Пример синтаксического разбора простого и сложного предложения
Найти:вернуться на стр. “Синтаксический и пунктуационный разбор в табл.“ перейти на стр.
«Образцы разбора простых предложений»
Схема синтаксического разбора предложения (разбор под цифрой 4)
I. Разобрать предложение по членам
II. Разделить предложение (если предложение сложное) на части, пронумеровать части по порядку.
III. Сделать описательный разбор (всего предложения) по следующей схеме:
По цели высказывания:
– повествовательное (.),
– вопросительное (?),
– побудительное (глагол стоит в повелительном наклонении, выражает просьбу, приказ).
По интонации:
По количеству грамматических основ:
1) простое (одна грамматическая основа – одно подл.+ сказ),
2) сложное:
По наличию одного или обоих главных членов (в сложном предложении каждого простого предложения):
1) двусоставное (есть и подлежащее, и сказуемое).
2) односоставное (есть только один главный член предложения) с главным членом
По наличию второстепенных членов:
– нераспространённое (только главные члены).

По наличию пропущенных членов:
– полное,
– неполное (указать, какой член / члены предложения пропущен).
По наличию осложняющих членов:
1) неосложнённое,
2) осложнённое
Предлоги не могут выступать как самостоятельные члены предложения, однако они употребляются в составе предложно-падежной группы, совместно с формой падежа выражая определенное значение. Поэтому предлог принято подчеркивать вместе с существительным, к которому он относится. При этом необходимо обратить внимание на случаи, когда предлог и существительное разделены прилагательными или причастиями, например:
Устный разбор предложения «Деревня, где скучал Евгений, была прелестный уголок».
Предложение повествовательное, невосклицательное, сложноподчиненное; в составе две предикативные части, придаточная часть относится к подлежащему «деревня», присоединяется к главной части при помощи союзного глова где, отвечает на вопрос какая?; придаточная определительная.
Письменный разбор: повеств., невоскл., СПП; 2 предикативн. части, ср-во связи с.сл. где; придаточн. определительная. 1 ч.: двусост., г/о деревня была прелестный уголок, нераспр., полн., неосложн. 2 ч.: двусост., г/о скучал Евгений, распр., полн., неосложн.
какая?
[ -, (где = -)=].
Остались вопросы — задай в обсуждениях https://vk.com/board41801109
Усвоил тему — поделись с друзьями.
Тест на тему Сложное предложение
Контрольный тест по синтаксису
Контрольный тест по пунктуации
#обсуждения_русский_язык_без_проблем
вернуться на стр. “Синтаксический и пунктуационный разбор в табл. “ перейти на стр.
“ перейти на стр.
Синтаксический разбор простого предложения
Синтаксический разбор простого предложения прочно вошёл в практику начальной и средней школы. Это самый трудный и объёмный вид грамматического разбора. Он включает характеристику и схему предложения, разбор по членам с указанием частей речи.
Строение и значение простого предложения изучается начиная с 5 класса. Полный набор признаков простого предложения обозначается в 8 классе, а в 9 классе основное внимание уделяется сложным предложениям.
В этом виде разбора соотносятся уровни морфологии и синтаксиса: ученик должен уметь определять части речи, узнавать их формы, находить союзы, понимать способы связи слов в словосочетании, знать признаки главных и второстепенных членов предложения.
Начнём с самого простого: поможем ребятам подготовиться к выполнению синтаксического разбора в 5 классе. В начальной школе ученик запоминает последовательность разбора и выполняет его на элементарном уровне, указывая грамматическую основу, синтаксические связи между словами, вид предложения по составу и цели высказывания, учится составлять схемы и находить однородные члены.
В начальной школе используются разные программы по русскому языку, поэтому уровень требований и подготовка учащихся разные. В пятом классе я принимала детей, обучавшихся в начальной школе по программам образовательной системы «Школа 2100», «Школа России» и «Начальная школа XXI века». Отличия есть и большие. Учителя начальной школы проделывают колоссальную работу, чтобы компенсировать недостатки своих учебников, и сами «прокладывают» преемственные связи между начальной и средней школой.
В 5 классе материал по разбору предложения обобщается, расширяется и выстраивается в более полную форму, в 6-7 классах совершенствуется с учётом вновь изученных морфологических единиц (глагольные формы: причастие и деепричастие; наречие и категория состояния; служебные слова: предлоги, союзы и частицы).
