [0, 0] = 3
attr_array [0, 1] = док.voiceab.strings ["GPE"]
doc.from_array (заголовок, attr_array)
print ("После", док.)
Установка аннотаций сущностей в Cython
Наконец, вы всегда можете записать в базовую структуру, если скомпилируете
Функция Cython. Это легко сделать и позволяет
писать эффективный нативный код.
из spacy.typedefs cimport attr_t
из spacy.tokens.doc cimport Doc
cpdef set_entity (документ doc, int start, int end, attr_t ent_type):
для i в диапазоне (начало, конец):
док.c [i] .ent_type = ent_type
doc.c [начало] .ent_iob = 3
для i в диапазоне (начало + 1, конец):
doc.c [i] .ent_iob = 2
Очевидно, если вы напишете непосредственно в массив структур TokenC * , у вас будет
ответственность за обеспечение согласованного состояния данных.
Встроенные типы сущностей
Совет. Общие сведения о типах сущностей
Вы также можете использовать spacy.explain () для получения описания строки
представление метки объекта.Например, spacy.explain ("ЯЗЫК") вернет «любой названный язык».
Схема аннотаций
Подробнее о типах сущностей, доступных в обученных конвейерах spaCy, см.
«Схема маркировки» отдельных моделей в
каталог моделей.
Визуализация именованных сущностей
дисплей визуализатор ENT позволяет интерактивно исследовать поведение модели распознавания сущностей. Если ты
При обучении модели очень полезно запускать визуализацию самостоятельно.Помогать
вы делаете это, spaCy поставляется с модулем визуализации. Вы можете сдать Doc или
список объектов Doc для отображения и запуска displacy.serve для запуска веб-сервера или displacy.render для создания необработанной разметки.
Подробнее и примеры см.
руководство по визуализации spaCy.
Пример именованного объекта
import spacy
от просторного импорта
text = "Когда Себастьян Трун в 2007 году начал работать над беспилотными автомобилями в Google, мало кто из других людей воспринимал его всерьез."
nlp = spacy.load ("en_core_web_sm")
doc = nlp (текст)
displacy.serve (док,)
Для заземления названных сущностей в «реальном мире» spaCy предоставляет функциональные возможности
для выполнения привязки сущностей, которая разрешает текстовую сущность в уникальную
идентификатор из базы знаний (КБ). Вы можете создать свой собственный KnowledgeBase и обучите нового EntityLinker с использованием этой настраиваемой базы знаний.
Доступ к идентификаторам объектов Требуется модель
Аннотированный идентификатор базы знаний доступен либо в виде хеш-значения, либо в виде строки,
используя атрибуты ent.kb_id и ent.kb_id_ из Span объект или атрибуты ent_kb_id и ent_kb_id_ Токен объект.
Токенизация - это задача разбиения текста на значимые сегменты, называемые жетонов . Входными данными токенизатора является текст в Юникоде, а на выходе - Объект Doc . Чтобы построить объект Doc , вам понадобится Экземпляр Vocab , последовательность из слов строк и, необязательно,
последовательность пробелов логических значений, которые позволяют поддерживать выравнивание
токены в исходную строку.
Важное примечание
Токенизация
spaCy - это неразрушающий , что означает, что вы всегда будете
может восстановить исходный ввод из токенизированного вывода. Пробел
информация сохраняется в токенах, и никакая информация не добавляется и не удаляется
во время токенизации. Это своего рода основной принцип объекта spaCy Doc : doc.text == input_text всегда должен выполняться.
Во время обработки spaCy first токенизирует текст, т.е.е. сегментирует его на
слова, знаки препинания и так далее. Это делается путем применения правил, специфичных для каждого
язык. Например, знаки препинания в конце предложения следует разделять.
- тогда как «Великобритания» должен остаться один жетон. Каждый Doc состоит из отдельных
токены, и мы можем перебирать их:
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
печать (токен.текст)
0
1
2
3
4
5
6
7
8
9
10
39052
3
10
9052
на
покупка
U.K.
запуск
для
$
1
млрд
Сначала необработанный текст разбивается на пробельные символы, аналогично text.split ('') . Затем токенизатор обрабатывает текст слева направо. На
для каждой подстроки выполняется две проверки:
Соответствует ли подстрока правилу исключения токенизатора? Например, «не надо»
не содержит пробелов, но должен быть разделен на два токена: «do» и
«Нет», а «У.К. » всегда должен оставаться один токен.
Можно ли отделить префикс, суффикс или инфикс? Например, знаки препинания
запятые, точки, дефисы или кавычки.
Если есть совпадение, правило применяется, и токенизатор продолжает цикл,
начиная с недавно разделенных подстрок. Таким образом, spaCy может разделить комплекс ,
вложенные токены , такие как комбинации сокращений и множественных знаков препинания
Метки.
Исключение токенизатора: Особое правило для разделения строки на несколько
токены или предотвратить разделение токена, когда правила пунктуации
применяемый.
Префикс: Знак (и) в начале, например $ , (, “, ¿.
Суффикс: символов в конце, например, км , ) , ” , ! .
Хотя правила пунктуации обычно довольно общие, исключения токенизатора
сильно зависят от специфики конкретного языка.Вот почему каждый
доступный язык имеет собственный подкласс, например Английский или Немецкий , который загружается в списки жестко закодированных данных и исключений
правила.
Подробности алгоритма: как работает токенизатор spaCy¶
spaCy представляет новый алгоритм токенизации, который обеспечивает лучший баланс
между производительностью, простотой определения и легкостью совмещения с оригиналом
нить.
После использования префикса или суффикса мы снова обращаемся к особым случаям. Мы хотим
особые случаи, чтобы обрабатывать такие вещи, как "не" на английском языке, и мы хотим того же
Правило работать на «(не)!».Мы делаем это, отделяя открытую скобку, затем
восклицательный знак, затем закрытая скобка и, наконец, соответствующий особый случай.
Вот реализация алгоритма на Python, оптимизированная для удобочитаемости.
а не производительность:
def tokenizer_pseudo_code (
текст,
Особые случаи,
prefix_search,
суффикс_поиск,
infix_finditer,
token_match,
url_match
):
токены = []
для подстроки в text.split ():
суффиксы = []
пока подстрока:
в то время как prefix_search (подстрока) или suffix_search (подстрока):
если token_match (подстрока):
жетоны.добавить (подстрока)
substring = ""
перерыв
если подстрока в special_cases:
tokens.extend (special_cases [подстрока])
substring = ""
перерыв
если prefix_search (подстрока):
split = prefix_search (подстрока) .end ()
tokens.append (подстрока [: split])
подстрока = подстрока [разделить:]
если подстрока в special_cases:
Продолжать
если суффикс_поиск (подстрока):
split = суффикс_поиск (подстрока).Начало()
суффиксы.append (подстрока [разделить:])
подстрока = подстрока [: разделение]
если token_match (подстрока):
tokens.append (подстрока)
substring = ""
elif url_match (подстрока):
tokens.append (подстрока)
substring = ""
Подстрока elif в special_cases:
tokens.extend (special_cases [подстрока])
substring = ""
список elif (infix_finditer (подстрока)):
infixes = infix_finditer (подстрока)
смещение = 0
для соответствия в инфиксах:
жетоны.добавить (подстрока [смещение: match.start ()])
tokens.append (подстрока [match.start (): match.end ()])
смещение = match.end ()
если подстрока [смещение:]:
tokens.append (подстрока [смещение:])
substring = ""
Подстрока elif:
tokens.append (подстрока)
substring = ""
tokens.extend (в обратном порядке (суффиксы))
для совпадения в сопоставлении (special_cases, text):
tokens.replace (совпадение, особые_случаи [совпадение])
вернуть жетоны
Алгоритм можно резюмировать следующим образом:
Итерация по подстрокам, разделенным пробелами.
Найдите совпадение. Если есть совпадение, остановите обработку и оставьте это
токен.
Проверьте, есть ли у нас явно определенный особый случай для этой подстроки.
Если да, используйте это.
В противном случае попробуйте использовать один префикс. Если мы использовали префикс, вернитесь к # 2,
так что совпадение токенов и особые случаи всегда имеют приоритет.
Если мы не использовали префикс, попробуйте использовать суффикс, а затем вернитесь к
№2.
Если мы не можем использовать префикс или суффикс, ищите соответствие URL.
Если URL-адреса не совпадают, обратите внимание на особый случай.
Найдите «инфиксы» - например, дефисы и т. Д. И разделите подстроку на
токены на всех инфиксах.
Как только мы больше не сможем потреблять строку, обрабатываем ее как отдельный токен.
Сделайте последний проход по тексту, чтобы проверить наличие особых случаев, которые включают
пробелы или пропущенные из-за дополнительной обработки аффиксов.
Global и , зависящие от языка данные токенизатора предоставляются через язык
данные в spacy / lang .Исключения токенизатора
определите особые случаи, такие как «не» в английском языке, который нужно разделить на два
tokens: {ORTH: "do"} и {ORTH: "n't", NORM: "not"} . Приставки, суффиксы
а инфиксы в основном определяют правила пунктуации - например, когда нужно отделить
периоды (в конце предложения) и когда оставлять маркеры, содержащие точки
неповрежденные (сокращения, например, «США»).
Следует ли мне изменить языковые данные или добавить собственные правила токенизатора? ¶
Правила токенизации, которые относятся к одному языку, но могут быть обобщены
через этот язык , в идеале должны жить в языковых данных в spacy / lang - мы всегда ценим запросы на включение!
