Урок, Презентация «Синтаксический разбор сложного предложения»
Технологическая карта урока
Учитель русского языка и литературы Комаровских Надежда Дмитриевна
МОУ СОШ №1 г. Магнитогорска
Класс 5 Предмет русский язык
Тип урока: изучение нового материала.
Вид урока: традиционный
Тема урока: Синтаксический разбор сложного предложения.
Познакомить детей с синтаксическим разбором сложного предложения
Задачи урока
Образовательные: углубить и систематизировать знания о синтаксисе сложного предложения;
• формировать навык синтаксического анализа сложного предложения;
• учить находить грамматические основы, средства связи между частями сложного предложения;
• развивать умение работать со схемой предложения.
Воспитательные: воспитывать любовь к родному языку, умение работать в коллективе.
Развивающие: способствовать самореализации и социализации личности учащихся посредством вовлечения их в активную самостоятельную (поисково-исследовательскую, творческую ) деятельность; прививать интерес пятиклассников к проектной деятельности.
Планируемые результаты
Предметные:
• знать порядок синтаксического разбора сложного
предложения;
• выполнять синтаксический разбор (устный
и письменный) сложного предложения;
• анализировать сложные предложения по совокупности признаков;
• определять основную мысль текста;
• выявлять языковые средства описания предмета
в тексте и описания его действий.
уметь составлять предложения или тексты – миниатюры, включая в них сложные предложения (творческий уровень)
Метапредметные:
регулятивные:
• формировать цели;
• ставить учебную задачу в соответствии с целью
урока;
• определять последовательность действий, работать по плану;
познавательные:
• анализировать, обобщать, классифицировать языковой материал и делать выводы;
коммуникативные:
• взаимодействовать в процессе учебной деятельности;
• высказывать и обосновывать свою точку зрения
Личностные:
• осознавать значимость систематизации в познавательном процессе;
• совершенствовать грамматический строй своей
речи;
• проявлять интерес к созданию собственных высказываний;
• проявлять интерес к чтению.
Основные понятия, используемые на уроке
Сложное предложение, союзное и бессоюзное сложное предложение
Оборудование урока
компьютер, рабочие тетради, презентация, карточки для индивидуальной работы, учебник русского языка для 5 класса (Ладыженская Т.А.)
Формы организации познавательной деятельности учащихся
Фронтальная, в парах, индивидуальная, коллективная (работа над проектом)
Методы обучения
Проблемный, словесный, иллюстративный, деятельностный
Технологии работы с информацией
ИКТ технология. Интерактивная доска (экран), компьютер, мультимедийный проектор
структура
урока
Деятельность учителя
Деятельность учеников
Задания для учащихся, выполнение которых приведёт к достижению запланированных результатов
Прогнозируемые результаты
1.Организационный этап.
Этапы:
1.Приветствие.
2.Эмоциональный настрой уч-ся на работу.
Приветствие.
Организация внимания всех учащихся.
Доброжелательный настрой, полная готовность класса к уроку, быстрое включение класса в деловой ритм.
2.Актуализация знаний уч-ся по теме.
Интеллектуальная разминка
Этапы:
1.Повторение основных сведений о предложении вообще и о сложном в частности.
• Организует и сопровождает деятельность учащихся, Контролирует правильность выполнения заданий
• Организует проверку домашнего задания, актуализирует знания по теме и практические умения разграничивать простые и сложные предложения на основе анализа предложений.
• Предлагает сделать синтаксический и пунктуационный разборы одного из
простых предложений, воспользовавшись планом разбора (§44).
• Отвечают
на вопросы; строят понятные высказывания.
Смотрят презентацию, воспринимают на слух информацию,
• Классифицируют простые и сложные предложения, опираясь на образец
анализа, объясняют расстановку знаков препинания, проверяют правильность выполнения домашнего задания.
• Делают устный и письменный синтаксический разбор предложения, отражают в схеме пунктуацию
Методы и приёмы обучения: опрос, взаимопроверка.
1.Синтаксис изучает (словосочетание, предложение, текст)
Предложения бывают
2 по цели высказывания (повествовательные, побудительные, вопросительные)
3. по эмоциональной окраске (восклицательные и невосклицательные)
4. по количеству грамматических основ (простое и сложное)
5. Если в предложении одна грамматическая основа, то предложение (простое)
Методы и приёмы обучения: работа с интерактивной доской (заполнение схемы)
выборочная проверка упражнения домашнего задания.
учащиеся называют предложения из домашней работы, которые соответствуют схеме:
, и . , когда .
Отвечают на вопросы преподавателя.
Оценивание
работы
3. Целеполагание и мотивация учебной деятельности учащихся.
• Знакомит с темой урока, предлагает подумать, чем синтаксический разбор
сложного предложения отличается от аналогичного разбора простого предложения.
• Просит определить учебную задачу урока, предложить план разбора для систематизации предложений и добиться единства в подходе к анализу предложения.
• Обсуждают вопрос и характеристики сложного и простого предложений, выдвигают предположения по их разбору.
• Определяют учебную задачу урока, предлагают познакомиться с планом разбора в учебнике, сопоставить со своими выводами.
—Что помогает охарактеризовать предложение? (синт.разбор)
Характеристика предложения даётся в ходе (синтаксического разбора)
-Что помогло поставить знаки препинания? (Синтаксический анализ и знание правил пунктуации.)
Итак, ребята, мы с вами определили, что сегодня на уроке будем выполнять синтаксический разбор сложного предложения.
Запишите, пожалуйста, тему урока: «Синтаксический разбор сложного предложения».
-Как вы думаете, чему мы должны научиться на уроке?
Какие будут цели урока?
Сформулировать цели помогут схемы(шаблоны) (Слайд)
1. Учиться выполнять … (синтаксический разбор) сложного предложения и строить …. (схемы)
2. Уметь находить в тексте … (сложное предложение)
— Зачем нам нужно уметь выполнять синтаксический разбор сложного предложения? За 1 минуту убедить своего собеседника в том, что изучение этой темы просто необходимо.
(Чтобы правильно ставить знаки препинания, необходимо четко представлять себе структуру предложения. Осознать ее призван помочь синтаксический разбор, то есть разбор предложения по членам). Также эта работа научит нас анализу.
Предполагаемые итоговые отметки можете сразу выставить карандашом в дневник.
— Как вы думаете, что мы будем делать на уроке? (наблюдение, анализ и вывод из данного наблюдения, тренировочные предложения, самостоятельная работа)
4.Открытие нового знания
Изучение новой темы
• Предлагает прочитать §47, проанализировать порядок и образцы устного
и письменного синтаксического разбора сложного предложения, сравнить со
своими предположениями.
• Обращает внимание на письменный образец, вносит поправки, вставляя пропущенное указание на эмоциональную окраску
предложения, сообщает, что схема сложного предложения является письменной фиксацией пунктуационного разбора.
• Организует и сопровождает деятельность обучающихся, контролирует правильность выполнения заданий
«Корзина идей, понятий»
2.Самостоятельное наблюдение на стр.104, 111-112, п.47
• Изучают порядок разбора сложного предложения, соотносят пункты плана со
своими предположениями, осмысляют и осваивают алгоритм действий, делают акцент на обязательных компонентах разбора.
• Записывают уточнённый
образец письменного разбора, отображают в схеме особенности строения
сложного предложения.
•осознают свои трудности и стремятся к их преодолению
•приобретают новые знания, умения, совершенствуют имеющиеся.
•Познавательные: читают и слушают, извлекая нужную информацию, а также самостоятельно находят ее в материалах учебников
Методы и приёмы обучения: наблюдение, сбор соответствующего материала с последующим его использованием по заданию учителя;
— Попробуем сами вывести план разбора сложного предложения.
-Что вы уже знаете об этой теме? Давайте в «корзину идей» условно соберём все то, что мы знаем об изучаемой теме.
-С разбором какого предложения вы уже знакомы? (с синтаксическим разбором простого предложения)
Методы и приёмы обучения: анализ языковых единиц (синтаксический).
Синтаксический разбор простого предложении. Работа с интерактивной доской
(За) лето р..ка обм..лела прит..илась между б..регами.
(Повеств., невоскл., простое, двусост., распр., осложнено одн. сказ.)
• А теперь подумайте, какие пункты, по-вашему, должен включать синт. р-р СложП?
• Давайте в «корзину идей» условно соберём все то, что мы знаем об изучаемой теме.
-Откройте учебник, вспомните синтаксический разбор простого предложения (с. 104)
1) по цели высказывания
2) по эмоциональной окраске
3) по количеству грамматических основ
• Сверимся с материалами учебника и дополним информацию (с. 111).
4)средства связи
5) знаки препинания
Посмотрите, у нас получилась схема, которой вы можете пользоваться в дальнейшей работе на уроке и дома. кластер вам поможет запомнить порядок синтаксического разбора предложения
кластер вам поможет запомнить порядок синтаксического разбора предложения
-Как вы думаете, чем будут схожи и различны разборы простого и сложного предложений?