Покажем на примерах отличия между уровнем требований в формате синтаксического разбора.
|
В 4 классе |
В 5 классе |
В простом предложении выделяется грамматическая основа, над словами обозначаются знакомые части речи, подчёркиваются однородные члены, выписываются словосочетания или рисуются синтаксические связи между словами. Сущ.(главное слово)+прил., Гл.(главное слово)+сущ. Гл.(главное слово)+мест. Нареч.+гл.(главное слово) |
Синтаксические связи не рисуются, словосочетания не выписываются, схема и основные обозначения такие же, но характеристика иная: повествовательное, невосклицательное, простое, двусоставное, распространённое, осложнено однородными сказуемыми. Разбор постоянно отрабатывается на уроках и участвует в грамматических заданиях контрольных диктантов. |
|
В сложном предложении подчёркиваются грамматические основы, нумеруются части, над словами подписываются знакомые части речи, указывается вид по цели высказывания и эмоциональной окраске, по составу и наличию второстепенных членов. Схема разбора: [О и О]1, [ ]2, и [ ]3. |
Схема остаётся той же, но характеристика иная: повествовательное, невосклицательное, сложное, состоит из 3 частей, которые связаны бессоюзной и союзной связью, в 1 части есть однородные члены, все части двусоставные и распространённые. Разбор сложного предложения в 5 классе носит обучающий характер и не является средством контроля. |
|
Схемы предложения с прямой речью: А: «П!» или «П,» — а. Вводится понятие цитаты, совпадающее по оформлению с прямой речью. |
Схемы дополняются разрывом прямой речи словами автора: «П, — а. — П.» и «П, — а, — п». Вводится понятие диалога и способы его оформления. Схемы составляют, но характеристика предложений с прямой речью не производится. |
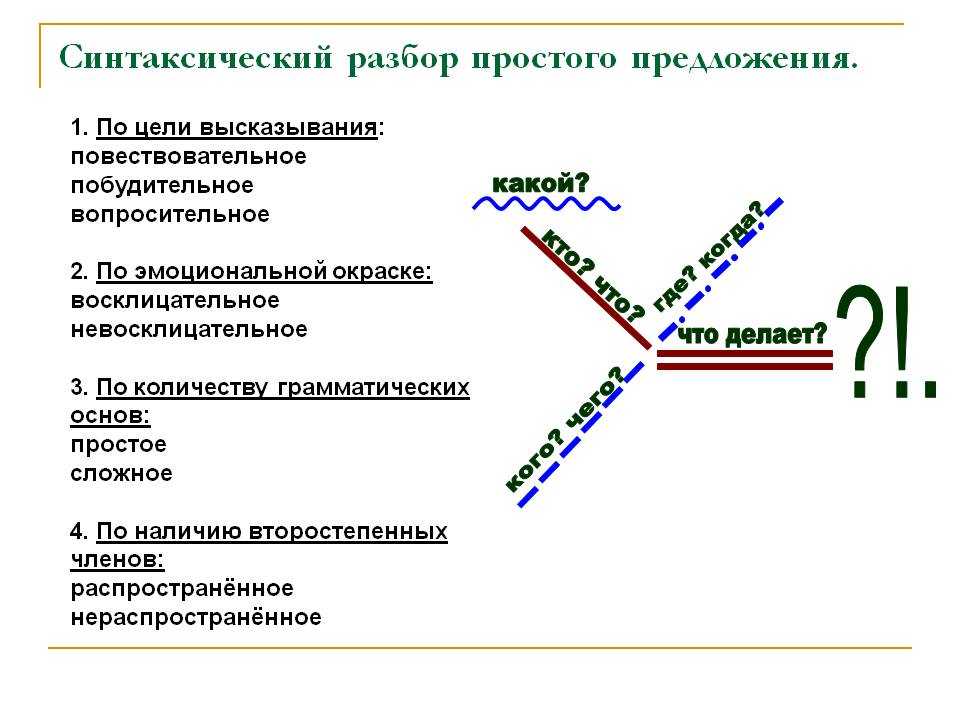 Схема: [О -, О]. Повествовательное, невосклицательное, простое, распространённое, с однородными сказуемыми.