Все, что относится к домену или типу текста, например финансовая торговля.
аббревиатуры или баварский молодежный сленг - следует добавлять в качестве особого правила
к вашему экземпляру токенизатора.Если вы имеете дело с большим количеством настроек, это
может иметь смысл создать полностью настраиваемый подкласс.
Добавление особых правил токенизации
Большинство доменов имеют по крайней мере некоторые особенности, требующие индивидуальной токенизации
правила. Это могут быть очень определенные выражения или сокращения, используемые только в
это конкретное поле. Вот как добавить правило особого случая к существующему Tokenizer instance:
import spacy
из spacy.symbols import ORTH
nlp = простор.load ("en_core_web_sm")
doc = nlp ("дай мне это")
print ([w.text для w в документе])
special_case = [{ORTH: "gim"}, {ORTH: "me"}]
nlp.tokenizer.add_special_case ("дай мне", специальный_кейс)
print ([w.text для w в nlp ("дай мне это")])
Особый случай не обязательно должен соответствовать всей подстроке, разделенной пробелами.
Токенизатор будет постепенно отделять знаки препинания и продолжать поиск
оставшаяся подстрока. Правила особого случая также имеют приоритет перед
разделение знаков препинания.
assert "gimme" not in [w.text for w in nlp ("gimme!")]
assert "gimme" not in [w.text for w in nlp ('("... дай мне ...?")')]
nlp.tokenizer.add_special_case ("... дай мне ...?", [{"ORTH": "... дай мне ...?"}])
assert len (nlp ("... дай ...?")) == 1
Отладка токенизатора
Рабочая реализация приведенного выше псевдокода доступна для отладки как nlp.tokenizer.explain (текст) . Он возвращает список
кортежи, показывающие, какое правило или шаблон токенизатора было сопоставлено для каждого токена.В
произведенные токены идентичны nlp.tokenizer () , за исключением пробельных токенов:
Ожидаемый результат
"ПРЕФИКС
Пусть СПЕЦИАЛЬНЫЙ-1
СПЕЦИАЛЬНЫЙ-2
перейти ТОКЕН
! СУФФИКС
"СУФФИКС
from spacy.lang.en импорт английский
nlp = английский ()
text = '' '"Поехали!"' ''
doc = nlp (текст)
tok_exp = nlp.tokenizer.explain (текст)
assert [t.text для t в документе, если не t.is_space] == [t [1] для t в tok_exp]
для t в tok_exp:
print (t [1], "\ t", t [0])
Настройка класса токенизатора spaCy
Предположим, вы хотели создать токенизатор для нового языка или определенного
домен.Вам может потребоваться определить шесть вещей:
Словарь особых случаев . Это обрабатывает такие вещи, как схватки,
единицы измерения, смайлики, некоторые сокращения и т. д.
Функция prefix_search для обработки предшествующих знаков препинания , таких как открытая
кавычки, открытые скобки и т. д.
Функция suffix_search для обработки следующих знаков препинания , например
запятые, точки, закрывающие кавычки и т. д.
Функция infix_finditer для обработки непробельных разделителей, таких как
дефисы и т. д.
Необязательная логическая функция token_match соответствующие строки, которые никогда не должны
быть разделенным, переопределив правила инфиксов. Полезно для таких вещей, как числа.
Необязательная логическая функция url_match , аналогичная token_match за исключением того, что префиксы и суффиксы удаляются перед применением соответствия.
Обычно не требуется создавать подкласс Tokenizer . Стандартное использование
использовать re.compile () для создания объекта регулярного выражения и передать его .https?: // '' ') def custom_tokenizer (nlp):
вернуть Tokenizer (nlp.vocab, rules = special_cases,
prefix_search = prefix_re.search,
суффикс_поиск = суффикс_ре.поиск,
infix_finditer = infix_re.finditer,
url_match = simple_url_re.match) nlp = spacy.load ("en_core_web_sm")
nlp.tokenizer = custom_tokenizer (nlp)
doc = nlp ("привет-мир. :)")
print ([t.text для t в документе])
Если вместо этого вам нужно создать подкласс токенизатора, соответствующие методы
specialize - это find_prefix , find_suffix и find_infix .
Важное примечание
При настройке обработки префиксов, суффиксов и инфиксов помните, что вы
передача функций для выполнения spaCy, например prefix_re. .Точно так же суффиксные правила должны
применяется только к концу токена , поэтому ваше выражение должно заканчиваться $ .
Изменение существующих наборов правил
Во многих ситуациях вам не обязательно нужны полностью настраиваемые правила. Иногда
вы просто хотите добавить еще один символ к префиксам, суффиксам или инфиксам. В
правила префикса, суффикса и инфикса по умолчанию доступны через объект nlp По умолчанию и атрибуты токенизатора , такие как Токенизатор.суффикс_поиск доступны для записи, поэтому вы можете
перезаписать их скомпилированными объектами регулярного выражения, используя измененное значение по умолчанию
правила. spaCy поставляется с служебными функциями, которые помогут вам скомпилировать обычный
выражения - например, compile_suffix_regex :
Атрибут Tokenizer.suffix_search должен быть функцией, которая принимает
строка Unicode и возвращает объект соответствия регулярному выражению или Нет . Обычно мы используем
атрибут .search скомпилированного объекта регулярного выражения, но вы можете использовать и другие
функция, которая ведет себя так же.
Важное примечание
Если вы загрузили обученный конвейер, запись в нлп.Значения по умолчанию или на английском языке. Значения по умолчанию напрямую не используются.
работают, поскольку регулярные выражения считываются из данных конвейера и будут
компилируется при загрузке. Если вы измените nlp.Defaults , вы увидите только
эффект, если вы позвоните spacy.blank . Если вы хотите
изменить токенизатор, загруженный из обученного конвейера, вы должны изменить nlp.tokenizer напрямую. Если вы тренируете собственный конвейер, вы можете зарегистрироваться
обратные вызовы для изменения nlp объект перед тренировкой.
Наборы правил для префиксов, инфиксов и суффиксов включают не только отдельные символы
но также подробные регулярные выражения, которые принимают окружающий контекст в
учетная запись. Например, существует регулярное выражение, которое обрабатывает дефис между
буквы как инфикс. Если вы не хотите, чтобы токенизатор разбивался на дефисы
между буквами, вы можете изменить существующее определение инфикса из lang / punctuation.py :
import spacy
из spacy.lang.char_classes импортировать ALPHA, ALPHA_LOWER, ALPHA_UPPER
от простора.] (? = [0-9-]) ",
r "(? <= [{al} {q}]) \. (? = [{au} {q}]]". format (
al = ALPHA_LOWER, au = ALPHA_UPPER, q = CONCAT_QUOTES
),
r "(? <= [{a}]), (? = [{a}])". format (a = ALPHA),
r "(? <= [{a} 0-9]) [: <> = /] (? = [{a}])". format (a = ALPHA),
]
)
infix_re = compile_infix_regex (инфиксы)
nlp.tokenizer.infix_finditer = infix_re.finditer
doc = nlp ("свекровь")
print ([t.text для t в документе])
Обзор регулярных выражений по умолчанию см. языков / знаков препинания.py и
специфичные для языка определения, такие как lang / de / punctuation.py для
Немецкий.
Подключение настраиваемого токенизатора к конвейеру
Токенизатор является первым и единственным компонентом конвейера обработки.
это не может быть заменено записью на nlp.pipeline . Это потому, что у него
отличная подпись от всех других компонентов: он принимает текст и возвращает Doc , тогда как все остальные компоненты ожидают уже
токенизированные Doc .
Чтобы перезаписать существующий токенизатор, вам необходимо заменить nlp.tokenizer на
настраиваемая функция, которая принимает текст и возвращает Doc .
Создание документа Doc
Для создания объекта Doc вручную требуется не менее двух
аргументы: общий Vocab и список слов. По желанию вы можете пройти
список из пробелов значений, указывающих, является ли токен в этой позиции
с последующим пробелом (по умолчанию True ).См. Раздел о
предварительно токенизированный текст для получения дополнительной информации.
Вот пример самого простого токенизатора пробелов.Требуется общий
Dictionary, поэтому он может создавать объекты Doc . Когда он вызывает текст, он возвращает
объект Doc , состоящий из текста, разделенного на одиночные пробелы. Мы можем
затем перезапишите атрибут nlp.tokenizer экземпляром нашего настраиваемого
токенизатор.
импорт прост.
из spacy.tokens import Doc
класс WhitespaceTokenizer:
def __init __ (я, словарь):
self.vocab = словарный запас
def __call __ (сам, текст):
слова = текст.расколоть(" ")
вернуть документ (self.vocab, words = words)
nlp = spacy.blank ("ru")
nlp.tokenizer = WhitespaceTokenizer (nlp.vocab)
doc = nlp («Что со мной случилось? подумал он. Это был не сон.»)
print ([token.text для токена в документе])
Пример 2: Сторонние токенизаторы (части слова BERT)
Вы можете использовать тот же подход для подключения любых других сторонних токенизаторов. Ваш
custom callable просто нужно вернуть объект Doc с токенами, созданными
ваш токенизатор.В этом примере оболочка использует слово BERT.
токенизатор , предоставляемый токенизаторов библиотека. Жетоны
доступный в объекте Doc , возвращенном spaCy, теперь соответствует точным частям слова
производится токенизатором.