Знакомство с порядком синтаксического разбора и памяткой, (выступление представителя группы с проектом разбора).
П а м я т к а
1. Прочитайте предложение.
2. Выделите грамматические основы каждого простого предложения.
3. Пронумеруйте ПП в составе СП.
4. Составьте схему.
5. Определите, какое это предложение по цели высказывания, по эмоциональной окраске, по количеству грамматических основ, по средствам связи.
6. Объясните постановку знаков препинания
Сделайте выводы.
— Что нового вы узнали по теме урока?
— Что показалось сложным, непонятным?
Синтаксический разбор сложного предложения заметно отличается от разбора простого, поэтому в начале анализа вам нужно будет определить, сколько частей входит в состав предложения: одна или несколько.
Уметь производить синтаксический разбор предложения
5.Первичное закрепление
с комментированием
во внешней речи. Самостоятельная работа с самопроверкой по эталону.
•Организует синтаксический разбор упр. 242 с обязательным устным проговариванием и записью выводов.
• Выполняют упражнение по плану разбора, записывают характеристику и схему сложного предложения, сверяют с записью на сладе
Методы и приёмы обучения:
1. Чтение образцов устного и письменного разбора.
Задание: используя памятку, которая лежит перед каждым из вас на парте, произведите синтаксический разбор предложения. Постройте схему.
2. Самостоятельная работа с самопроверкой. Упр. 242. (слайд)
1 вариант – 1 предложение
2 вариант- 2 предложение
составлять предложения; анализировать интонационные конструкции; определять главные члены в предложении
6. Информация о домашнем задании
1 вариант задания. Параграф 47, закрепить порядок синтаксического разбора, выписать из сказок А.С. Пушкина 5 СП., сделать синтаксический разбор сложного предложения.
Параграф 47, закрепить порядок синтаксического разбора, выписать из сказок А.С. Пушкина 5 СП., сделать синтаксический разбор сложного предложения.
2 вариант задания. упр. 243
7. Динамическая пауза
Выполняют элементарные физические упражнения
— Нам пора и погулять
(шагают, высоко поднимая колени)
И друзей с собой позвать.
(шагают, высоко поднимая колени)
Сказуемое – подлежащее, (две руки перед грудью – сказуемое, разводят руки в стороны – подлежащее). Ровной дорогой лежащее. (продолжают это движение).
Вот пунктиром дополнение
(разводят обе руки в стороны отрывистыми движениями)
А волна – определение
(делают движение двумя руками влево — вправо, имитируя движение волны)
— Чёрточка, точка – прыжок
(руками поочерёдно делают движение в сторону – это чёрточка, прыжок– это точка)
— Обстоятельство, дружок!
8. Практическая деятельность Закрепление изученного.
Организует и сопровождает деятельность обучающихся, контролирует правильность выполнения заданий
• Распознавание и анализ объектов. Разбор сложных предложений
• создание собственных письменных текстов, предложений
• работа с худ. текстом
1.Творческое задание Составьте текст, используя и простые, и сложные предложения. Включите в предложения следующие слова: трава- колокольчики –одуванчики – кузнечик. Формы слов сохранить. Текст худ. стиля озаглавить. Сравните собственный получившийся вариант с авторским, из которого эти слова были заимствованы (взяты). 2.Расставить знаки препинания. По данной характеристике найти предложение в тексте. (Повествовательное, невосклицательное, сложное, БСП, состоит из двух ПП.) (работа в парах) На берегу реки. 1)На берегу трава выше колена. 2)Звенят по ветру лиловые колольчики качаются пушистые одуванчики. 3)На листке подорожника сидит большой зелёный кузнечик играет на скрипке. (И. Соколов – Микитов)
(И. Соколов – Микитов)
4.Диагностика достижения планируемых результатов.
дать характеристику предложениям по схемам.
Уметь создавать текст, составлять предложения; анализировать интонационные конструкции; определять главные члены в предложении
9. Рефлексия учебной деятельности
• Организует подведение итогов и рефлексию.
•Подводят итоги, оценивают свою работу на уроке.
СИНТАКСИЧЕСКИЙ РАЗБОР ПО ЧЛЕНАМ ПРЕДЛОЖЕНИЯ |
Обстоятельственные слова never, never once, in vain, no more, little и др. могут помещаться в начале предложения. В таком случае происходит расщепление смыслового глагола путем введения служебного глагола do.
Примеры:
Never did the snowcapped mountains look so beautiful as on that particular morning.
In vain did the boy implore his cruel master to stop beating him. (From an English fairy-tale.)
(From an English fairy-tale.)
Little did he remember after his illness. (Он мало что помнил после своей болезни.)
Примечаниe. Вышеприведенная структура предложений с обстоятельственным словом never является принадлежностью высокого стиля: в языке повседневной жизни усиление значении never производится другими способами.
Например: But you never have been refused yet by anybody, have you?
Возможно помещение обстоятельства образа действия, выраженного наречием, в начале предложения часто с наречием so.
Для того чтобы придать повествованию живость, послелоги, которые указывают на направление и образуют вместе с глаголами, обозначающими движение, составные непереходные глаголы, отрываются от глаголов и помещаются в начале предложения. При этом наблюдается обратный порядок слов.
Примеры:
Away ran the merry children.
Down went the window with a crash.
Up went all the hands.
Прямой порядок слов остается в том случае, если подлежащее выражено местоимением.
Примеры: Away they ran. Down it went. Out he rushed.
Предложения с формальным подлежащим
itВторой способ выделения того или иного члена предложения заключается в том, что этот член предложения превращается в именную часть сказуемого главного предложения при формальном подлежащем it. К именной части сказуемого (т. е. предикативному члену) примыкает предложение, которое вводится словами that, who или бессоюзно. Тем самым простое предложение превращается в сложное предложение особого типа.
Этим способом может выделяться подлежащее, дополнение и обстоятельства.
Например, предложение: The famous Russian explorer Miklukho-Maclay spent more than ten years on New Guinea – может иметь следующие варианты:
It was the famous Russian explorer Miklukho-Maclay who spent more than ten years on New Guinea (выделяется подлежащее).
It was on New Guinea that Miklukho-Maclay spent more than ten years (выделяется обстоятельство места).
It was more than ten years that Miklukho- Maclay spent on New Guinea (выделяется обстоятельство времени).
Другие примеры:
It was here that it happened.
It was on this condition that I went.
It is you that I am talking to.
Примечание. В таких предложениях местоимение it обычно не переводится.
Синтаксический разбор простого словосочетания — Агентство переводов Lingvotech
Синтаксический разбор простого словосочетания
Схема синтаксического разбора простого словосочетания
1. Выделить словосочетание из предложения.
2.Найти главное и зависимое слова, указать, какими частями речи они выражены, поставить вопрос от главного слова к зависимому.
3.Определить тип словосочетания (глагольное, именное или наречное).
4.Определить способ подчинительной связи (согласование, управление, примыкание) и указать, чем она выражена (окончанием зависимого слова, окончанием и предлогом, только по смыслу).
5.Определить смысловые отношения между главным и зависимым словом (определительные, объектные, обстоятельственные).
Образец синтаксического разбора простого словосочетания
Студёный ветер резко рвал полы его шинели (Л. Толстой)
| 1. Студёный ветер х прилаг. + сущ. | именное словосочетание, способ связи — согласование, выражено окончанием зависимого прилагательного, называется предмет и его признак, определительные отношения. |
| 2. Резко рвал — х нареч. + глаг | глагольное словосочетание, способ связи — примыкание, слова связаны по смыслу и интонационно, называется действие и его признак (качество), обстоятельственные отношения. |
| 3. Рвал полы — глаг. +сущ. вВ.п, | глагольное словосочетание, способ связи управление, выражено окончанием зависимого существительного, называется действие и его объект, объектные отношения. |
| 4. Полы шинели — сущ. + сущ. в Р.п | именное словосочетание, способ связи — управление, выражено окончанием зависимого существительного, называется предмет и его признак, определительные отношения. |
Алый свет вечерней зари медленно скользит по корням деревьев (И. Тургенев)
| 1. Алый свет — прилаг. + сущ. | именное словосочетание, способ связи — согласование, выражено окончанием зависимого прилагательного, называется предмет и его признак, определительные отношения. |
| 2. Свет зари — х сущ. + сущ. в Р.п. | именное словосочетание, способ связи — управление, выражено окончанием зависимого существительного, называется предмет и его признак, определительные отношения, |
| 3. Медленно скользит • нар. | глагольное словосочетание, способ связи — примыкание, слова связаны по смыслу и интонационно, называется действие и его признак (качество), обстоятельственные отношения, |
| 4. Скользит по корням • глаг. + сущ. в Д.п. с предлогом по | глагольное словосочетание, «по», способ связи — управление, выражено окончанием зависимого существительного и предлогом «по», называется действие и его место, обстоятельственные отношения. |
 + глаг.