Схема: [О -, О]. Повествовательное, невосклицательное, простое, распространённое, с однородными сказуемыми.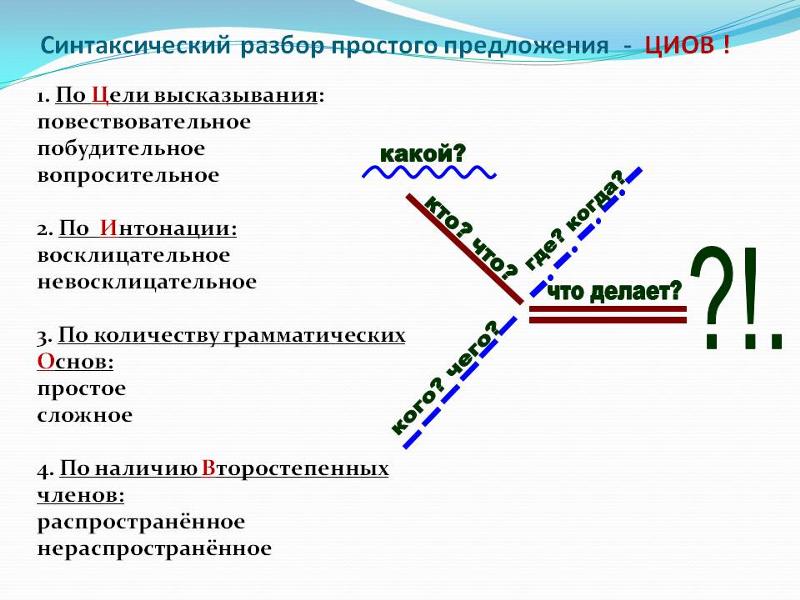
План разбора простого предложения
1. Определить вид предложения по цели высказывания (повествовательное, вопросительное, побудительное).
Определить вид предложения по цели высказывания (повествовательное, вопросительное, побудительное).
2. Выяснить тип предложения по эмоциональной окраске (невосклицательное или восклицательное).
3. Найти грамматическую основу предложения, подчеркнуть её и обозначить способы выражения, указать, что предложение простое.
4. Определить состав главных членов предложения (двусоставное или односоставное).
5. Определить наличие второстепенных членов (распространённое или нераспространённое).
6. Подчеркнуть второстепенные члены предложения, указать способы их выражения (части речи): из состава подлежащего и состава сказуемого.
7. Определить наличие пропущенных членов предложения (полное или неполное).
8. Определить наличие осложнения (осложнено или не осложнено).
9. Записать характеристику предложения.
10. Составить схему предложения.
Для анализа мы использовали предложения из прекрасных сказок Сергея Козлова про Ёжика и Медвежонка.
1) Это был необыкновенный осенний день!
2) Обязанность каждого — трудиться.
3) Тридцать комариков выбежали на поляну и заиграли на своих писклявых скрипках.
4) У него нет ни папы, ни мамы, ни Ёжика, ни Медвежонка.
5) И Белка взяла орешков и чашку и поспешила следом.
6) И они сложили в корзину вещи: грибы, мёд, чайник, чашки — и пошли к реке.
7) И сосновые иголки, и еловые шишки, и даже паутина — все распрямились, заулыбались и затянули изо всех сил последнюю осеннюю песню травы.
8) Ёжик лежал, по самый нос укрытый одеялом, и глядел на Медвежонка тихими глазами.
9) Ёжик сидел на горке под сосной и смотрел на освещённую лунным светом долину, затопленную туманом.
10) За рекой, полыхая осинами, темнел лес.
11) Так до самого вечера они бегали, прыгали, сигали с обрыва и орали во всё горло, оттеняя неподвижность и тишину осеннего леса.
12) И он прыгнул, как настоящий кенгуру.
13) Вода, куда ты бежишь?
14) Может, он с ума сошёл?
15) Мне кажется, он вообразил себя. .. ветром.
.. ветром.
Образцы разбора простых предложений
Скачать образцы разборов в формате .doc 75,5 КБ
- Назад
- Вперед
Золотая полка
- Вы здесь:
- Главная
- Грамматические разборы
- Синтаксический разбор простого предложения
Что такое парсер? Определение, типы и примеры
По
- Бен Луткевич, Технический писатель
В компьютерных технологиях синтаксический анализатор — это программа, которая обычно является частью компилятора. Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Парсеры разбивают входные данные, которые они получают, на такие части, как существительные (объекты), глаголы (методы) и их атрибуты или параметры. Затем они управляются другими программами, такими как другие компоненты компилятора. Синтаксический анализатор также может проверить, были ли предоставлены все необходимые входные данные.
Как работает синтаксический анализ?Синтаксический анализатор — это программа, входящая в состав компилятора, а синтаксический анализ — часть процесса компиляции. Парсинг происходит на этапе анализа компиляции.
При синтаксическом анализе код берется из препроцессора, разбивается на более мелкие части и анализируется, чтобы другое программное обеспечение могло его понять. Синтаксический анализатор делает это, создавая структуру данных из входных данных.
Точнее, человек пишет код на понятном человеку языке, таком как C++ или Java, и сохраняет его в виде набора текстовых файлов. Синтаксический анализатор принимает эти текстовые файлы в качестве входных данных и разбивает их, чтобы их можно было перевести на целевую платформу.