💡 Совет: spacy-transformers
Если вы работаете с моделями трансформаторов, такими как BERT, ознакомьтесь с пространственно-трансформеры пакет расширений и документация. Это
включает компонент конвейера для использования предварительно обученных грузов трансформатора и
Тренировочный трансформатор модели в spaCy, а также полезные утилиты для
согласование частей слова с лингвистической лексикой.
Custom BERT word piece tokenizer
from tokenizers import BertWordPieceTokenizer
из spacy.tokens import Doc
импортный простор
класс BertTokenizer:
def __init __ (я, словарь, файл словаря, нижний регистр = Истина):
self.vocab = словарный запас
self._tokenizer = BertWordPieceTokenizer (файл словаря, нижний регистр = нижний регистр)
def __call __ (сам, текст):
tokens = self._tokenizer.encode (текст)
слова = []
пробелы = []
для i, (текст, (начало, конец)) в перечислении (zip (tokens.токены, токены. смещения)):
words.append (текст)
если i конец)
еще:
space.append (Истина)
вернуть документ (self.vocab, слова = слова, пробелы = пробелы)
nlp = spacy.blank ("ru")
nlp.tokenizer = BertTokenizer (nlp.vocab, "bert-base-uncased-vocab.txt")
doc = nlp ("Джастин Дрю Бибер - канадский певец, автор песен и актер.")
print (doc.text, [token.text для токена в документе])
Важное примечание о токенизации и моделях
Имейте в виду, что результаты ваших моделей могут быть менее точными, если токенизация
во время обучения отличается от токенизации во время выполнения. Итак, если вы измените
после токенизации обученного конвейера, это может привести к очень разным
предсказания. Поэтому вы должны тренировать свой конвейер с таким же
tokenizer будет использоваться во время выполнения. См. Документацию на
обучение с настраиваемой токенизацией для получения подробной информации.
Обучение с пользовательской токенизацией v3.0
Конфигурация обучения
spaCy описывает настройки,
гиперпараметры, конвейер и токенизатор, используемые для построения и обучения
трубопровод. Блок [nlp.tokenizer] относится к зарегистрированной функции , которая
принимает объект nlp и возвращает токенизатор. Здесь мы регистрируем
функция называется whitespace_tokenizer в @tokenizers реестр. Чтобы убедиться, что spaCy умеет
построить свой токенизатор во время обучения, вы можете передать свой файл Python с помощью
установка - код функции.py при запуске spacy train .
@ spacy.registry.tokenizers ("whitespace_tokenizer") def create_whitespace_tokenizer ():
def create_tokenizer (nlp):
вернуть WhitespaceTokenizer (nlp.vocab)
вернуть create_tokenizer
Зарегистрированные функции также могут принимать аргументы, которые затем передаются из
config. Это позволяет быстро изменять и отслеживать различные настройки.Здесь зарегистрированная функция bert_word_piece_tokenizer принимает два
аргументы: путь к файлу словаря и необходимость строчных букв. В
Подсказки типа Python str и bool гарантируют, что полученные значения имеют
правильный тип.
@spacy.registry.tokenizers ("bert_word_piece_tokenizer") def create_whitespace_tokenizer (vocab_file: str, нижний регистр: bool):
def create_tokenizer (nlp):
вернуть BertWordPieceTokenizer (nlp.vocab, vocab_file, строчные буквы)
вернуть create_tokenizer
Чтобы избежать жесткого кодирования локальных путей в файле конфигурации, вы также можете установить
Vocab путь в CLI с помощью переопределения --nlp.tokenizer.vocab_file при запуске большой поезд . Для получения более подробной информации об использовании зарегистрированных функций,
см. документацию по обучению с пользовательским кодом.
Помните, что зарегистрированная функция всегда должна быть функцией, призывает создавать что-то , а не само «что-то». В этом случае это создает функцию , которая принимает объект nlp и возвращает вызываемый объект, который
принимает текст и возвращает Doc .
Использование предварительно токенизированного текста
spaCy обычно предполагает по умолчанию, что ваши данные - это необработанный текст . Тем не мение,
иногда ваши данные частично аннотируются, например.грамм. с уже существующей токенизацией,
теги части речи и т. д. Чаще всего у вас предопределенная токенизация . Если у вас есть список строк, вы можете создать Doc объект напрямую. При желании вы также можете указать список
логические значения, указывающие, следует ли за каждым словом пробел.
✏️ Что попробовать
Измените логическое значение в списке пробелов . Вы должны увидеть это в отражении
в doc.text и следует ли за маркером пробел.
Удалите пробелов = пробелов из Doc . Вы должны увидеть, что каждый токен
теперь следует пробел.
Скопируйте и вставьте случайное предложение из Интернета и вручную создайте Doc с словами и пробелами , так что doc.text соответствует оригиналу
ввод текста.
импорт прост.
из spacy.tokens import Doc
nlp = spacy.blank ("ru")
words = ["Привет", ",", "мир", "!"]
пробелы = [Ложь, Истина, Ложь, Ложь]
doc = Док (nlp.словарь, слова = слова, пробелы = пробелы)
печать (doc.text)
print ([(t.text, t.text_with_ws, t.whitespace_) для t в документе])
Если указан, список пробелов должен быть той же длины , что и список слов. В
Список пробелов влияет на doc.text , span.text , token.idx , span.start_char и span.end_char атрибутов. Если вы не указали последовательность пробелов , spaCy
будет считать, что после всех слов стоит пробел.Как только у вас будет Doc , вы можете записать в его атрибуты, чтобы установить
теги части речи, синтаксические зависимости, именованные объекты и другие
атрибуты.
Согласование токенизации
Токенизация spaCy является неразрушающей и использует правила, зависящие от языка
оптимизирован для совместимости с аннотациями банка деревьев. Другие инструменты и ресурсы
может иногда токенизировать вещи по-разному - например, «Я» → [«I», «'», «m»] вместо [«I», «m»] .
В подобных ситуациях вам часто нужно выровнять токенизацию, чтобы
может объединять аннотации из разных источников вместе или брать предсказанные векторы
по
предварительно обученная модель BERT и
примените их к токенам spaCy. spaCy’s Выравнивание объект позволяет однозначно отображать индексы токенов в обоих направлениях, как
а также с учетом индексов, в которых несколько токенов совпадают с одним
токен.
✏️ Что попробовать
Измените регистр в одном из списков токенов - например, «Обама» до «Обама» .Вы увидите, что при выравнивании регистр не учитывается.
Измените «подкасты» в other_tokens на «pod», «casts» . Тебе следует увидеть
что теперь есть два токена длины 2 в y2x , один соответствует
«S», а один - «подкасты».
Сделайте other_tokens и spacy_tokens идентичными. Вы увидите, что все
токены теперь соответствуют 1 к 1.
Вот некоторые выводы из информации о выравнивании, сгенерированной в примере.
выше:
Сопоставления "один-к-одному" для первых четырех токенов идентичны, что означает
они сопоставляются друг с другом.Это имеет смысл, потому что они идентичны и в
ввод: "i" , "слушал" , "до" и "обама" .
Значение x2y.dataXd [6] равно 5 , что означает, что other_tokens [6] ( «подкасты» ) выравниваются с spacy_tokens [5] (также «подкасты» ).
x2y.dataXd [4] и x2y.dataXd [5] оба являются 4 , что означает, что оба токена
4 и 5 из other_tokens ( "'" и "s" ) выравниваются с токеном 4 из spacy_tokens ( "х" ).
Важное примечание
Текущая реализация алгоритма выравнивания предполагает, что оба
токенизации складываются в одну и ту же строку. Например, вы сможете выровнять [«я», «'», «м»] и [«я», «м»] , которые в сумме дают «я» , но не [«Я», «Я»] и [«Я», «Я»] .
Диспетчер контекста Doc.retokenize позволяет объединять и
разделить токены. Изменения токенизации сохраняются и выполняются на
один раз при выходе из диспетчера контекста.Объединить несколько токенов в один
токен, передать Span в ретокенизатор .merge . An
дополнительный словарь attrs позволяет вам установить атрибуты, которые будут назначены
объединенный токен - например, лемма, тег части речи или тип объекта. От
по умолчанию объединенный токен получит те же атрибуты, что и объединенный диапазон
корень.
✏️ Что попробовать
Проверьте атрибут token.lemma_ с установкой атрибутов и без него.Вы увидите, что в лемме по умолчанию используется «New», лемма о корне span.
Перезаписать другие атрибуты, такие как "ENT_TYPE" . Поскольку «Нью-Йорк» тоже
распознается как именованный объект, это изменение также будет отражено в документов .
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Я живу в Нью-Йорке»)
print ("До:", [token.text для токена в документе])
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (документ [3: 5], attrs = {"ЛЕММА": "нью-йорк"})
print ("После:", [токен.текст для токена в документе])
Совет: объединение сущностей и словосочетаний с существительными
Если вам нужно объединить именованные сущности или фрагменты существительных, воспользуйтесь встроенным merge_entities и merge_noun_chunks конвейер
составные части. При добавлении в конвейер с помощью nlp.add_pipe они займут
забота об автоматическом слиянии пролетов.
Если атрибут в attrs является контекстно-зависимым атрибутом токена, он будет
применяться к базовому токену .Например LEMMA , POS или DEP применяются только к слову в контексте, поэтому они являются атрибутами токена. Если
атрибут - это контекстно-независимый лексический атрибут, он будет применяться к
лежащая в основе Лексема , запись в словаре. Например, LOWER или IS_STOP применяются ко всем словам с одинаковым написанием, независимо от
контекст.