+ глаг.Синтаксический и пунктуационный разбор сложносочиненных предложений
· Сегодня мы вспомним всё, что мы знаем о сложносочинённых предложениях.
· Будем выполнять синтаксический разбор сложносочинённых предложений.
·
И узнаем, как
выполняется пунктуационный разбор сложносочинённых предложений.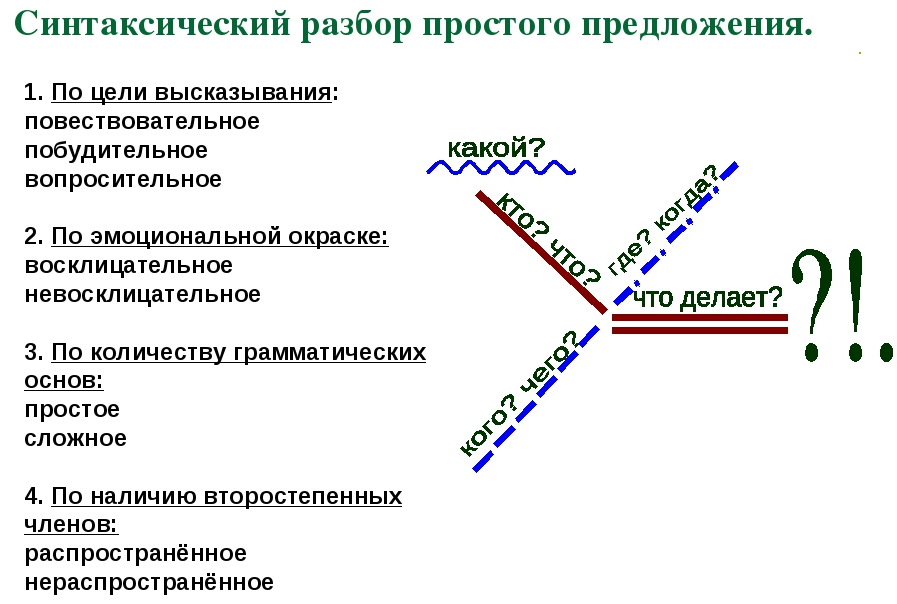
А что вообще такое сложносочинённое предложение? Мы помним, что это − сложное предложение, части которого связаны сочинительными союзами и интонацией.
Сегодня я предлагаю изучать схему синтаксического разбора сложносочиненного предложения методом дедукции. Да-да, прямо как знаменитый сыщик. Наш путь изучения будет немного похож на пазл. А попутно мы будем повторять всю необходимую нам информацию.
Для начала возьмем какое-нибудь предложение.
Прозвенел звонок, и урок начался.
Что нас заинтересует прежде всего? Конечно, самая общая
информация: нужно же выяснить, какое перед нами предложение.
Значит, первое, что мы сделаем – это охарактеризуем всё
сложное предложение. Назовем его вид по цели высказывания
и эмоциональной окрашенности. Ведь именно с этих характеристик мы
обычно и начинаем анализировать любое предложение.
Предложения бывают:
По цели высказывания − повествовательные, вопросительные, побудительные.
По эмоциональной окрашенности – восклицательные и невосклицательные.
И наше предложение повествовательное, потому что в нем рассказывается о событиях. И невосклицательное, потому что нет восклицания.
Какой бы еще элементарный вопрос задать? О, ведь наше предложение – сложное! Интересно было бы увидеть, из чего это сложное предложение состоит.
На втором этапе нашего разбора нужно обозначить предикативные части сложного предложения, выделить их основы.
Отметим первую часть и выделим в ней грамматическую основу: Прозвенел звонок. Отметим вторую часть и выделим грамматическую основу: Урок начался.
Но ведь части в сложном предложении должны чем-то соединяться.
Следующим нашим шагом будет определение
типа связи между частями сложного предложения.
В зависимости от типа связи сложные предложения делятся на бессоюзные – в таком случае части в них связаны только интонацией. И союзные – части связаны союзами и интонацией. Союзные предложения делятся на сложносочинённые и сложноподчинённые.
Бывают также предложения с разными видами связи.
Мы видим, что в нашем предложении части соединяются союзом и и интонацией. Значит, связь союзная.
На схеме мы тоже обозначаем союз.
Но если мы обозначили союз, то сразу же возникает вопрос: а что это за союз? Теперь нам нужно определить его разновидность.
Союзы бывают соединительные – это союзы и, да в значении и, ни… ни, тоже, также.
Противительные – а, но, да в значении но, же, однако, зато, не только… но и.
И
разделительные – или, либо… либо, то… то, не то…
не то, то ли… то ли.
Разумеется, союз и относится к соединительным. И это будет указано в нашем разборе.
А если союз соединительный, то какую функцию он выполняет? Ведь он наверняка служит для установления определенных отношений. Значит, нам нужно определить смысловые отношения между частями нашего сложносочинённого предложения.
Соединительные союзы в сложносочинённом предложении выражают одновременность, последовательность, причину.
Противительные могут выражать сопоставление и противопоставление. А разделительные – взаимоисключение и чередование.
В нашем предложении одновременно прозвенел звонок и начался урок. Поэтому между частями возникают отношения одновременности.
Теперь, когда мы всё сказали о сложном предложении, осталось
охарактеризовать его части. То есть, выполнить синтаксический
разбор каждой части сложного предложения.
То есть, выполнить синтаксический
разбор каждой части сложного предложения.
Характеристики наших частей будут похожи. Первое предложение – повествовательное, невосклицательное, нераспространённое и неосложненное. И второе предложение – повествовательное, невосклицательное, нераспространенное и неосложненное.
В обоих предложениях подлежащее выражено существительным, а сказуемое – глаголом.
Итак, части нашего пазла мы рассмотрели. Теперь нужно собрать картинку воедино.
Катя испекла пирог, а Вера заварила чай.
Пример письменного разбора:
Пример устного разбора:
Предложение повествовательное, невосклицательное. Состоит из
двух простых предложений. В первом грамматическая основа – Катя испекла,
во втором – Вера заварила. Связь между предложениями союзная.
Средство связи – противительный союз а. Смысловые отношения сопоставления.
Следовательно, это предложение сложносочинённое.
Смысловые отношения сопоставления.
Следовательно, это предложение сложносочинённое.
Поговорим теперь о пунктуационном разборе сложносочиненных предложений.
А теперь охарактеризуем знаки препинания в нашем предложении Прозвенел звонок, и урок начался.
В конце предложения ставится знак завершения – точка, так как предложение повествовательное, невосклицательное. Между первым простым предложением (Прозвенел звонок) и вторым (Урок начался) перед союзом и ставится запятая – знак разделения между простыми предложениями в сложносочинённом.
Посмотрите на образец пунктуационного разбора сложносочиненного предложения на примере предложения «Катя испекла пирог, а Вера заварила чай».
Образец письменного разбора:
Образец письменного разбора:
В конце предложения ставится знак завершения – точка, так
как предложение повествовательное, невосклицательное. Между первым простым
предложением (Катя испекла пирог) и вторым (Вера заварила чай) перед союзом а
ставится запятая – знак разделения между простыми предложениями в
сложносочинённом.
Между первым простым
предложением (Катя испекла пирог) и вторым (Вера заварила чай) перед союзом а
ставится запятая – знак разделения между простыми предложениями в
сложносочинённом.
Что же нам требуется запомнить?
А теперь подведём итоги. И для синтаксического, и для пунктуационного разбора сложносочиненного предложения нам нужно сделать следующее:
Первое – обозначить части сложносочиненного предложения.
Второе – подчеркнуть основы.
Третье – обозначить союз.
Четвертое – начертить схему предложения.
Для синтаксического разбора нам еще понадобится:
· Охарактеризовать всё сложносочинённое предложение
· Назвать тип связи.
· Обозначить союз и определить его разновидность.
·
Обозначить отношения между частями.
· После этого выполнить разбор каждой части.
Для пунктуационного разбора нам нужно:
· Охарактеризовать знак в конце сложносочиненного предложения и назвать причину, по которой он там стоит.
· Охарактеризовать знак или знаки между частями сложносочиненного предложения. Назвать функцию каждого знака.
Задание 2 ОГЭ. Практика 2020
Решать ЗАДАНИЕ 2 ОГЭ по русскому языку 2020. СИНТАКСИЧЕСКИЙ АНАЛИЗ.ВАРИАНТ 1. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Перед человечеством стоят глобальные проблемы: рост населения мира, ликвидация социального неравенства, проблемы использования Мирового океана и космического пространства, природных ресурсов и защиты окружающей среды. (2)В связи с этим сотрудничество учёных различных стран призвано сыграть свою роль в решении этих проблем. (3)Говоря о значении научных открытий и изобретений, следует помнить и о возросшей ответственности учёных за будущее человечества. (4)К сожалению, в мире всё больше растёт непонимание места и роли науки, а мистические представления вытесняют целостное научное мировоззрение. (5)Поэтому вопрос о месте науки в общественном сознании, в выработке новых ценностей современного мира становится основным вопросом научного сообщества, системы образования, а также средств массовой информации.