Анализатор состоит из трех компонентов, каждый из которых обрабатывает разные этапы процесса анализа. Три этапа:
Учитывая набор символов x+z=11, лексический анализатор разделит его на серию токенов и классифицирует их, как показано.Этап 1: Лексический анализ
Лексический анализатор — или сканер — берет код из препроцессора и разбивает его на более мелкие части. Он группирует входной код в последовательности символов, называемые лексемами, каждая из которых соответствует токену. Токены — это единицы грамматики языка программирования, понятные компилятору.
Лексические анализаторы также удаляют пробельные символы, комментарии и ошибки из ввода.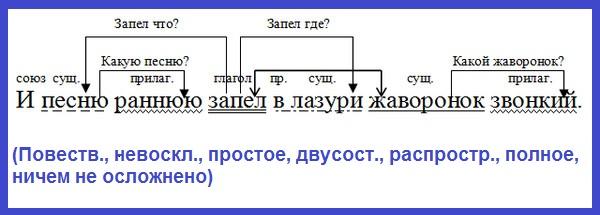
Этап 2: синтаксический анализ
Синтаксический анализатор принимает (x+y)*3 в качестве входных данных и возвращает это дерево синтаксического анализа, которое позволяет синтаксическому анализатору понять уравнение.На этом этапе синтаксического анализа проверяется синтаксическая структура ввода с использованием структуры данных, называемой деревом синтаксического анализа или деревом вывода. Анализатор синтаксиса использует маркеры для построения дерева синтаксического анализа, которое объединяет предопределенную грамматику языка программирования с маркерами входной строки. Синтаксический анализатор сообщает о синтаксической ошибке, если синтаксис неверен.
Этап 3: Семантический анализ
Семантический анализ сверяет дерево синтаксического анализа с таблицей символов и определяет, является ли оно семантически непротиворечивым. Этот процесс также известен как контекстно-зависимый анализ. Он включает проверку типов данных, проверку меток и проверку управления потоком.
Если предоставлен код:
с плавающей запятой а = 30,2; число с плавающей запятой b = a*20
, то анализатор будет рассматривать 20 как 20.0 перед выполнением операции.
Некоторые источники называют синтаксическим анализом только стадию синтаксического анализа, поскольку она генерирует дерево синтаксического анализа. Они не учитывают лексический и семантический анализ.
Синтаксический анализ происходит на первых трех этапах процесса компиляции — лексическом, синтаксисе и семантическом анализе. Какие существуют основные типы парсеров?При создании языка программного обеспечения его создатели должны указать набор правил. Эти правила обеспечивают грамматику, необходимую для построения правильных операторов языка.
Ниже приведен набор грамматических правил для простого вымышленного языка, который содержит всего несколько слов:
<предложение> ::= <субъект> <глагол> <объект>
<тема> ::= <статья> <существительное>
<статья> ::= the | a
<существительное> ::= собака | кошка | человек
<глагол> ::= домашние животные | fed
<объект> ::= <статья> <существительное>
В этом языке предложение должно содержать подлежащее, глагол и существительное в указанном порядке, а отдельные слова должны соответствовать частям речи. Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только домашних животных или накормленных .
Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только домашних животных или накормленных .
Синтаксический анализ проверяет оператор, предоставленный пользователем в качестве входных данных, на соответствие этим правилам, чтобы доказать, что оператор действителен. Разные алгоритмы парсинга проверяют в разном порядке. Существует два основных типа парсеров:
- Нисходящие парсеры. Они начинаются с правила вверху, например <предложение> ::= <субъект> <глагол> <объект>. Имея входную строку «Человек накормил кошку», синтаксический анализатор просматривает первое правило и просматривает все правила, проверяя их правильность. В этом случае первое слово — это
, оно следует правилу подлежащего, и синтаксический анализатор продолжит чтение предложения в поисках . - Парсеры «снизу вверх».
 Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
Проще говоря, нисходящие синтаксические анализаторы начинают свою работу с начального символа грамматики в верхней части дерева синтаксического анализа. Затем они продвигаются вниз от правила к предложению. Синтаксические анализаторы снизу вверх работают от предложения к правилу.
Помимо этих типов важно знать два типа деривации. Вывод — это порядок, в котором грамматика согласовывает входную строку. Их:
- Парсеры LL . Они анализируют входные данные слева направо, используя крайнее левое производное, чтобы сопоставить правила грамматики с входными данными. Этот процесс выводит строку, которая проверяет ввод, расширяя крайний левый элемент дерева синтаксического анализа.
- LR-парсеры . Эти входные данные анализируются слева направо, используя самое правое производное.
 Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Кроме того, существуют другие типы парсеров, в том числе следующие:
- Парсеры рекурсивного спуска. Парсеры рекурсивного спуска возвращаются после каждой точки решения, чтобы перепроверить точность. Парсеры рекурсивного спуска используют синтаксический анализ сверху вниз.
- Парсеры Эрли. Они анализируют все контекстно-свободные грамматики, в отличие от парсеров LL и LR. Большинство реальных языков программирования не используют контекстно-свободные грамматики.
- Парсеры Shift-reduce. Сдвигают и сокращают входную строку. На каждом этапе строки они сокращают слово до правила грамматики. Этот подход уменьшает строку до тех пор, пока она не будет полностью проверена.
Парсеры используются, когда необходимо абстрактно представить входные данные из исходного кода в виде структуры данных, чтобы их можно было проверить на правильность синтаксиса. Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.
Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.
К технологиям, использующим синтаксический анализ для проверки входных данных кода, относятся следующие:
Языки программирования. Парсеры используются во всех языках программирования высокого уровня, включая следующие:
- С++
- Расширяемый язык разметки или XML
- Язык гипертекстовой разметки или HTML
- Препроцессор гипертекста или PHP
- Ява
- JavaScript
- Обозначение объекта JavaScript или JSON
- Перл
- Питон
Языки баз данных. Языки баз данных, такие как язык структурированных запросов, также используют синтаксические анализаторы.
Протоколы . Такие протоколы, как протокол передачи гипертекста и удаленные вызовы функций через Интернет, используют синтаксические анализаторы.
Генератор парсеров . Генераторы синтаксического анализа принимают грамматику в качестве входных данных и генерируют исходный код, который выполняет синтаксический анализ в обратном порядке. Они создают синтаксические анализаторы из регулярных выражений, которые представляют собой специальные строки, используемые для управления и сопоставления шаблонов в тексте.
Синтаксический анализ — это фундаментальная концепция разработки программного обеспечения и теории вычислений. Однако большинство ИТ-специалистов могут обойтись без глубокого понимания синтаксического анализа, используя платформы с низким кодом, которые позволяют пользователям создавать программы без написания тысяч строк кода. Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Последнее обновление: июль 2022 г.
Продолжить чтение О парсере- Памятка Terraform: известные команды, HCL и многое другое
- Как стать хорошим Java-программистом без диплома
- Интерпретируемые и компилируемые языки: в чем разница?
- Исправление 10 самых распространенных ошибок времени компиляции в Java
- 7 советов по выбору правильной библиотеки Java
Надежная архитектура бизнес-процессов требует ключевых характеристик
командлет
Автор: Стивен Бигелоу
Тренировка против тренировки
Субъект – согласование глагола и фраза в скобках
ПоискSoftwareQuality
- Обзор тестирования API на основе данных
Тестирование API, включая тестирование API на основе данных, отличается от других тестов программного обеспечения своим общим процессом и соответствующими показателями.
 ..
.. - Разработчики предупредили: код GitHub Copilot может быть лицензионным
Вопросы связаны с использованием GitHub Copilot открытого исходного кода, но это решение Верховного суда по искусству Уорхола, которое разработчики…
- Развертывание Oracle CloudWorld включает новые бессерверные варианты
Новые бессерверные предложения Oracle Cloud Infrastructure скрывают больше кровавых подробностей инфраструктуры от разработчиков приложений до …
SearchCloudComputing
- С помощью этого руководства настройте базовый рабочий процесс AWS Batch
AWS Batch позволяет разработчикам запускать тысячи пакетов в AWS. Следуйте этому руководству, чтобы настроить этот сервис, создать свой собственный…
- Партнеры Oracle теперь могут продавать Oracle Cloud как свои собственные
Alloy, новая инфраструктурная платформа, позволяет партнерам и аффилированным с Oracle предприятиям перепродавать OCI клиентам в регулируемых .
 ..
.. - Dell добавляет Project Frontier для периферии, расширяет гиперконвергентную инфраструктуру с помощью Azure
На этой неделе Dell представила новости на отдельных мероприятиях — одно из которых демонстрировало программное обеспечение для управления периферией, а другое — углубление гиперконвергентной …
TheServerSide.com
- Владелец продукта и менеджер продукта: в чем разница?
Работа менеджера по продукту в компании сильно отличается от роли владельца продукта в команде Scrum. Узнать ключ…
- Введение в викторину Scrum
Хотите подтвердить свои знания Scrum? Ответьте на 10 вопросов по введению в Scrum и узнайте, насколько хорошо вы знаете Scrum…
- 10 сложных вопросов викторины Scrum Master
Вот сложная викторина из 10 вопросов для Scrum Master, чтобы проверить, насколько хорошо вы знаете обязанности этой важной роли Scrum .