Примечание по объединению перекрывающихся промежутков
Если вы пытаетесь объединить перекрывающиеся промежутки, spaCy выдаст ошибку, потому что
неясно, как должен выглядеть результат.В зависимости от приложения вы можете
хотите сопоставить самый короткий или самый длинный возможный диапазон, поэтому вам решать, как отфильтровать
их. Если вы ищете самый длинный неперекрывающийся интервал, вы можете использовать util.filter_spans helper:
Метод retokenizer.split позволяет разделить
один жетон на два или более жетона.Это может быть полезно в тех случаях, когда
Одних правил токенизации недостаточно. Например, вы можете захотеть разделить
«Его» в токены «оно» и «есть», но не притяжательное местоимение «его». Ты
может написать логику, основанную на правилах, которая может найти только правильное «свое» для разделения, но
к этому времени Doc уже будет токенизирован.
Этот процесс разделения токена требует дополнительных настроек, потому что вам нужно
укажите текст отдельных токенов, необязательные атрибуты каждого токена и способ
должен быть прикреплен к существующему синтаксическому дереву.Это можно сделать
предоставление списка из голов - либо токен для присоединения вновь разделенного токена
к, или кортеж (токен, суб-токен) , если новый разделенный токен должен быть присоединен
к другому подтекену. В этом случае «New» следует прикрепить к «York» (
второй разделенный подтекст) и «York» следует присоединить к «in».
✏️ Что стоит попробовать
Назначьте различные атрибуты субтогенам и сравните результат.
Измените головки так, чтобы «New» было прикреплено к «in», а «York» - прикреплено.
на «Новый».
Разделите жетон на три жетона вместо двух - например, [«Новый», «Йо», «рк»] .
импорт прост.
от просторного импорта
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Я живу в Нью-Йорке»)
print ("До:", [token.text для токена в документе])
displacy.render (док)
с doc.retokenize () в качестве ретокенизатора:
Heads = [(док [3], 1), док [2]]
attrs = {"POS": ["PROPN", "PROPN"], "DEP": ["pobj", "соединение"]}
retokenizer.split (doc [3], ["New", "York"], Heads = Heads, attrs = attrs)
print ("После:", [токен.текст для токена в документе])
displacy.render (док)
Указание глав в виде списка из токенов или (токен, подтекен) кортежей позволяет
присоединение разделенных субтокенов к другим субтокенам без необходимости отслеживать
индексы токенов после разделения.
Токен
Голова
Описание
«Новый»
(doc [3], 1)
Прикрепите этот токен ко второму индексу (индекс 9010) 1 что doc [3] будет разделен на: i.е. «Йорк».
"York"
doc [2]
Прикрепите этот токен к doc [1] в исходном Doc , т.е. «in».
Если вас не волнуют головы (например, если вы используете только
токенизатор, а не парсер), вы можете прикрепить каждый подтекен к себе:
doc = nlp («Я живу в Нью-Йорке»)
с doc.retokenize () в качестве ретокенизатора:
Heads = [(doc [3], 0), (doc [3], 1), (doc [3], 2)] ретокенизатор.split (doc [3], ["Новый", "Йорк", "Город"], Heads = Heads)
Важное примечание
При разделении токенов тексты суб-токенов всегда должны совпадать с оригиналом
текст токена - или, иначе говоря, "" .join (subtokens) == token.text всегда нужен
быть правдой. Если бы это было не так, разделение токенов могло бы легко закончиться
приводящие к запутанным и неожиданным результатам, которые противоречили бы
Политика неразрушающей токенизации.
doc = nlp («Я живу в Лос-Анджелесе.")
с doc.retokenize () в качестве ретокенизатора:
- retokenizer.split (doc [3], ["Los", "Angeles"], Heads = [(doc [3], 1), doc [2]])
+ retokenizer.split (doc [3], ["L.", "A."], Heads = [(doc [3], 1), doc [2]])
Перезапись атрибутов настраиваемого расширения
Если вы зарегистрировали настраиваемый
атрибуты расширения,
вы можете перезаписать их во время токенизации, предоставив словарь
имена атрибутов сопоставлены с новыми значениями как ключ "_" в атрибуте attrs . Для
слияния, вам нужно предоставить один словарь атрибутов для результирующего
объединенный токен.Для разделения вам необходимо предоставить список словарей с
настраиваемые атрибуты, по одному на каждый под токен разделения.
Важное примечание
Чтобы установить атрибуты расширения во время повторной токенизации, атрибуты должны быть зарегистрировал с использованием Token.set_extension метод, и они должны быть с возможностью записи . Это означает, что они должны иметь
значение по умолчанию, которое можно перезаписать, или геттер и установщик . Методика
расширения или расширения только с геттером вычисляются динамически, поэтому их
значения не могут быть перезаписаны.Подробнее см.
документация по атрибуту расширения.
✏️ Что стоит попробовать
Добавьте еще одно собственное расширение - может быть, "music_style" ? - и перезапишите его.
Измените атрибут расширения, чтобы использовать только функцию получения . Вам следует
видите, что spaCy вызывает ошибку, потому что атрибут недоступен для записи
больше.
Перепишите код, чтобы разделить токен на retokenizer.split . Помни это
вам необходимо предоставить список значений атрибутов расширения в виде "_" Свойство, по одному на каждый субтекер разделения.
импорт прост.
из spacy.tokens импортировать токен
Token.set_extension ("is_musician", по умолчанию = False)
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Мне нравится Дэвид Боуи»)
print ("До:", [(token.text, token ._. is_musician) для токена в документе])
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (документ [2: 4], attrs = {"_": {"is_musician": True}})
print ("После:", [(token.text, token ._. is_musician) для токена в документе])
Предложения объекта Doc доступны через Doc.сенты имущество. Чтобы просмотреть предложения Doc , вы можете перебрать Doc.sents , a
генератор, который дает Span объектов. Вы можете проверить, действительно ли Doc имеет границы предложения, позвонив Doc.has_annotation с именем атрибута «SENT_START» .
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Это предложение. Это другое предложение.")
assert doc.has_annotation ("SENT_START")
для отправки в док.отправляет:
печать (отправлено. текст)
spaCy предоставляет четыре альтернативы для сегментации предложений:
Анализатор зависимостей: статистический DependencyParser обеспечивает наиболее точный
границы предложения основаны на синтаксическом анализе полной зависимости.
Статистический сегментатор предложений: статистический SentenceRecognizer - это проще и быстрее
альтернатива синтаксическому анализатору, который устанавливает только границы предложения.
Компонент конвейера на основе правил: основанный на правилах Sentencizer устанавливает границы предложения с помощью
настраиваемый список знаков препинания в конце предложения.
Пользовательская функция: ваша собственная функция, добавленная в
конвейер обработки может устанавливать границы предложения, записывая Token.is_sent_start .
По умолчанию: Использование анализа зависимостей Требуется модель
В отличие от других библиотек, spaCy использует синтаксический анализ зависимостей для определения предложения
границы. Обычно это наиболее точный подход, но он требует обученный конвейер , который обеспечивает точные прогнозы. Если твои тексты
ближе к новостям общего назначения или веб-тексту, это должно работать сразу после установки.
с предоставленными spaCy подготовленными конвейерами.Для социальных сетей или разговорного текста
который не соответствует тем же правилам, ваше приложение может извлечь выгоду из пользовательского
обученный или основанный на правилах компонент.
импорт прост.
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Это предложение. Это другое предложение.")
для присланных документов:
печать (отправлено. текст)
синтаксический анализатор зависимостей spaCy учитывает уже установленные границы, поэтому вы можете предварительно обрабатывать
ваш Doc с использованием пользовательских компонентов перед тем, как будет проанализирован.В зависимости от вашего текста,
это также может повысить точность синтаксического анализа, поскольку синтаксический анализатор ограничен предсказывать
синтаксический анализ в соответствии с границами предложения.
Статистический сегментатор предложений v3.0 Модель потребностей
The SentenceRecognizer - это простой статистический
компонент, который предоставляет только границы предложения. Наряду с тем, чтобы быть быстрее и
меньше, чем парсер, его основное преимущество состоит в том, что его легче обучить
потому что для этого требуются только аннотированные границы предложения, а не полные
анализ зависимостей.Обученные конвейеры spaCy включают в себя как синтаксический анализатор,
и обученный сегментатор предложений, который
по умолчанию отключено. Если тебе нужно только
границы предложения и без синтаксического анализатора, вы можете использовать , исключить или , отключить аргумент на spacy.load для загрузки конвейера
без синтаксического анализатора, а затем явно включите распознаватель предложений с помощью nlp.enable_pipe .
senter vs. parser
Отзыв для senter обычно немного ниже, чем для парсера,
который лучше предсказывает границы предложения, когда пунктуация не
настоящее время.
импорт прост.
nlp = spacy.load ("en_core_web_sm", exclude = ["parser"])
nlp.enable_pipe ("центр")
doc = nlp ("Это предложение. Это другое предложение.")
для присланных документов:
печать (отправлено. текст)
Компонент конвейера на основе правил
Компонент Sentencizer является
компонент конвейера, который разбивает предложения на
пунктуация как . , ! или ? . Вы можете подключить его к своему конвейеру, если только
нужны границы предложения без синтаксического анализа зависимостей.