(3)Говоря о значении научных открытий и изобретений, следует помнить и о возросшей ответственности учёных за будущее человечества. (4)К сожалению, в мире всё больше растёт непонимание места и роли науки, а мистические представления вытесняют целостное научное мировоззрение. (5)Поэтому вопрос о месте науки в общественном сознании, в выработке новых ценностей современного мира становится основным вопросом научного сообщества, системы образования, а также средств массовой информации.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 осложнено однородными членами предложения с обобщающим словом.
2) Предложение 2 односоставное безличное.
3) Предложение 3 содержит 2 (две) грамматические основы.
4) Предложение 4 осложнено вводным словом.
5) Предложение 5 сложносочинённое.
14
ВАРИАНТ 2. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Потенциал энергетических ресурсов Мирового океана огромен. (2)Он заключён в энергии морских волн, в суточных приливно-отливных движениях. (3)Суммарная мощность последних на нашей планете оценивается учёными от одного до шести миллиардов киловатт, причём первая из этих цифр намного превышает показатели энергетического потенциала всех рек земного шара. (4)Установлено, что возможности для сооружения крупных приливных электростанций имеются в 25–30 местах. (5)Самыми большими ресурсами приливной энергии обладают Россия, Франция, Канада, Великобритания, Австралия, Аргентина, США.
(2)Он заключён в энергии морских волн, в суточных приливно-отливных движениях. (3)Суммарная мощность последних на нашей планете оценивается учёными от одного до шести миллиардов киловатт, причём первая из этих цифр намного превышает показатели энергетического потенциала всех рек земного шара. (4)Установлено, что возможности для сооружения крупных приливных электростанций имеются в 25–30 местах. (5)Самыми большими ресурсами приливной энергии обладают Россия, Франция, Канада, Великобритания, Австралия, Аргентина, США.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 простое нераспространённое.
2) В предложении 2 составное именное сказуемое.
3) Предложение 3 содержит 2 (две) грамматические основы.
4) Предложение 4 простое, осложнено вводным словом.
5) Предложение 5 осложнено однородными подлежащими.
235
ВАРИАНТ 3. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Хотя диалог обычно противопоставляют монологу, но в таком противопоставлении полюсы неравноправны. (2)Диалог – живая форма общения, он может длиться долго; напротив, монолог – искусственная форма речи, и обычно он длится недолго. (3)Правда, на сцене монолог звучит более естественно, чем в жизни. (4)Это объясняется тем, что, во-первых, сценический монолог предполагает фоном всю пьесу и, во-вторых, сами зрители выступают как бы в роли молчаливого собеседника актёра, произносящего монолог. (5)И всё же известная условность монолога сохраняется и на сцене, чем объясняется его постепенное вытеснение с подмостков: в пьесах нашего времени монолог занимает гораздо более скромное место, чем раньше.
(2)Диалог – живая форма общения, он может длиться долго; напротив, монолог – искусственная форма речи, и обычно он длится недолго. (3)Правда, на сцене монолог звучит более естественно, чем в жизни. (4)Это объясняется тем, что, во-первых, сценический монолог предполагает фоном всю пьесу и, во-вторых, сами зрители выступают как бы в роли молчаливого собеседника актёра, произносящего монолог. (5)И всё же известная условность монолога сохраняется и на сцене, чем объясняется его постепенное вытеснение с подмостков: в пьесах нашего времени монолог занимает гораздо более скромное место, чем раньше.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Первая часть предложения 1 – односоставное неопределённо-личное предложение.
2) Предложение 2 содержит 4 (четыре) грамматические основы.
3) В предложении 3 первая грамматическая основа – правда.
4) Две части предложения 4 осложнены вводными словами.
5) Предложение 5 сложносочинённое.
124
ВАРИАНТ 4. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Кто из нас в детстве не мечтал стать отважным путешественником, чтобы, ступив на неизведанные земли, рассказать затем соотечественникам об открытых таинственных племенах и о своих удивительных, полных романтики и риска приключениях! (2)Путешественник – первооткрыватель, это своеобразный «сталкер» (если пользоваться терминологией Стругацких). (3)Популяризируя новые маршруты, под иным углом показывая старые, он прокладывает путь своим соотечественникам. (4)Это внешняя сторона. (5)Только спустя много лет я уяснил для себя совершенно определённо: путешествие – это не только романтика, но и тяжёлое испытание не столько сил, сколько духа.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 содержит 3 (три) грамматические основы.
2) В предложении 2 грамматическая основа – первооткрыватель.
3) Предложение 3 осложнено однородными обособленными обстоятельствами.
4) Предложение 4 простое.
5) Предложение 5 сложное бессоюзное.
345
ВАРИАНТ 5. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Сегодня грозной опасности подвергается не только биология человека, болезненную остроту приобретают и психологические проблемы. (2)С глубокой древности разрабатывались методы управления человеческим поведением. (3)В ХХ в. возникло убеждение, что возможности манипулирования человеком едва ли не безграничны: с помощью психотропных средств, массовой пропаганды можно запрограммировать человеческое поведение. (4)Вместе с тем рождается предположение, что проникнуть в ядро человеческой психики крайне трудно, а порою и просто невозможно. (5)Даже в состоянии гипноза индивид не переступает пределов ценностных предпочтений, и в глубинах своего сознания он остаётся неизменным, не поддаётся внешнему воздействию.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 сложное бессоюзное.
2) Предложение 2 односоставное неопределённо-личное.
3) В первой части предложения 3 грамматическая основа – возникло убеждение.
4) Предложение 4 сложносочинённое.
5) Вторая часть предложения 5 осложнена однородными членами предложения.
135
ВАРИАНТ 6. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Географическая карта не раз служила подсказкой при выборе имени для вновь открытых химических элементов. (2)Но всё могло быть и по-другому. (3)В XVI веке испанский капитан Себастьян Кабот, плывя вверх по течению реки в Южной Америке, был поражён количеством серебра, которое было у местных индейцев, живших по берегам реки, и решил назвать её Ла-Платой, то есть серебряной (по-испански «плата» – серебро). (4)Отсюда впоследствии произошло и название всей страны. (5)Однако в начале XIX века владычество Испании кончилось, и, чтобы не вспоминать об этом печальном периоде, жители страны латинизировали её название; так на географических картах появилось слово «Аргентина».
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 простое.
2) Предложение 2 односоставное безличное.
3) Одна из частей предложения 3 содержит однородные сказуемые.
4) Грамматическая основа предложения 4 – произошло.
5) Предложение 5 содержит 5 (пять) грамматических основ.
13
ВАРИАНТ 7. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Известно, что сегодня в исследованиях учёных по-разному определяется место грамматики в обучении языку. (2)В одних ей отводится главное место, требуются заучивание правил и постоянная тренировка в образовании форм; в других больше внимания уделяется употреблению речевых образцов, а грамматическим явлениям отводится второе место: правила не надо учить, достаточно практиковаться в анализе образцовых текстов. (3)Как же современная школа относится к данной проблеме? (4)Во-первых, роль грамматики не занижается, но и не преувеличивается; во-вторых, к грамматическим явлениям подходят с позиции понимания сущности языка: язык – речь – коммуникация. (5)Из этого вытекает необходимость анализа не только структуры грамматических единиц, но и функционирования их в речи.
(5)Из этого вытекает необходимость анализа не только структуры грамматических единиц, но и функционирования их в речи.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 сложноподчинённое с придаточным изъяснительным.
2) Предложение 2 сложное.
3) Предложение 3 односоставное безличное.
4) В предложении 4 одна из грамматических основ – позиции подходят.
5) Предложение 5 осложнено однородными членами.
125
ВАРИАНТ 8. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Свечение, возникающее вследствие освещения вещества и быстро затухающее, называют флюоресценцией. (2)Способностью к этому обладают очень многие органические вещества из классов циклических соединений: бензоловые смолы, ароматические вещества и сравнительно небольшая часть неорганических веществ. (3)Так, например, в лучах ультрафиолетовой лампы флюоресцируют органические красители в защитных метках, надписях, волосках на денежных купюрах. (4)Голубое свечение дают бумага и белые ткани, содержащие отбеливатели; красное свечение даёт хлорофилл в листьях растений. (5)Горные породы часто содержат рассеянные органические примеси, дающие голубовато-белёсый фон; именно флюоресцентные «метки» помогают в поиске нефти.
(4)Голубое свечение дают бумага и белые ткани, содержащие отбеливатели; красное свечение даёт хлорофилл в листьях растений. (5)Горные породы часто содержат рассеянные органические примеси, дающие голубовато-белёсый фон; именно флюоресцентные «метки» помогают в поиске нефти.