 ..
..
Что такое парсинг данных? | ScrapingBee
Анализ данных — это процесс получения данных в одном формате и преобразования их в другой формат. Вы найдете синтаксические анализаторы, используемые повсюду. Они обычно используются в компиляторах, когда нам нужно проанализировать компьютерный код и сгенерировать машинный код.
Это происходит постоянно, когда разработчики пишут код, который запускается на оборудовании. Парсеры также присутствуют в механизмах SQL. Механизмы SQL анализируют запрос SQL, выполняют его и возвращают результаты.
В случае парсинга веб-страниц это обычно происходит после извлечения данных с веб-страницы посредством парсинга веб-страниц. После того, как вы собрали данные из Интернета, следующим шагом будет сделать их более читабельными и удобными для анализа, чтобы ваша команда могла эффективно использовать результаты.
Хороший анализатор данных не ограничен определенными форматами. Вы должны иметь возможность вводить данные любого типа и выводить данные другого типа. Это может означать преобразование необработанного HTML в объект JSON или они могут взять данные, извлеченные со страниц, отображаемых на JavaScript, и преобразовать их в всеобъемлющий файл CSV.
Это может означать преобразование необработанного HTML в объект JSON или они могут взять данные, извлеченные со страниц, отображаемых на JavaScript, и преобразовать их в всеобъемлющий файл CSV.
Парсеры активно используются при очистке веб-страниц, потому что получаемый нами необработанный HTML-код нелегко понять. Нам нужно преобразовать данные в формат, понятный человеку. Это может означать создание отчетов из строк HTML или создание таблиц для отображения наиболее актуальной информации.
Несмотря на то, что синтаксические анализаторы можно использовать по-разному, в этой статье блога основное внимание будет уделено синтаксическому анализу данных для веб-скрапинга, поскольку это онлайн-активность, с которой ежедневно сталкиваются тысячи людей.
Как создать анализатор данных
Независимо от того, какой тип анализатора данных вы выберете, хороший анализатор выяснит, какая информация из строки HTML полезна, и основываясь на заранее определенных правилах. Процесс синтаксического анализа обычно состоит из двух этапов: лексического анализа и синтаксического анализа.
Лексический анализ — это первый шаг в анализе данных. По сути, он создает токены из последовательности символов, которые поступают в синтаксический анализатор в виде строки неструктурированных данных, таких как HTML. Синтаксический анализатор создает токены, используя лексические единицы, такие как ключевые слова и разделители. Он также игнорирует ненужную информацию, такую как пробелы и комментарии.
После того, как синтаксический анализатор разделил данные между лексическими единицами и нерелевантной информацией, он отбрасывает всю нерелевантную информацию и передает релевантную информацию на следующий шаг.
Следующей частью процесса разбора данных является синтаксический анализ. Здесь происходит построение дерева синтаксического анализа. Синтаксический анализатор берет соответствующие токены из шага лексического анализа и упорядочивает их в виде дерева. Любые дополнительные нерелевантные токены, такие как точки с запятой и фигурные скобки, добавляются к вложенной структуре дерева.
После завершения анализа дерева у вас останется соответствующая информация в структурированном формате, который можно сохранить в файле любого типа. Существует несколько различных способов создания анализатора данных, от создания его программно до использования существующих инструментов. Это зависит от потребностей вашего бизнеса, количества времени, вашего бюджета и некоторых других факторов.
Для начала давайте взглянем на библиотеки парсинга HTML.
Библиотеки синтаксического анализа HTML
Библиотеки синтаксического анализа HTML отлично подходят для добавления автоматизации в ваш процесс парсинга веб-страниц. Вы можете подключить многие из этих библиотек к парсеру через вызовы API и анализировать данные по мере их получения.
Вот несколько популярных библиотек для разбора HTML:
Scrapy или BeautifulSoup
Это библиотеки, написанные на Python. BeautifulSoup — это библиотека Python для извлечения данных из файлов HTML и XML. Scrapy — это парсер данных, который также можно использовать для парсинга веб-страниц. Когда дело доходит до парсинга веб-страниц с помощью Python, доступно множество вариантов, и все зависит от того, насколько практичным вы хотите быть.
Когда дело доходит до парсинга веб-страниц с помощью Python, доступно множество вариантов, и все зависит от того, насколько практичным вы хотите быть.