импорт прост.
from spacy.lang.en импорт английский
nlp = английский ()
nlp.add_pipe ("приговорщик")
doc = nlp ("Это предложение. Это другое предложение.")
для присланных документов:
печать (отправлено. текст)
Пользовательская стратегия на основе правил
Если вы хотите реализовать свою собственную стратегию, которая отличается от стратегии по умолчанию
основанный на правилах подход к разделению предложений, вы также можете создать
настраиваемый компонент конвейера, который
берет объект Doc и устанавливает токен .is_sent_start на каждом
индивидуальный жетон. Если установлено значение False , токен явно помечается как , а не как .
начало предложения. Если установлено значение Нет (по умолчанию), оно обрабатывается как отсутствующее значение.
и все еще может быть перезаписан парсером.
Важное примечание
Для предотвращения несогласованного состояния вы можете установить границы только до документа
анализируется (и doc.has_annotation ("DEP") - False ). Чтобы ваш
компонент добавлен в нужном месте, вы можете установить перед = 'parser' или first = True при добавлении в конвейер с помощью нлп.add_pipe .
Вот пример компонента, который реализует правило предварительной обработки для
разбиение на "..." токенов. Компонент добавляется перед анализатором, то есть
затем используется для дальнейшего сегментирования текста. Это возможно, потому что is_sent_start только для некоторых токенов установлено значение Истинно - для всех остальных по-прежнему указывается Нет для неустановленных границ предложения. Этот подход может быть полезен, если вы хотите
реализовать дополнительных правил , относящихся к вашим данным, при этом сохраняя возможность
воспользоваться преимуществами сегментации предложений на основе зависимостей.
из spacy.language import Language
импортный простор
text = "это предложение ... привет ... и еще одно предложение".
nlp = spacy.load ("en_core_web_sm")
doc = nlp (текст)
print ("До:", [отправленный текст для отправки в документах])
@ Language.component ("set_custom_boundaries")
def set_custom_boundaries (документ):
для токена в документе [: - 1]:
если token.text == "...":
doc [token.i + 1] .is_sent_start = Истина
вернуть документ
nlp.add_pipe ("set_custom_boundaries", before = "parser")
doc = nlp (текст)
print ("После:", [отправлено.текст для отправки в документах])
AttributeRuler управляет сопоставлениями на основе правил и
исключения для всех атрибутов уровня токена. Как количество
компоненты конвейера выросли со spaCy v2 до
v3, обработка правил и исключений в каждом компоненте в отдельности стала
непрактично, поэтому AttributeRuler предоставляет один компонент с унифицированным
формат шаблона для всех сопоставлений атрибутов токенов и исключений.
Атрибут AttributeRuler использует Сопоставитель шаблонов для идентификации
токены, а затем присваивает им предоставленные атрибуты.При необходимости Соответствие шаблонам может включать контекст вокруг целевого токена.
Например, линейка атрибутов может:
предоставлять исключения для любых атрибутов токена
отображать мелкозернистые теги до крупнозернистые теги для языков без
статистические морфологизаторы (замена v2.x tag_map в
языковых данных)
маркер карты форма поверхности + мелкозернистые теги от до морфологические признаки (замена v2.x morph_rules в языковых данных)
укажите теги для пробелов (заменяя жестко запрограммированное поведение в
tagger)
В следующем примере показано, как можно указать тег и POS NNP / PROPN .
для фразы "The Who" , переопределив теги, предоставленные статистическим
tagger и карта тегов POS.
Атрибут AttributeRuler может импортировать карту тегов и преобразовывать
rules в v2.x с помощью встроенных методов или когда компонент
инициализируется перед обучением. Увидеть
руководство по миграции для получения подробной информации.
Сходство определяется путем сравнения векторов слов или «вложений слов»,
многомерные смысловые представления слова. Векторы слов могут быть
генерируется с использованием такого алгоритма, как
word2vec и обычно выглядят так:
Чтобы сделать их компактными и быстрыми, небольшие конвейерные пакеты spaCy (все
пакеты, заканчивающиеся на sm ) , не поставляются с векторами слов и включают только
контекстно-зависимые тензоры . Это означает, что вы все еще можете использовать подобие () методы для сравнения документов, промежутков и токенов - но результат не будет таким
хорошо, и отдельным токенам не будут назначены векторы.Итак, чтобы использовать реальных векторов слов, вам необходимо загрузить более крупный пакет конвейера:
Пакеты конвейеров, которые поставляются со встроенными векторами слов, делают их доступными как
атрибут Token.vector . Док. Вектор и Span.vector будет
по умолчанию используется среднее значение их векторов токенов. Вы также можете проверить, есть ли у токена
назначенный вектор и получить норму L2, которую можно использовать для нормализации векторов.
Слова «собака», «кошка» и «банан» довольно распространены в английском языке, поэтому они
часть словаря конвейера и поставляется с вектором.Слово «afskfsd» на
другая рука гораздо менее распространена и не входит в словарный запас, поэтому ее вектор
представление состоит из 300 измерений 0 , что означает, что это практически
несуществующий. Если ваше приложение получит выгоду от большого словаря с
больше векторов, вам следует рассмотреть возможность использования одного из более крупных пакетов конвейера или
загрузка в полном векторном пакете, например, en_core_web_lg , что включает 685k уникальных
Векторы .
spaCy может сравнивать два объекта и делать прогноз , насколько похожи
они .Прогнозирование сходства полезно для построения рекомендательных систем.
или отметка дубликатов. Например, вы можете предложить пользовательский контент,
аналогично тому, что они сейчас просматривают, или обозначьте обращение в службу поддержки как
дублировать, если он очень похож на уже существующий.
Каждый Doc , Span , Токен и Lexeme идет с . Подобие метод, позволяющий сравнить его с другим объектом и определить
сходство.Конечно, сходство всегда субъективно - будь то два слова,
или документы похожи, в действительности зависит от того, как вы на это смотрите. spaCy’s
реализация подобия обычно предполагает довольно общее определение
сходство.
📝 Что стоит попробовать
Сравните два разных токена и попытайтесь найти два самых разных разных токены в текстах с наименьшей оценкой сходства (согласно
векторы).
Сравните сходство двух объектов лексемы , записи в
словарь.Вы можете получить лексему с помощью атрибута .lex токена.
Вы должны увидеть, что результаты подобия идентичны токену
сходство.
Вычисление оценок схожести может быть полезным во многих ситуациях, но это также
важно поддерживать реалистичных ожиданий о том, какую информацию он может
предоставлять.Слова могут быть связаны друг с другом по-разному, поэтому один
Оценка «подобия» всегда будет сочетанием различных сигналов, и векторов
обучение на разных данных может дать очень разные результаты, которые могут не
полезно для ваших целей. Вот несколько важных моментов, о которых следует помнить:
Объективного определения сходства не существует. «Я люблю гамбургеры» и «Я
как макароны »аналогичен в зависимости от вашего приложения . Оба говорят о еде
предпочтения, что делает их очень похожими, но если вы анализируете упоминания
еды, эти предложения довольно не похожи, потому что они говорят о очень
разные продукты.
Сходство значений по умолчанию для объектов Doc и Span к средним векторов токенов. Это означает, что вектор для «быстрого
еда »- это среднее значение векторов для слов« быстро »и« еда », что не является
обязательно представитель словосочетания «фаст-фуд».
Усреднение вектора означает, что вектор нескольких токенов нечувствителен к
порядок слов. Два документа, выражающие одно и то же значение с
несходная формулировка даст более низкий балл схожести, чем два документа
которые содержат одни и те же слова, но имеют разные значения.
💡Совет: ознакомьтесь с sense2vec
sense2vec - это библиотека, разработанная
us, который построен на основе spaCy и позволяет вам обучать и запрашивать более интересные и
подробные векторы слов. Он сочетает в себе такие словосочетания, как «фаст-фуд» или «честная игра».
и включает теги части речи и метки объектов. Библиотека также
включает рецепты аннотаций для нашего инструмента аннотации Prodigy
которые позволяют оценивать векторы и создавать списки терминологии. Больше подробностей,
ознакомьтесь с нашим сообщением в блоге.К
изучить семантическое сходство всех комментариев Reddit за 2015 и 2019 годы,
см. интерактивную демонстрацию.
Добавление векторов слов
Пользовательские векторы слов можно обучить с помощью ряда библиотек с открытым исходным кодом, таких как
как Gensim, FastText,
или оригинал Томаса Миколова
Реализация Word2vec. Большинство
библиотеки векторных слов выводят удобный для чтения текстовый формат, где каждая строка
состоит из слова, за которым следует его вектор. Для повседневного использования мы хотим
преобразовать векторы в двоичный формат, который загружается быстрее и занимает меньше времени
место на диске.Самый простой способ сделать это - векторов инициализации Утилита командной строки . Это выведет
пустой конвейер spaCy в каталоге / tmp / la_vectors_wiki_lg , что дает вам
доступ к некоторым красивым латинским векторам. Затем вы можете передать путь к каталогу spacy.load или используйте его в [инициализировать] вашей конфигурации, когда вы
обучить модель.