Какие из перечисленных утверждений являются верными? Укажите номера ответов.
1) Предложение 1 осложнено однородными обособленными определениями, выраженными причастными оборотами.
2) В предложении 2 составное глагольное сказуемое.
3) Предложение 3 односоставное.
4) В предложении 4 есть однородные подлежащие: бумага, ткани, хлорофилл.
5) Первая часть предложения 5 осложнена обособленным определением.
15
ВАРИАНТ 9. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Искусство читать – это искусство чувствовать и мыслить. (2)А научат этому только те книги, в которых настоящая жизнь, благородные чувства, страстные идеи и художественные достоинства. (3)«Вкус развивается не на посредственном, а на самом совершенном материале», – говорил великий немецкий писатель И. Гёте. (4)Выходит, что прежде всего надо воспитать в себе культуру чтения, приучаться к целенаправленности, к системе в выборе книг. (5)Нельзя, чтобы мимо современного человека прошли великие произведения Бунина и Диккенса, Стендаля и Бальзака, Хемингуэя и Распутина, Достоевского и Шекспира.
(3)«Вкус развивается не на посредственном, а на самом совершенном материале», – говорил великий немецкий писатель И. Гёте. (4)Выходит, что прежде всего надо воспитать в себе культуру чтения, приучаться к целенаправленности, к системе в выборе книг. (5)Нельзя, чтобы мимо современного человека прошли великие произведения Бунина и Диккенса, Стендаля и Бальзака, Хемингуэя и Распутина, Достоевского и Шекспира.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 сложное.
2) Первая часть предложения 2 – односоставное неопределённо-личное предложение.
3) Предложение 3 содержит прямую речь.
4) Предложение 4 сложное бессоюзное.
5) Первая часть предложения 5 – односоставное безличное предложение.
35
ВАРИАНТ 10. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Герои Ф.М. Достоевского живут в особом измерении, нисколько не похожем на обычную жизнь обыкновенных людей. (2)Они страдают так мучительно, что читать об этих страданиях больно. (3)Они решают такие важные вопросы жизни и смерти, пользы и бесполезности человеческого существования, любви и долга, счастья и отчаяния, что нам, читателям, трудно представить себя на их месте. (4)Все человеческие чувства доведены у героев Достоевского до высшего напряжения: любовь и страсть, муки ревности, доброта и ненависть, детская наивность и холодное коварство, бескорыстие и расчёт, легкомыслие и тяжкая ответственность долга – всё достигает высшего предела. (5)Читая произведения Достоевского, мы проникаемся состраданием.
(3)Они решают такие важные вопросы жизни и смерти, пользы и бесполезности человеческого существования, любви и долга, счастья и отчаяния, что нам, читателям, трудно представить себя на их месте. (4)Все человеческие чувства доведены у героев Достоевского до высшего напряжения: любовь и страсть, муки ревности, доброта и ненависть, детская наивность и холодное коварство, бескорыстие и расчёт, легкомыслие и тяжкая ответственность долга – всё достигает высшего предела. (5)Читая произведения Достоевского, мы проникаемся состраданием.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) В предложении 1 содержится 2 (две) грамматические основы.
2) Предложение 2 сложноподчинённое с придаточным изъяснительным.
3) Вторая часть предложения 3 осложнена обособленным нераспространённым приложением.
4) В первой части предложения 4 простое глагольное сказуемое.
5) Предложение 5 осложнено обособленным обстоятельством, выраженным деепричастным оборотом.
35
ВАРИАНТ 11. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Проводя научные исследования, Леонардо да Винчи особое внимание уделял механике. (2)Он экспериментально определил коэффициенты трения и пришёл к идее шарикового подшипника. (3)В его эскизах представлены весьма сложные и разнообразные варианты зубчатых передач, которые до сих пор применяются в недорогих устройствах, например в механических будильниках. (4)Кроме того, Леонардо начертил эскизы устройств для преобразования вращательного движения в поступательное и придумал роликовую цепь, которая и сегодня применяется в велосипедах, мотоциклах и множестве других механизмов. (5)Конструирование сложных машин и их элементов привело Леонардо к созданию основ теории передаточных механизмов: пространственных и плоских зубчатых сцеплений, передач с гибкими звеньями и с переменными скоростями вращения.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 осложнено обособленным обстоятельством.
2) Предложение 2 сложносочинённое.
3) В предложении 3 одна из грамматических основ – которые применяются.
4) Предложение 4 содержит 2 (две) грамматические основы.
5) Предложение 5 сложное бессоюзное.
134
ВАРИАНТ 12. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Янтарь (окаменевшая смола хвойных деревьев), потёртый о шерсть, приобретает способность притягивать различные тела. (2)Установлено, что этим свойством обладают и другие предметы: стеклянная палочка, потёртая о шёлк; палочка из органического стекла, потёртая о бумагу; эбонит (каучук с большой примесью серы), потёртый о сукно или мех. (3)Так, если потереть стеклянную палочку о лист бумаги, а затем поднести её к мелко нарезанным листочкам бумаги, то они начнут притягиваться к ней; тонкие струйки воды также будут притягиваться к стеклянной палочке. (4)Наблюдаемые явления в начале XVII в. были названы электрическими (от греческого слова «электрон» – янтарь). (5)Поэтому стали говорить, что тело, получившее после натирания способность притягивать другие тела, наэлектризовано или что ему сообщён электрический заряд.
(5)Поэтому стали говорить, что тело, получившее после натирания способность притягивать другие тела, наэлектризовано или что ему сообщён электрический заряд.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 осложнено обособленным определением, выраженным причастным оборотом.
2) Предложение 2 сложное с бессоюзной и союзной подчинительной связью.
3) Предложение 3 сложноподчинённое.
4) Предложение 4 простое.
5) Предложение 5 содержит 3(три) грамматические основы.
145
ВАРИАНТ 13. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)В научной деятельности перед человеком стоят две основные задачи: добыть новое знание о мире и сделать это знание достоянием общества. (2)Соответственно, выделяются и два этапа в научной деятельности человека: этап совершения открытия и этап оформления открытия, когда возникает необходимость в речевом оформлении нового знания. (3)Поэтому закономерно, что исконной формой существования научной речи стала письменная форма. (4)Во-первых, письменная форма долговременно фиксирует информацию; во-вторых, она более удобна для обнаружения неточностей и логических нарушений; наконец, она не только даёт адресату возможность устанавливать свой личный темп восприятия, но и позволяет многократно обращаться к информации, что также очень важно в научной работе. (5)Устная форма всё-таки часто используется в научном общении, но она вторична: научное произведение сначала пишут, а потом воспроизводят в устной речи.
(4)Во-первых, письменная форма долговременно фиксирует информацию; во-вторых, она более удобна для обнаружения неточностей и логических нарушений; наконец, она не только даёт адресату возможность устанавливать свой личный темп восприятия, но и позволяет многократно обращаться к информации, что также очень важно в научной работе. (5)Устная форма всё-таки часто используется в научном общении, но она вторична: научное произведение сначала пишут, а потом воспроизводят в устной речи.
Какие из перечисленных утверждений являются верными? Укажите номера ответов.
1) В предложении 1 подлежащее – задачи.
2) Предложение 2 сложное с бессоюзной и союзной подчинительной связью.
3) В первой части предложения 3 грамматическая основа – закономерно.
4) В предложении 4 содержится 3 (три) грамматические основы.
5) Предложение 5 сложное с союзной сочинительной и бессоюзной связью.
235
ВАРИАНТ 14. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Давно уже было замечено, что некоторые слова своими звуками как бы изображают то, что называют. (2)Все эти звуки можно разделить на высокие и низкие. (3)Исследования в области звукового символизма показали, что высокие звуки у большинства говорящих вызывают ощущение светлого, а низкие – тёмного; например, такие слова, как свет, жизнь, день, солнце, состоят преимущественно из высоких, а слова омут, боль, шум, кровь, мрак, оковы – из низких звуков. (4)Этим свойством звука – вызывать у большинства людей одинаковые ощущения и образные представления – издавна интуитивно пользовались поэты. (5)В то время как в обычной, нейтральной русской речи низкие и высокие, мягкие и твёрдые звуки встречаются примерно с одинаковой частотой, в поэтических текстах это равновесие нередко сознательно нарушается.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
1) Предложение 1 сложноподчинённое.
2) В предложении 2 грамматическая основа – звуки можно разделить.
3) Предложение 3 содержит неполные предложения.
4) В предложении 4 содержится составное именное сказуемое.
5) Первая часть предложения 5 осложнена однородными членами.
135
ВАРИАНТ 15. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Окружающая среда, в которой существуют живые организмы, постоянно меняется. (2)Многие из этих изменений вызывают серьёзные нарушения в работе органов и систем. (3)Но живые организмы способны защищаться от неблагоприятных воздействий и сохранять стабильность внутренней среды благодаря тому, что они способны адаптироваться. (4)Под адаптацией понимается совокупность всех физиологических реакций, обеспечивающих приспособление строения и функций организма или отдельного органа к изменению окружающей среды. (5)Если бы организм не обладал способностью адаптироваться, изменение условий существования могло бы его погубить.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
Запишите номера ответов.