Cheerio
Если вы привыкли работать с Javascript, вам подойдет Cheerio. Он анализирует разметку и предоставляет API для управления результирующей структурой данных. Вы также можете использовать Puppeteer. Это можно использовать для создания снимков экрана и PDF-файлов определенных страниц, которые можно сохранить и в дальнейшем анализировать с помощью других инструментов. Существует множество других веб-скраперов и веб-парсеров на основе JavaScript.
JSoup
Для тех, кто в основном работает с Java, также есть варианты. JSoup — один из вариантов. Он позволяет вам работать с реальным HTML через свой API для извлечения URL-адресов, извлечения и обработки данных. Он действует как веб-скребок и веб-парсер. Может быть сложно найти другие варианты Java с открытым исходным кодом, но это определенно стоит посмотреть.
Nokogiri
Также есть вариант для Ruby. Взгляните на Нокогири. Это позволяет вам работать с HTML и HTML с Ruby. У него есть API, аналогичный другим пакетам на других языках, который позволяет вам запрашивать данные, которые вы извлекли из веб-скрейпинга. Он добавляет дополнительный уровень безопасности, поскольку по умолчанию считает все документы ненадежными. Анализ данных в Ruby может быть сложным, так как бывает сложнее найти драгоценные камни, с которыми можно работать.
Регулярное выражение
Теперь, когда у вас есть представление о том, какие библиотеки доступны для ваших потребностей в веб-скрапинге и анализе данных, давайте рассмотрим распространенную проблему с анализом HTML — регулярные выражения. Иногда данные плохо отформатированы внутри тега HTML, и нам нужно использовать регулярные выражения для извлечения нужных данных.
Вы можете создавать регулярные выражения, чтобы получить именно то, что вам нужно, из сложных данных. Такие инструменты, как regex101, могут быть простым способом проверить, правильно ли вы ориентируетесь на данные или нет.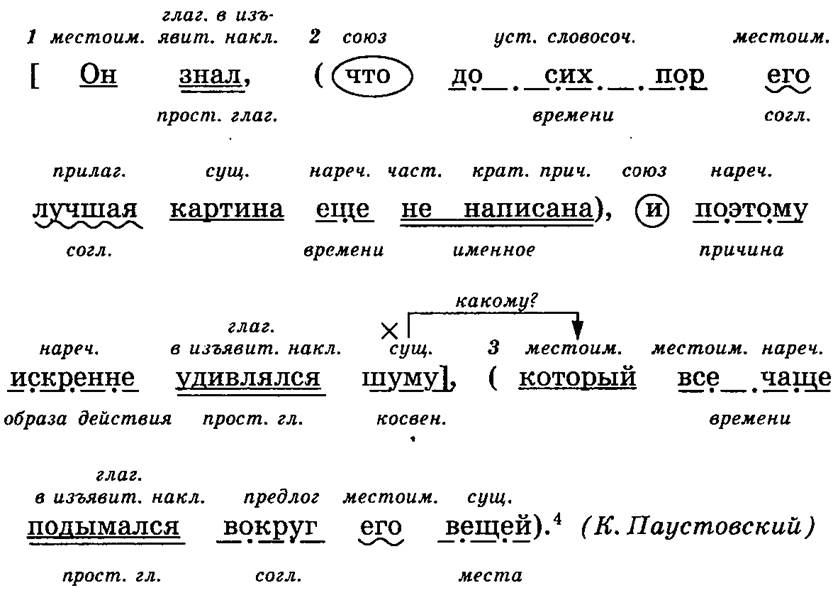 Например, вы можете захотеть получить данные конкретно из всех тегов абзаца на веб-странице. Это регулярное выражение может выглядеть примерно так:
Например, вы можете захотеть получить данные конкретно из всех тегов абзаца на веб-странице. Это регулярное выражение может выглядеть примерно так:
(.*)<\/p>/ /
Синтаксис регулярных выражений немного меняется в зависимости от того, с каким языком программирования вы работаете. В большинстве случаев, если вы работаете с одной из перечисленных выше библиотек или чем-то подобным, вам не придется беспокоиться о создании регулярных выражений.
Если вы не заинтересованы в использовании одной из этих библиотек, вы можете подумать о создании собственного синтаксического анализатора. Это может быть сложно, но потенциально стоит затраченных усилий, если вы работаете с очень сложными структурами данных.
Создание собственного синтаксического анализатора
Если вам нужен полный контроль над анализом данных, создание собственного инструмента может оказаться эффективным вариантом. Вот несколько вещей, которые следует учитывать перед созданием собственного парсера.
Пользовательский синтаксический анализатор может быть написан на любом языке программирования, который вам нравится. Вы можете сделать его совместимым с другими используемыми вами инструментами, такими как веб-сканер или веб-скребок, не беспокоясь о проблемах интеграции.