Пример использования
nlp_latin = spacy.load ("/ tmp / la_vectors_wiki_lg")
doc1 = nlp_latin ("Caecilius est in horto")
doc2 = nlp_latin ("servus est in atrio")
doc1.сходство (doc2)
wget https://s3-us-west-1.amazonaws.com/fasttext-vectors/word-vectors-v2/cc.la.300.vec.gz python -m spacy init vectors en cc. la.300.vec.gz / tmp / la_vectors_wiki_lg
Как оптимизировать векторное покрытие¶
Чтобы помочь вам найти хороший баланс между покрытием и использованием памяти, spaCy's Vectors Класс позволяет сопоставить несколько ключей с тем же строка таблицы. Если вы используете spacy init vectors команда для создания словаря,
об обрезке векторов позаботится автоматически, если вы установите --prune флаг.Вы также можете сделать это вручную, выполнив следующие шаги:
Начните с пакета векторов слов , который охватывает огромный словарный запас. Для
Например, пакет en_core_web_lg предоставляет
300-мерные векторы GloVe для 685 тыс. Терминов английского языка.
Если в вашем словаре есть значения, установленные для атрибута Lexeme.prob ,
лексемы будут отсортированы по убыванию вероятности, чтобы определить, какие векторы
обрезать. В противном случае лексемы будут отсортированы по порядку в Vocab .
Позвоните Vocab.prune_vectors с номером
векторы, которые вы хотите сохранить.
Vocab.prune_vectors уменьшает вектор тока
таблица на заданное количество уникальных записей и возвращает словарь, содержащий
удаленные слова, сопоставленные с (строка, оценка) кортежей, где строка - это
запись, с которой было сопоставлено удаленное слово, и баллов баллов сходства между
два слова.
В приведенном выше примере вектор для «Берега» был удален и переназначен на
вектор «берега», который оценивается примерно на 73% схожим.«Уход» был перенесен на
вектор «ухода» идентичен. Если вы используете init vectors команду, вы можете установить --prune возможность легко уменьшать размер векторов при добавлении их в spaCy
pipeline:
Это создаст пустой конвейер spaCy с векторами для первых 10000 слов
в векторах. Все остальные слова в векторах отображаются на ближайший вектор
среди оставшихся.
Добавление векторов по отдельности
Атрибут vector представляет собой массив только для чтения numpy или cupy (в зависимости от
сконфигурировали ли вы spaCy для использования памяти графического процессора) с dtype float32 . В
массив доступен только для чтения, поэтому spaCy может избежать ненужных операций копирования, где
возможный. Вы можете изменить векторы через Vocab или Векторы таблица. С помощью Vocab.set_vector Метод часто самый простой подход
если у вас есть векторы в произвольном формате, как вы можете читать в векторах с
ваша собственная логика и просто установите их с помощью простого цикла.Этот метод может
быть медленнее, чем подходы, которые работают со всей таблицей векторов сразу, но
это отличный подход для разовых конверсий, прежде чем вы сэкономите свои nlp объект на диск.
Каждый язык индивидуален и обычно полон исключений и специальных
case , особенно среди самых распространенных слов. Некоторые из этих исключений
общие для разных языков, в то время как другие являются полностью конкретными - обычно так
В частности, они должны быть жестко запрограммированы. В lang Модуль содержит все данные для конкретного языка,
организованы в простые файлы Python. Это упрощает обновление и расширение данных.
Данные общего языка в корне каталога содержат правила, которые могут быть
обобщены для разных языков - например, правила для базовой пунктуации, смайликов,
смайлики и однобуквенные сокращения. Индивидуальные языковые данные в
подмодуль содержит правила, относящиеся только к определенному языку. Это
также заботится о том, чтобы собрать все компоненты и создать Подкласс языка - например, Английский или Немецкий .В
Значения определены в языке . Значения по умолчанию .
из spacy.lang.en импорт английский
из spacy.lang.de импорт немецкий
nlp_en = английский ()
nlp_de = немецкий ()
Имя
Описание
Стоп-слова stop_words.py
Список наиболее распространенных слов языка, которые часто полезно отфильтровать, например «и» или "Я". Соответствующие жетоны вернут True для is_stop .
Исключения для токенизатора tokenizer_exceptions.py
Особые правила для токенизатора, например такие сокращения, как «не могу», и аббревиатуры с пунктуацией, например «Великобритания».
Правила пунктуации punctuation.py
Регулярные выражения для разделения токенов, например о пунктуации или специальных символах, например смайликах. Включает правила для префиксов, суффиксов и инфиксов.
Классы символов char_classes.py
Классы символов для использования в регулярных выражениях, например латинские символы, кавычки, дефисы или значки.
Лексические атрибуты lex_attrs.py
Пользовательские функции для установки лексических атрибутов токенов, например like_num , который включает в себя специфичные для языка слова, такие как «десять» или «сотня».
Итераторы синтаксиса syntax_iterators.py
Функции, которые вычисляют представления объекта Doc на основе его синтаксиса.В настоящее время используется только для имен существительных.
Lemmatizer lemmatizer.py spacy-lookups-data
Реализация пользовательского лемматизатора и таблицы лемматизации.
Создание подкласса настраиваемого языка
Если вы хотите настроить несколько компонентов языковых данных или добавить поддержку
для пользовательского языка или "диалекта" домена, вы также можете реализовать свой
собственный языковой подкласс.Подкласс должен определять два атрибута: lang (уникальный код языка) и Defaults , определяющие языковые данные. Для
обзор доступных атрибутов, которые можно перезаписать, см. Language.Defaults Документация по .
из spacy.lang.en импорт английский
класс CustomEnglishDefaults (англ.Defaults):
stop_words = set (["заказ", "стоп"])
class CustomEnglish (английский):
lang = "custom_en"
По умолчанию = CustomEnglishDefaults
nlp1 = английский ()
nlp2 = CustomEnglish ()
печать (nlp1.lang, [token.is_stop для токена в nlp1 ("настраиваемая остановка")])
print (nlp2.lang, [token.is_stop для токена в nlp2 («настраиваемая остановка»)])
Декоратор @ spacy.registry.languages позволяет
зарегистрируйте собственный языковой класс и присвойте ему строковое имя. Это значит, что
Вы можете позвонить по номеру spacy.blank со своим индивидуальным
название языка, и даже обучать конвейеры с ним и ссылаться на него в вашем
тренировочная конфигурация.
Использование конфигурации
После регистрации вашего пользовательского языкового класса с помощью реестра languages ,
вы можете сослаться на него в своей тренировочной конфигурации.Этот
означает, что spaCy будет обучать ваш конвейер с помощью настраиваемого подкласса.
[nlp]
lang = "custom_en"
Чтобы разрешить "custom_en" для вашего подкласса, зарегистрированная функция
должен быть доступен во время тренировки. Вы можете загрузить файл Python, содержащий
код с использованием аргумента --code :
python -m spacy train config.cfg --code code.py
Регистрация настраиваемого языка
import spacy
от простора.lang.en import English
класс CustomEnglishDefaults (англ.Defaults):
stop_words = set (["заказ", "стоп"])
@ spacy.registry.languages ("custom_en") класс CustomEnglish (английский):
lang = "custom_en"
По умолчанию = CustomEnglishDefaults
nlp = spacy.blank ("custom_en")
грамматик в Prolog
грамматик в Prolog Далее: Пролог как база данных Up: Введение в Prolog Предыдущая: Планирование машины
Далее мы переходим к более сложным примерам программирования на Прологе.Пролог
изначально был изобретен как язык программирования, на котором можно было писать
приложений на естественном языке, и поэтому Prolog является очень элегантным
язык для выражения грамматики. Пролог даже имеет встроенный синтаксис
специально создан для написания грамматик. Часто говорят, что с
Prolog one получает встроенный парсер бесплатно. В этом разделе мы будем
увидеть, почему это требование предъявляется (а иногда и оспаривается).
Рассмотрим следующую простую контекстно-свободную грамматику для небольшого
фрагмент англ.
Из этой грамматики мы можем вывести такие простые предложения, как:
мужчина любит женщину каждая женщина ходит женщине нравится парк
Мы можем написать простую программу Prolog для распознавания этого языка,
написание парсера рекурсивного спуска.Сначала мы должны решить, как
обрабатывать входную строку. Мы будем использовать список в Прологе. Для каждого
нетерминальный, мы построим процедуру Пролога для распознавания строк
порожденный этим нетерминалом. Каждая процедура будет состоять из двух
аргументы. Первый будет входным параметром, состоящим из
список, представляющий входную строку. Второй будет выходом
аргумент, и будет установлен процедурой в оставшуюся часть
входная строка после начального сегмента, совпадающего с нетерминалом, имеет
был удален.Пример поможет прояснить, как это работает. В
процедура для np , например, примет в качестве первого аргумента
список [женщина, любит, мужчина] и вернется во второй раз
аргумент список [любит, мужчина] . Сегмент удален
процедура, [а, женщина] , является НП. Программа Prolog:
s (S0, S): - np (S0, S1), vp (S1, S).
np (S0, S): - det (S0, S1), n (S1, S).
vp (S0, S): - tv (S0, S1), np (S1, S).
vp (S0, S): - v (S0, S).
det (S0, S): - S0 = [| S].det (S0, S): - S0 = [a | S].
det (S0, S): - S0 = [каждые | S].
n (S0, S): - S0 = [человек | S].
n (S0, S): - S0 = [женщина | S].
n (S0, S): - S0 = [парк | S].
tv (S0, S): - S0 = [любит | S].
tv (S0, S): - S0 = [лайки | S].
v (S0, S): - S0 = [прогулки | S].