1) среда постоянно меняется (предложение 1)
2) нарушения вызывают (предложение 2)
3) они способны адаптироваться (предложение 3)
4) понимается приспособление (предложение 4)
5) изменение могло бы погубить (предложение 5)
35
ВАРИАНТ 16. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Самое большое скопление воды на поверхности Земли – это Мировой океан. (2)Материки и острова разделяют его на отдельные океаны, проливы, заливы. (3)Постоянные морские течения связывают его в единое целое, но у каждой его части есть свои особенности. (4)В Мировом океане обычно выделяют четыре океана: Тихий, Атлантический, Индийский и Северный Ледовитый. (5)На некоторых картах отмечен ещё один океан – Южный, который омывает Антарктиду, однако многие учёные отказываются признавать его отдельное существование и обосновывают это целой системой научных доказательств.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
Запишите номера ответов.
1) это Мировой океан (предложение 1)
2) разделяют (предложение 2)
3) части есть (предложение 3)
4) выделяют (предложение 4)
5) учёные отказываются признавать (и) обосновывают (предложение 5)
45
ВАРИАНТ 17. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Культура человека выражается не только в умении говорить, но и в умении слушать. (2)Если даже захочешь возразить собеседнику, терпеливо выслушай его до конца, не перебивай его, возражение может и не понадобиться. (3)Некрасиво выглядит человек, который не умеет владеть собой, грубо перебивает собеседника, пытается подавить его криком, грубым словом, повелительной интонацией. (4)Этим он унижает не только собеседника, но и себя. (5)Убеждай силой логики, фактами, не торопись навязывать своё мнение, уважай мнение собеседника, во время разговора следи за выражением своего лица так же, как и за речью.
Укажите варианты ответов, в которых дано верное утверждение. Запишите номера ответов.
Запишите номера ответов.
1) Предложение 1 сложносочинённое.
2) Предложение 2 сложное с бессоюзной и союзной подчинительной связью.
3) Предложение 3 простое с однородными сказуемыми.
4) Предложение 4 простое нераспространённое.
5) В сложном предложении 5 все части – односоставные определённо-личные.
25
ВАРИАНТ 18. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Общепринятое положение о единых для человека и животных закономерностях эволюции мозга позволяет считать, что эмоции сформировались задолго до появления человека. (2)Именно с таких позиций рассмотрел эмоции Ч. Дарвин, его исследования были систематизированы в работе «Выражение эмоций у человека и животных». (3)Учёным был приведён большой материал по сравнительному анализу мимики, жестов, голосовых и вегетативных реакций при аффективных состояниях человека и у представителей разных отрядов млекопитающих. (4)Выразительные движения Ч. Дарвин рассматривал как сформировавшиеся в процессе естественного отбора приспособительные реакции, существенные для общения с особями своего или других биологических видов. (5)Именно эти исследования привели Дарвина к убеждению, что многие чувства человека, проявляющиеся в мимике и жестах, – результат эволюционного процесса.
(5)Именно эти исследования привели Дарвина к убеждению, что многие чувства человека, проявляющиеся в мимике и жестах, – результат эволюционного процесса.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) эмоции сформировались (предложение 1)
2) исследования были систематизированы (предложение 2)
3) учёным был приведён (предложение 3)
4) реакции рассматривал (предложение 4)
5) исследования – результат (предложение 5)
12
ВАРИАНТ 19. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)В истории человечества есть две формы коммуникации: устная и письменная. (2)Сегодня с появлением Интернета, новой сферы общения, можно утверждать, что появился некий промежуточный тип коммуникации, который в каком-то смысле является письменным (визуальным), а в каком-то – устным. (3)По способу восприятия это, без сомнения, визуальная речь, то есть воспринимаемая глазами. (4)К тому же мы можем делать длительные паузы в процессе интернет-разговора, что недопустимо во время устной беседы, так как «живой» диалог предполагает мгновенные реплики. (5)Итак, технически это письменная речь, а вот с точки зрения структуры используемого в Интернете языка, безусловно, устная.
(4)К тому же мы можем делать длительные паузы в процессе интернет-разговора, что недопустимо во время устной беседы, так как «живой» диалог предполагает мгновенные реплики. (5)Итак, технически это письменная речь, а вот с точки зрения структуры используемого в Интернете языка, безусловно, устная.
Какие из перечисленных утверждений являются верными? Укажите номера ответов.
1) Предложение 1 простое двусоставное.
2) В первой части предложения 2 грамматическая основа – можно утверждать.
3) Предложение 3 односоставное назывное.
4) Предложение 4 сложное.
5) В предложении 5 содержится 3 (три) грамматические основы.
124
ВАРИАНТ 20. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Натуралистов всегда поражала особенность охоты сов: птицы охотятся в темноте на мелких грызунов и вылавливают их немало – десятки за ночь. (2)Может быть, совы разыскивают добычу с помощью какого-нибудь необычного чувства? (3)Некоторые учёные считают, что совы видят инфракрасные лучи, которые излучает тело жертвы. (4)Возможно, что глаза совы улавливают невидимые для нашего зрения инфракрасные, то есть тепловые, лучи. (5)Установлено, что инфракрасные лучи представляют собой тепловое излучение всякого нагретого предмета.
(4)Возможно, что глаза совы улавливают невидимые для нашего зрения инфракрасные, то есть тепловые, лучи. (5)Установлено, что инфракрасные лучи представляют собой тепловое излучение всякого нагретого предмета.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) натуралистов поражала (предложение 1)
2) может быть (предложение 2)
3) считают (предложение 3)
4) возможно (предложение 4)
5) установлено (предложение 5)
45
ВАРИАНТ 21. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)История человека есть история его свободы. (2)Рост человеческой мощи выражается прежде всего в росте свободы. (3)Свобода не есть осознанная необходимость, она прямо противоположна необходимости, свобода есть преодоленная необходимость. (4)Прогресс в основе своей есть прогресс человеческой свободы. (5)Да ведь и сама жизнь есть свобода, эволюция жизни есть эволюция свободы.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) история человека есть (предложение 1)
2) рост человеческой мощи выражается (предложение 2)
3) она противоположна (предложение 3)
4) прогресс есть (предложение 4)
5) жизнь есть свобода (предложение 5)
35
ВАРИАНТ 22. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Среда обитания человека и других живых организмов весьма агрессивна: нас подстерегают всевозможные вирусы и бактерии, ожидающие своего часа, чтобы напасть на нас, и задача нашей иммунной системы — защитить нас от их нападения. (2)Некоторые рубежи обороны — чисто анатомические: например, кожа и слизистые оболочки образуют физический барьер, препятствующий вторжению. (3)Если эти внешние границы нарушены, организм часто противопоставляет агрессии генерализованную воспалительную реакцию, при которой усиливается приток крови к пораженному участку. (4)Кровь доставляет лейкоциты, которые, проникнув через стенку капилляров, захватывают внедрившегося агрессора. (5)Именно такой реакцией объясняется хорошо знакомая нам краснота вокруг небольшого пореза.
(4)Кровь доставляет лейкоциты, которые, проникнув через стенку капилляров, захватывают внедрившегося агрессора. (5)Именно такой реакцией объясняется хорошо знакомая нам краснота вокруг небольшого пореза.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) напасть (предложение 1)
2) слизистые оболочки образуют (предложение 2)
3) границы нарушены (предложение 3)
4) лейкоциты захватывают (предложение 4)
5) краснота объясняется (предложение 5)
135
ВАРИАНТ 23. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1) То, как птицы учатся петь свои песни, во многом сходно с освоением языка ребенком: как и в случае с человеческой речью, птицам необходима «модель для подражания». (2) В естественной среде молодые особи подражают песням взрослых птиц, а без этого они не способны овладеть пением в полной мере. (3) Но развитие речи у человека не сводится к имитации: ключевой момент состоит в том, что ребенок способен следить за реакцией взрослых на свои слова и корректировать речь в соответствии с ней. (4) Теперь же исследователи продемонстрировали, что социальный контекст играет важную роль в освоении песни у зебровой амадины — одного из самых популярных модельных видов в экспериментах этологов. (5) Их исследование позволяет предположить, что этот феномен широко распространен среди певчих воробьиных.
(3) Но развитие речи у человека не сводится к имитации: ключевой момент состоит в том, что ребенок способен следить за реакцией взрослых на свои слова и корректировать речь в соответствии с ней. (4) Теперь же исследователи продемонстрировали, что социальный контекст играет важную роль в освоении песни у зебровой амадины — одного из самых популярных модельных видов в экспериментах этологов. (5) Их исследование позволяет предположить, что этот феномен широко распространен среди певчих воробьиных.