В некоторых случаях создание собственного инструмента может оказаться рентабельным. Если у вас уже есть команда разработчиков, это может быть не слишком сложной задачей для них.
У вас есть детальный контроль над всем. Если вы хотите настроить таргетинг на определенные теги или ключевые слова, вы можете это сделать. Каждый раз, когда вы обновляете свою стратегию, у вас не будет проблем с обновлением анализатора данных.
Хотя, с другой стороны, есть несколько проблем, связанных с созданием собственного парсера.
HTML страниц постоянно меняется. Это может стать проблемой обслуживания для ваших разработчиков. Если вы не предвидите, что ваш инструмент синтаксического анализа станет очень важным для вашего бизнеса, отнимать время от разработки продукта может быть неэффективно.

Создание и поддержка собственного анализатора данных может быть дорогостоящим. Если у вас нет команды разработчиков, вы можете заключить контракт на работу, но это может привести к поэтапным счетам, основанным на почасовых ставках разработчиков. Есть также затраты на повышение квалификации разработчиков, которые плохо знакомы с проектом, поскольку они выясняют, как все работает.
Вам также потребуется купить, создать и поддерживать сервер, на котором будет размещаться ваш собственный парсер. Он должен быть достаточно быстрым, чтобы обрабатывать все данные, которые вы отправляете через него, иначе вы можете столкнуться с проблемами последовательного анализа данных. Вам также необходимо убедиться, что сервер остается в безопасности, поскольку вы можете анализировать конфиденциальные данные.
Наличие такого уровня контроля может быть полезным, если синтаксический анализ данных является важной частью вашего бизнеса, в противном случае это может добавить больше сложности, чем необходимо. Есть много причин для создания собственного синтаксического анализатора, просто убедитесь, что он стоит вложений по сравнению с использованием существующего инструмента.
Есть много причин для создания собственного синтаксического анализатора, просто убедитесь, что он стоит вложений по сравнению с использованием существующего инструмента.
Анализ метаданных schema.org
Существует также другой способ анализа веб-данных через схему веб-сайта. Стандарты веб-схем управляются schema.org, сообществом, которое продвигает схемы для структурированных данных в Интернете. Веб-схема используется, чтобы помочь поисковым системам понять информацию на веб-страницах и обеспечить лучшие результаты.
Есть много практических причин, по которым люди хотят анализировать метаданные схемы. Например, компании могут захотеть проанализировать схему продукта электронной коммерции, чтобы найти обновленные цены или описания. Журналисты могли анализировать определенные веб-страницы, чтобы получить информацию для своих новостных статей. Существуют также веб-сайты, которые могут собирать такие данные, как рецепты, практические руководства и технические статьи.
Схема бывает разных форматов. Вы услышите о JSON-LD, RDFa и схеме микроданных. Это форматы, которые вы, вероятно, будете анализировать.
JSON-LD — это нотация объектов JavaScript для связанных данных. Это сделано из многомерных массивов. Он реализован с использованием стандартов schema.org с точки зрения SEO. JSON-LD, как правило, проще в реализации, поскольку разметку можно вставлять непосредственно в HTML-документ.
RDFa (Структура описания ресурсов в атрибутах) рекомендуется консорциумом World Wide Web (W3C). Он используется для встраивания операторов RDF в XML и HTML. Одно большое различие между этим и другими типами схем заключается в том, что RDFa определяет только метасинтаксис для семантической маркировки.
Микроданные — это спецификация HTML WHATWG, которая используется для вложения метаданных в существующий контент на веб-страницах. Стандарты микроданных позволяют разработчикам создавать собственный словарь или использовать другие, такие как schema. org.
org.
Все эти типы схем легко анализируются с помощью ряда инструментов на разных языках. Есть библиотека от ScrapingHub, еще одна от RDFLib.
Существующие инструменты анализа данных
Мы рассмотрели ряд существующих инструментов, но есть и другие отличные сервисы. Например, API поиска Google ScrapingBee. Этот инструмент позволяет вам очищать результаты поиска в режиме реального времени, не беспокоясь о времени безотказной работы сервера или обслуживании кода. Вам нужен только ключ API и поисковый запрос, чтобы начать сбор и анализ веб-данных.
Существует множество других инструментов для просмотра веб-страниц, таких как JSoup, Puppeteer, Cheerio или BeautifulSoup.
Несколько преимуществ покупки веб-парсера включают:
- Использование существующего инструмента требует минимального обслуживания.
- Вам не нужно тратить много времени на разработку и настройку.
- У вас будет доступ к службе поддержки, специально обученной использованию и устранению неполадок этого конкретного инструмента.