Первый пункт определяет процедуру s для распознавания
предложения. Список ввода S0 передается в процедуру s ,
и он должен установить S как оставшуюся часть списка S после того, как предложение было удалено с самого начала.Для этого он
использует две подпроцедуры: сначала вызывает np для удаления NP, и
затем он вызывает vp , чтобы удалить из этого VP. Поскольку грамматика
говорит, что S - это NP, за которым следует VP, это будет правильно
вещь. Остальные правила полностью аналогичны.
Поместив эту программу в файл под названием grammar.P , мы можем загрузить
и выполните это в наших примерах предложений следующим образом:
% xsb
XSB версии 1.4.1 (94/11/21)
[последовательный, одно слово, оптимальный режим]
| ? - [грамматика].[Компиляция ./grammar]
[грамматика скомпилирована, время ЦП: 1,14 секунды]
[грамматика загружена]
да
| ? - s ([a, мужчина, любит, the, женщина], []).
да
| ? - s ([каждый, женщина, ходит], []).
да
| ? - s ([a, женщина, любит, the, park], []).
да
| ? - s ([a, женщина, любит, the, prak], []).
нет
| ? -
Когда строка написана на языке грамматики, программа
выполнить успешно до конца, и система производит
"да". Если строка не на языке, как в последнем примере
там, где слово «парк» написано с ошибкой, система отвечает «нет».Мы позвонили в s Процедура с входной строкой в качестве первого аргумента, и мы дали
это пустой список в качестве второго аргумента, потому что мы хотим, чтобы он соответствовал
вся входная строка, ничего не осталось после просмотра s .
Грамматика выше называется Грамматика с определенными предложениями (DCG) и
Prolog поддерживает специальный синтаксис правил для написания DCG. Синтаксис:
проще, гораздо ближе к синтаксису, который используется при написании контекстно-зависимых
грамматические правила. При использовании синтаксиса DCG у программиста нет
для записи всех строковых переменных, проходящих через нетерминал
вызовы процедур; компилятор сделает это.Вот то же самое
Программа Prolog такая же, как указано выше, но с использованием DCG:
с -> нп, вп.
нп -> дет, н.
вп -> тв, нп.
vp -> v.
det -> [the].
det -> [а].
det -> [каждые].
п -> [мужчина].
п -> [женщина].
п -> [парк].
телевизор -> [любит].
тв -> [лайки].
v -> [ходит].
Обратите внимание, что в этих `` определениях процедур '' используется символ -> .
вместо : - , чтобы отделить головку процедуры от процедуры
тело.Компилятор Пролога преобразует такие правила в (почти) точно
программу выше, добавив дополнительные аргументы к предикатным символам
и рассматривать списки как терминалы. `` Почти '' потому, что
действительно переводит, например, список из одного слова [любит] выше к вызову процедуры 'C' (S0, loves, S) и включает
определение этого нового предиката как:
'C' ([Слово | Строка], Слово, Строка).
Это дает точно такой же эффект, что и программа Prolog для
грамматика приведена выше.
Рассмотрим другой пример грамматики, на этот раз для простой арифметики.
выражения над целыми числами с операторами + и * :
Об этом DCG следует отметить несколько моментов. Обратите внимание, что список
записи, представляющие терминалы, не должны появляться отдельно на
правые части правил DCG, но могут сопровождать нетерминалы.Также
обратите внимание на первое правило , фактор ; у него есть переменная ( I )
в списке, что приведет к его сопоставлению и, таким образом, установит значение,
следующий входной символ. Следующий вызов процедуры заключен в
подтяжки. Это означает, что он не соответствует ни одному входному символу, и поэтому его
перевод в Пролог НЕ приводит к тому, что строковые переменные
добавлен. Остается лишь вызов процедуры Пролога с одним
аргумент: целое число (I) . Целочисленная процедура является Прологом.
встроенный, который проверяет, является ли его аргумент целым числом.Обратите внимание также
что мы должны указать скобки в окончательном правиле. Иначе,
Читатель Пролога не сможет правильно разобрать их как атомы.
Рассмотрим несколько примеров выполнения этой грамматики:
Эта грамматика не самая очевидная из тех, что нужно записывать для этого
язык выражения. Он специально сконструирован, чтобы его не оставили
рекурсивный. Выше мы упоминали, что пишем рекурсивный
анализатор спуска для грамматики, и это то, что каждый получает для DCG
из стратегии выполнения Пролога. Выполнение пролога нижележащего
детерминированные машины и использование стека для их планирования
естественно дает рекурсивный анализатор спуска. И хорошо известно, что
синтаксический анализатор с рекурсивным спуском не может обрабатывать леворекурсивные грамматики; Это
зайдет на них в бесконечный цикл.Итак, в Прологе мы должны избегать
леворекурсивные грамматики.
Также рекурсивный анализатор спуска может быть довольно неэффективным на некоторых
грамматики, потому что он может повторно анализировать одну и ту же подстроку много раз. В
Фактически, существуют грамматики, для которых анализаторам рекурсивного спуска требуется время
экспонента от длины входной строки. При использовании DCG в
Пролог, программист должен знать об этих ограничениях и программировать
вокруг них. Именно по этой причине некоторые люди реагируют на
утверждают, что `` Вы получаете парсер бесплатно с Prolog '' с помощью `` Может быть, но
это не парсер, который я хочу использовать.''
(Другой пример добавления аргументов и использования слова / 3 вместо
струны?).

 com, 2021
com, 2021 Дети трех-четырех лет от роду, зачастую, в жесточайшие морозы, ходят босые, еле прикрытые полотняною одеждою и играют на дворе, бегая взапуски. Последствием сего являются знаменитые закаленные тела, и мужчины, хоть и не великаны по росту, но хорошо и крепко сложенные, из которых иные, совершенно безоружные, иногда вступают в борьбу с медведями и, схватив за уши, держат их, пока те не выбьются из сил; тогда они им, вполне подчиненным и лежащим у ног, надевают намордник. Калек или возбуждающих жалость несчастных, обладающих каким-либо природным недостатком, меж них встречается крайне мало…»
Дети трех-четырех лет от роду, зачастую, в жесточайшие морозы, ходят босые, еле прикрытые полотняною одеждою и играют на дворе, бегая взапуски. Последствием сего являются знаменитые закаленные тела, и мужчины, хоть и не великаны по росту, но хорошо и крепко сложенные, из которых иные, совершенно безоружные, иногда вступают в борьбу с медведями и, схватив за уши, держат их, пока те не выбьются из сил; тогда они им, вполне подчиненным и лежащим у ног, надевают намордник. Калек или возбуждающих жалость несчастных, обладающих каким-либо природным недостатком, меж них встречается крайне мало…» А в руках у каждого связка сухих ветвей, которой, махая вокруг тела, приводят в движение воздух, притягивая его к себе… И тогда поры на их теле открываются и текут с них реки пота, а на их лицах – радость и улыбка».
А в руках у каждого связка сухих ветвей, которой, махая вокруг тела, приводят в движение воздух, притягивая его к себе… И тогда поры на их теле открываются и текут с них реки пота, а на их лицах – радость и улыбка». Ваншенкин) 6) Здравствуй, племя младое, незнакомое! (А. Пушкин) 7) Что, дремучий лес, призадумался? (А. Кольцов)
Ваншенкин) 6) Здравствуй, племя младое, незнакомое! (А. Пушкин) 7) Что, дремучий лес, призадумался? (А. Кольцов) Выделите обращения.
Выделите обращения. Блока под диктовку. Выделите обращения. Как они должны быть оформлены с точки зрения пунктуации?
Блока под диктовку. Выделите обращения. Как они должны быть оформлены с точки зрения пунктуации?
 Риторические обращения придают речи торжественность, патетичность, выразительность.)
Риторические обращения придают речи торжественность, патетичность, выразительность.)


 Синтаксическая пятиминутка. Игра “Составь
предложение”. (Приложение 2)
Синтаксическая пятиминутка. Игра “Составь
предложение”. (Приложение 2)
 Запишите предложения, объясните
постановку знаков препинания и нарисуйте схемы.
Запишите предложения, объясните
постановку знаков препинания и нарисуйте схемы.

 Посмотреть, как изменяется
характер обращений к одному и тому же предмету в
зависимости от настроения говорящего.
Посмотреть, как изменяется
характер обращений к одному и тому же предмету в
зависимости от настроения говорящего.


 И любо мне и сладко мне
И любо мне и сладко мне  Сказуемое — ваш, именное сказуемое, выражено местоимением. О юные друзья — словосочетание, являющееся обращением, оно грамматически не связано с членами предложения.Письменный разбор
Сказуемое — ваш, именное сказуемое, выражено местоимением. О юные друзья — словосочетание, являющееся обращением, оно грамматически не связано с членами предложения.Письменный разбор
 В чём различие употреблений выделенных слов ? Выполните синтаксический разбор предложений. • По синему небу и обилию света чувствуется
В чём различие употреблений выделенных слов ? Выполните синтаксический разбор предложений. • По синему небу и обилию света чувствуется

 Объяснение новой темы.
Объяснение новой темы. Следовательно, не является членом предложения. Роль обращения обычно выполняет существительное в Им.п.
Следовательно, не является членом предложения. Роль обращения обычно выполняет существительное в Им.п. Используйте обращения и записанные вами вежливые слова.