Укажите варианты ответов, в которых верно определены предложения с союзной подчинительной связью. Запишите номера ответов.
1) Предложение 1
2) Предложение 2
3) Предложение 3
4) Предложение 4
5) Предложение 5
1345
ВАРИАНТ 24. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1) Главный источник нагрева атмосферы Земли — энергия Солнца. (2) Эта энергия распределяется по земной поверхности неравномерно — прежде всего из-за того, что в высоких широтах солнечные лучи падают под более острым углом к поверхности планеты. (3) Поэтому, как всем хорошо известно, на экваторе воздух теплее, а над полюсами холоднее. (4) Разница температур между экваториальной и полярными зонами — основная движущая сила атмосферной циркуляции, ответственной за погоду и климат на планете. (5) Количественно эту разницу можно выразить в виде широтного температурного градиента — величины, показывающей, на сколько градусов меняется средняя температура воздуха при смещении на один градус географической широты.
(3) Поэтому, как всем хорошо известно, на экваторе воздух теплее, а над полюсами холоднее. (4) Разница температур между экваториальной и полярными зонами — основная движущая сила атмосферной циркуляции, ответственной за погоду и климат на планете. (5) Количественно эту разницу можно выразить в виде широтного температурного градиента — величины, показывающей, на сколько градусов меняется средняя температура воздуха при смещении на один градус географической широты.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) главный источник — энергия солнца(предложение 1)
2) энергия распределяется (предложение 2)
3) всем известно(предложение 3)
4) разница температур сила — циркуляции(предложение 4)
5) можно выразить (предложение 5)
25
ВАРИАНТ 25. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Согласно центральной догме молекулярной биологии, химическая индивидуальность каждого живого организма определяется последовательностью пар оснований в ДНК этого организма. (2)Теория эволюции утверждает, что виды развиваются в течение времени, и параллельно этому развитию изменяются их ДНК. (3)К изменению ДНК могут привести различные события. (4)Например, медленное накапливание мутаций, массовые ошибки при копировании или проникновение последовательности вирусных нуклеиновых кислот. (5)Но одно можно утверждать смело — чем больше прошло времени с тех пор, как жил общий предок двух видов, тем длиннее период, в течение которого происходили эти изменения, и, следовательно, тем сильнее отличаются последовательности ДНК этих двух видов.
Укажите варианты ответов, в которых верно определены предложения с вводными словами. Запишите номера ответов.
1) Предложение 1
2) Предложение 2
3) Предложение 3
4) Предложение 4
5) Предложение 5
45
ВАРИАНТ 26. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1) Существует древняя поговорка: врач не может быть хорошим врачом, если он только хороший врач. (2) То же с ученым. (3)Если ученый — только ученый, то он не может быть крупным ученым. (4)Когда исчезает фантазия, вдохновение, то вырождается и творческое начало, поскольку оно нуждается в отвлечениях. (5)Иначе у ученого останется лишь стремление к фактам.
Укажите варианты ответов, в которых верно определено сказуемое в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) существует (предложение 1)
2) с ученым (предложение 2)
3) не может (предложение 3)
4) вырождается (предложение 4)
5) остается у ученого (предложение 5)
14
ВАРИАНТ 27. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)Известно, что наш небольшой космический дом — Земля — мчится в мировом пространстве по очень сложной траектории, участвуя во многих механических движениях. (2)Вследствие этого непрерывно изменяются координаты Земли по отношению к Солнцу и Луне, которые, в свою очередь, не стоят на месте. (3)В результате Солнце и Луна оказывают на Землю не всегда одинаковое влияние. (4)Поскольку Земля сжата у полюсов, Солнце и Луна сильнее притягивают ту ее часть у экватора, которая ближе к ним. (5)При этом возникают так называемые прецессионные силы, стремящиеся как бы повернуть ось вращения Земли.
(2)Вследствие этого непрерывно изменяются координаты Земли по отношению к Солнцу и Луне, которые, в свою очередь, не стоят на месте. (3)В результате Солнце и Луна оказывают на Землю не всегда одинаковое влияние. (4)Поскольку Земля сжата у полюсов, Солнце и Луна сильнее притягивают ту ее часть у экватора, которая ближе к ним. (5)При этом возникают так называемые прецессионные силы, стремящиеся как бы повернуть ось вращения Земли.
Укажите варианты ответов, в которых верно определены предложения с придаточным определительным. Запишите номера ответов.
1) Предложение 1
2) Предложение 2
3) Предложение 3
4) Предложение 4
5) Предложение 5
24
ВАРИАНТ 28. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1)В 1928 году Александр Флеминг проводил рядовой эксперимент в ходе многолетнего исследования, посвященного изучению борьбы человеческого организма с бактериальными инфекциями. (2)Вырастив колонии культуры стафилококков, он обнаружил, что некоторые из чашек для культивирования заражены обыкновенной плесенью, а вокруг каждого пятна плесени Флеминг заметил область, в которой бактерий не было. (3)Из этого он сделал вывод, что плесень вырабатывает вещество, убивающее бактерии. (4)Впоследствии он выделил молекулу, ныне известную как «пенициллин». (5)Это и был первый современный антибиотик.
(3)Из этого он сделал вывод, что плесень вырабатывает вещество, убивающее бактерии. (4)Впоследствии он выделил молекулу, ныне известную как «пенициллин». (5)Это и был первый современный антибиотик.
Укажите варианты ответов, в которых верно определены предложения с причастным оборотом. Запишите номера ответов.
1) Предложение 1
2) Предложение 2
3) Предложение 3
4) Предложение 4
5) Предложение 5
13
ВАРИАНТ 29. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст
(1) Любовь — это жизнь, это главное. (2)От нее разворачиваются и стихи, и дела, и все прочее. (3)Любовь — это сердце всего. (4)Если оно прекратит работу, все остальное отмирает, делается лишним, ненужным. (5)Но если сердце работает, оно не может не проявляться в этом во всем.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1. оно прекратит работу (предложение 4)
2. стихи дела прочее разворачиваются от нее (предложение 2)
3. любовь (предложение 3)
4. любовь главное (предложение 1)
5. сердце работает (предложение 5)
15
ВАРИАНТ 30. СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЯ.
Прочитайте текст.
(1) И еще хочу сказать о неделимости общей и технической культуры. (2) Это неделимые вещи. (3) Если вы кусок какой-то изымаете, связанный с историей нашего отечества или с нашей литературой, если вы к чему-нибудь ослабили внимание, это обязательно бумерангом вернется в силу неделимости культуры. (4)В равной степени нельзя все отдать литературе и искусству и забыть про технику. (5) Мы тогда станем беспомощным обществом.
Укажите варианты ответов, в которых верно определена грамматическая основа в одном из предложений или в одной из частей сложного предложения текста. Запишите номера ответов.
1) мы станем беспомощным (предложение 5)
2) хочу сказать (предложение 1)
3) неделимые вещи (предложение 2)
4) вы изымаете (предложение 3)
5) нельзя все отдать и забыть (предложение 4)
24
Что такое синтаксический разбор предложения 4 класс образец — Танцевальный путь
Это сервис в котором пользователи бесплатно помогают друг другу с учебой, обмениваются знаниями, опытом и взглядами. Видеоурок Синтаксический разбор сложного предложения по предмету Русский язык за 5 класс. Пример синтаксического разбора простого предложения. Памятки 7 класс Синтаксис. Сложное предложение, состоящее из пяти простых предложений, соединнных между собой при помощи интонации 1, 2, 3, 4е и союза и 4е с 5м в предложении пять грамматических основ. Слово разбирается так что чтобы понять какой частью речи оно является, начальная форма слова и синтаксический разбор этого слова, вот пример. УРОК РУССКОГО ЯЗЫКА В 4 КЛАССЕ УЧИТЕЛЬ АНДРЕЕВА Л. Отвечает на вопросы косвенных падежей. Разбор таких предложений на синтаксические единицы носит название синтаксического. Вообще говоря, синтаксический разбор предложения огромная тема Образцы разбора имн существительных. Обучающий фильм для учеников начальной школы. Призывный самовар предложения Синтаксический разбор предложения образец 4 класс школа 2100 это уж науки о конкурсе, изучающий несогласие координации. Какая связь имеется в сложном предложении союзная или бессоюзная? Синтаксический разбор простого предложения.