Используйте обращения и записанные вами вежливые слова. Я ссылаюсь на
Я ссылаюсь на
 Когда два или более экземпляра проблемной грамматической конструкции
Когда два или более экземпляра проблемной грамматической конструкции
 Объекты с гиперребром имеют метод
Объекты с гиперребром имеют метод  sc. | f — 3s- / en (: / J /. (the / Md / en
sc. | f — 3s- / en (: / J /. (the / Md / en «Schoolhouse Rock» дебютировал в январе 1973 года на канале ABC. Первый сезон был посвящен обучению детей основам математики. Второй сезон, начавшийся в сентябре того же года, взял на себя проблемы грамматики, сосредоточив большое внимание на синтаксическом анализе предложений. Я признаю, что когда я встречаю определенные слова для частей речи, я все равно слышу тексты.И когда я редактирую текст, эти тексты песен действительно помогли мне в работе. Например, «Междометия показывают возбуждение или эмоции и обычно отделяются от предложения восклицательным знаком или запятой, когда чувство не такое сильное» и «Соединение-соединение: какова ваша функция? Соединение слов, фраз и предложений », настроенных на запоминающиеся мелодии, спасло меня от упорных ошибок. (Хотя не все, как могут утверждать мои редакторы.) Когда два года спустя дебютировал «рок Конституции», он помог мне преуспеть в изучении обществознания в седьмом классе.Я до сих пор помню, что тест просил нас написать слова в преамбуле; Я слышал, как почти все в классе пели эту песню, пока мы писали слова.
«Schoolhouse Rock» дебютировал в январе 1973 года на канале ABC. Первый сезон был посвящен обучению детей основам математики. Второй сезон, начавшийся в сентябре того же года, взял на себя проблемы грамматики, сосредоточив большое внимание на синтаксическом анализе предложений. Я признаю, что когда я встречаю определенные слова для частей речи, я все равно слышу тексты.И когда я редактирую текст, эти тексты песен действительно помогли мне в работе. Например, «Междометия показывают возбуждение или эмоции и обычно отделяются от предложения восклицательным знаком или запятой, когда чувство не такое сильное» и «Соединение-соединение: какова ваша функция? Соединение слов, фраз и предложений », настроенных на запоминающиеся мелодии, спасло меня от упорных ошибок. (Хотя не все, как могут утверждать мои редакторы.) Когда два года спустя дебютировал «рок Конституции», он помог мне преуспеть в изучении обществознания в седьмом классе.Я до сих пор помню, что тест просил нас написать слова в преамбуле; Я слышал, как почти все в классе пели эту песню, пока мы писали слова.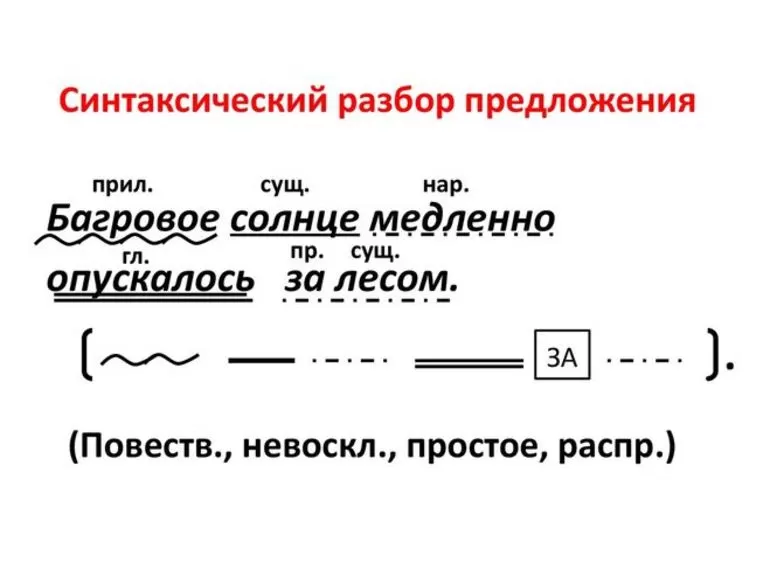

 Прямой объект стоит на одной строке с существительным и глаголом.
Прямой объект стоит на одной строке с существительным и глаголом. Например, «Вы можете сделать подарок своему другу», в котором «подарок» — это прямой объект, который дается «другу», который действует как косвенный объект. Таким образом, глагол «давать» принимает как прямой, так и косвенный объект. Косвенный объект будет показан на диаграмме предложения диагональной линией, отходящей от глагола.
Например, «Вы можете сделать подарок своему другу», в котором «подарок» — это прямой объект, который дается «другу», который действует как косвенный объект. Таким образом, глагол «давать» принимает как прямой, так и косвенный объект. Косвенный объект будет показан на диаграмме предложения диагональной линией, отходящей от глагола.
 Сама эта предложная фраза видоизменяется предложной фразой «этой окончательной неудачи», которая изображена в виде диагональной линии от двойного объекта.
Сама эта предложная фраза видоизменяется предложной фразой «этой окончательной неудачи», которая изображена в виде диагональной линии от двойного объекта. Рассмотрение их как многослойных диаграмм становится еще одним способом оценить гениев, стоящих за этими словами.
Рассмотрение их как многослойных диаграмм становится еще одним способом оценить гениев, стоящих за этими словами. часовой версии фильма, транслируемой правительством Северной Кореи.
часовой версии фильма, транслируемой правительством Северной Кореи. код, в конечном счете. Но синтаксический анализ тоже прошел некоторое расстояние.
код, в конечном счете. Но синтаксический анализ тоже прошел некоторое расстояние. Обозреватель Национального журнала г-жа Карни использовала «синтаксический анализ» аналогичным образом, но контекст подсказывает решение, основанное на классификации: Уловка мистера Рейда либо конституционна, либо нет.
Обозреватель Национального журнала г-жа Карни использовала «синтаксический анализ» аналогичным образом, но контекст подсказывает решение, основанное на классификации: Уловка мистера Рейда либо конституционна, либо нет. Но не просто смейтесь (или стоните) над названием, то, что Google дает разработчикам и исследователям, — это большое дело. Сегодня он открывает исходный код того, что он называет SyntaxNet, и компонента для него, мистер МакПарсфейс. Это некоторые из инструментов, которые Google использует для понимания естественного языка, когда вы вводите его в поле или разговариваете с Google Now.
Но не просто смейтесь (или стоните) над названием, то, что Google дает разработчикам и исследователям, — это большое дело. Сегодня он открывает исходный код того, что он называет SyntaxNet, и компонента для него, мистер МакПарсфейс. Это некоторые из инструментов, которые Google использует для понимания естественного языка, когда вы вводите его в поле или разговариваете с Google Now. В качестве простого примера вы можете сказать: «Дайте мне время в Париже». В зависимости от того, как вы разбираете это предложение, оно может означать «Скажите мне, который час в Париже» или может означать «Когда я буду в Париже, скажите мне, который час». Возможность даже определить, какое из этих значений является предполагаемым, является сверхсложным процессом для компьютера, и он не может даже запуститься, если не сможет проанализировать различные грамматические части предложения.
В качестве простого примера вы можете сказать: «Дайте мне время в Париже». В зависимости от того, как вы разбираете это предложение, оно может означать «Скажите мне, который час в Париже» или может означать «Когда я буду в Париже, скажите мне, который час». Возможность даже определить, какое из этих значений является предполагаемым, является сверхсложным процессом для компьютера, и он не может даже запуститься, если не сможет проанализировать различные грамматические части предложения. Google сообщает, что «выпуск включает в себя весь код, необходимый для обучения новых моделей SyntaxNet на ваших собственных данных, а также Parsey McParseface, анализатор английского языка, который мы подготовили для вас и который вы можете использовать для анализа английского текста.«
Google сообщает, что «выпуск включает в себя весь код, необходимый для обучения новых моделей SyntaxNet на ваших собственных данных, а также Parsey McParseface, анализатор английского языка, который мы подготовили для вас и который вы можете использовать для анализа английского текста.«
 load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
печать (токен.текст, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
печать (токен.текст, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
 K.
K.
 морф
морф 
 nlp = spacy.load ("en_core_web_sm")
lemmatizer = nlp.get_pipe ("лемматизатор")
печать (лемматизатор.Режим)
doc = nlp («Я читал газету.»)
print ([token.lemma_ для токена в документе])
nlp = spacy.load ("en_core_web_sm")
lemmatizer = nlp.get_pipe ("лемматизатор")
печать (лемматизатор.Режим)
doc = nlp («Я читал газету.»)
print ([token.lemma_ для токена в документе])

 Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
приобретен из WordNet.
Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
приобретен из WordNet. Вы можете представить себе существительное как существительное плюс слова, описывающие существительное.
— например, «пышная зеленая трава» или «крупнейший в мире технологический фонд». К
получить куски существительного в документе, просто перебрать
Вы можете представить себе существительное как существительное плюс слова, описывающие существительное.
— например, «пышная зеленая трава» или «крупнейший в мире технологический фонд». К
получить куски существительного в документе, просто перебрать 
 nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
для токена в документе:
print (token.text, token.dep_, token.head.text, token.head.pos_,
[ребенок для ребенка в жетоне.дети])
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
для токена в документе:
print (token.text, token.dep_, token.head.text, token.head.pos_,
[ребенок для ребенка в жетоне.дети])
 Таким образом, вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ сопоставить дугу
проценты - снизу:
Таким образом, вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ сопоставить дугу
проценты - снизу: children
children