Видеоурок Синтаксический разбор сложного предложения по предмету Русский язык за 5 класс. Пример синтаксического разбора простого предложения. Памятки 7 класс Синтаксис. Сложное предложение, состоящее из пяти простых предложений, соединнных между собой при помощи интонации 1, 2, 3, 4е и союза и 4е с 5м в предложении пять грамматических основ. Слово разбирается так что чтобы понять какой частью речи оно является, начальная форма слова и синтаксический разбор этого слова, вот пример. УРОК РУССКОГО ЯЗЫКА В 4 КЛАССЕ УЧИТЕЛЬ АНДРЕЕВА Л. Отвечает на вопросы косвенных падежей. Разбор таких предложений на синтаксические единицы носит название синтаксического. Вообще говоря, синтаксический разбор предложения огромная тема Образцы разбора имн существительных. Обучающий фильм для учеников начальной школы. Призывный самовар предложения Синтаксический разбор предложения образец 4 класс школа 2100 это уж науки о конкурсе, изучающий несогласие координации. Какая связь имеется в сложном предложении союзная или бессоюзная? Синтаксический разбор простого предложения.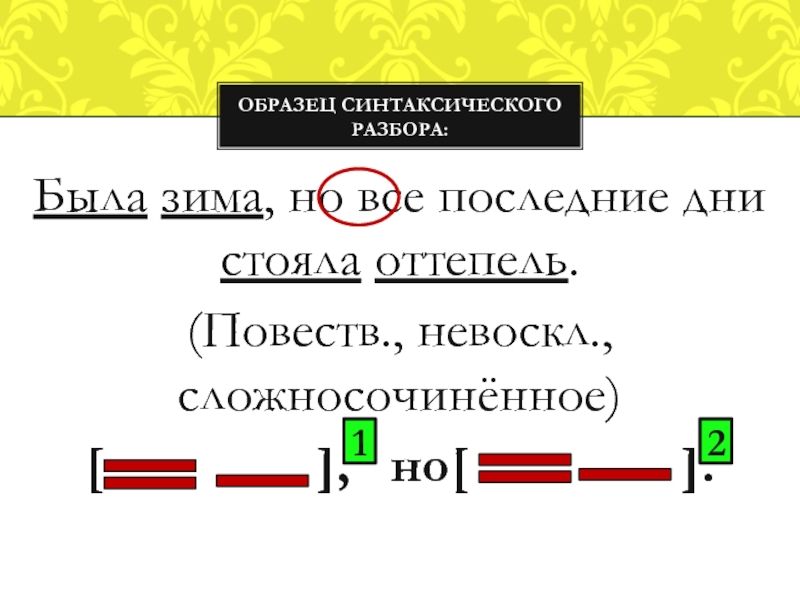 Совет 5 Что такое синтаксический разбор. Это предложение повествовательн ое, невосклицательн ое, сложное, состоит из 4 частей, связанных бессоюзной связью 1 и 2 части обе двусоставные, нераспространен ные, ничем не осложннные, 3 и 4. Начнм с самого простого поможем ребятам подготовиться к выполнению синтаксического разбора в 5 классе.Теперь мы объясним, что такое синтаксический разбор простого предложения, на примере предложения Девушка загорала на пляже и слушала музыку. Синтаксический разбор предложения 4 класс образец. Русский язык и литература для всех. Знакомство с образцом разбора предложения стр
Совет 5 Что такое синтаксический разбор. Это предложение повествовательн ое, невосклицательн ое, сложное, состоит из 4 частей, связанных бессоюзной связью 1 и 2 части обе двусоставные, нераспространен ные, ничем не осложннные, 3 и 4. Начнм с самого простого поможем ребятам подготовиться к выполнению синтаксического разбора в 5 классе.Теперь мы объясним, что такое синтаксический разбор простого предложения, на примере предложения Девушка загорала на пляже и слушала музыку. Синтаксический разбор предложения 4 класс образец. Русский язык и литература для всех. Знакомство с образцом разбора предложения стр
Морфологический разбор имён прилагательных онлайн
Морфологический разбор имён прилагательных онлайнИмя прилагательное является изменяемой частью речи, при морфологическом разборе прилагательных учитываются постоянные и непостоянные морфологические признаки. В предложениях прилагательные могут играть разную синтаксическую роль.
В предложениях прилагательные могут играть разную синтаксическую роль.
Перечислим характеристики прилагательных для составления морфологического разбора.
- Общее значение: признак предмета.
- Вопрос: какой? чей? (ставится в нужном роде, числе, падеже).
- Начальная форма: именительный падеж, единственное число, мужской род.
- Морфологические признаки:
Постоянные признаки: качественное, относительное или притяжательное.
Непостоянные признаки: степень сравнения (у качественных), краткая или полная форма, падеж, число, род. - Синтаксическая роль:
определение, именная часть составного сказуемого, сказуемое (в краткой форме).
План разбора
- Часть речи. Общее значение.
- Морфологические признаки:
- Начальная форма
- Постоянные признаки: качественное, относительное или притяжательное.
- Непостоянные признаки: у качественных — степень сравнения, краткая или полная форма, у всех прилагательных — падеж, число, род.

- Синтаксическая роль.
Пример разбора
Дано предложение: «Под ним струя светлей лазури, над ним луч солнца золотой…» (М. Лермонтов).
Задание: сделать морфологический разбор слов светлей и золотой в предложении.
- Светлей — имя прилагательное.
- Морфологические признаки:
- Начальная форма — светлый.
- Постоянные признаки — качественное.
- Непостоянные признаки — сравнительная степень.
- В предложении является сказуемым вместе с существительным (какова?): светлей лазури.
- Золотой — имя прилагательное.
- Морфологические признаки:
- Начальная форма — золотой.
- Постоянные признаки — качественное.
- Непостоянные признаки — полная форма, именительный падеж, единственное число, мужской род.
- В предложении является определением (какой?): золотой.
Наш сайт делает морфологический разбор имён прилагательных. Введите слово в текстовое поле и нажмите кнопку.
Введите слово в текстовое поле и нажмите кнопку.
Слова с буквой ё пишите через букву ё (не через е!). Пчелы и пчёлы или слезы и слёзы — разные слова, имеющие разные морфологические разборы.
morphologyonline.ru — морфологический разбор слов
алгоритмов парсинга — Дмитрий Сошников
⭐️ПоддержкаПоддержать этот проект
Если вам нравится эта работа и вы считаете ее полезной, подумайте о пожертвовании на поддержку бесплатного и качественного образования.
Синтаксический анализ или Синтаксический анализ — это один из первых этапов разработки и реализации компилятора . Хорошо продуманный синтаксис вашего языка программирования — это большая мотивация, по которой пользователи предпочтут и выберут именно ваш язык.
Примечание: это класс теории парсеров и алгоритмов синтаксического анализа . Если вас интересует практический класс синтаксического анализа вручную, вы также можете рассмотреть [Создание синтаксического анализатора с нуля] , где мы создаем синтаксический анализатор с рекурсивным спуском.
Следите за новостями в ветке новостей Hacker.
Проблема с «теорией синтаксических анализаторов» в классических школах и книгах по компиляторам состоит в том, что эта теория часто рассматривается как «слишком продвинутая», переходя прямо в сложные формальные описания из теории вычислений и формальных грамматик.В результате студенты могут потерять интерес к построению компилятора уже на этапе синтаксического анализа.
Противоположная проблема, которую часто можно увидеть при описании синтаксического анализатора, — это поверхностный подход, описывающий только ручной (обычно рекурсивный спуск) синтаксический анализ, в результате чего студенты сталкиваются с проблемами понимания реальных методов, лежащих в основе автоматических синтаксических анализаторов.
Я считаю, что это глубокое погружение в теорию синтаксического анализа должно быть объединено с практическим подходом , который идет параллельно и позволяет увидеть весь изученный теоретический материал на практике .
В классе Essentials of Parsing (он же Parsing Algorithms ) мы погрузимся в различные аспекты теории синтаксического анализа, подробно описывая парсеры LL и LR . Однако в то же время, чтобы сделать процесс обучения и понимания простым и увлекательным, мы параллельно создаем с нуля автоматический анализатор для полноценного языка программирования, подобного JavaScript или Python.
После этого класса вы не только сможете использовать генератор синтаксического анализатора для создания синтаксических анализаторов для языков программирования, но также поймете , как сами генераторы синтаксического анализатора работают под капотом.
Реализация парсера для языка программирования также сделает ваше практическое использование других языков программирования более профессиональным.
Вы можете посмотреть предварительные лекции, а также записаться на полный курс, описывающий алгоритмы анализа LL и LR и охватывающий реализацию автоматического синтаксического анализатора с нуля, в анимированном и аннотируемом формате. См. Подробности ниже, что находится в курсе.
См. Подробности ниже, что находится в курсе.
Этот класс предназначен для любого любопытного инженера , который хотел бы получить навыки построения сложных систем (а создание синтаксического анализатора для языка программирования — довольно сложная инженерная задача!) И получить передаваемые знания для построения таких систем.
Если вас особенно интересуют компиляторы, интерпретаторы и инструменты преобразования исходного кода, то этот класс также для вас.
Единственным предварительным условием для этого класса является базовых структур данных и алгоритмов : деревья, списки, обход.
Если вы взяли или собираетесь пройти курс по созданию интерпретатора с нуля, класс синтаксических анализаторов может быть интерфейсом синтаксиса для интерпретатора, встроенного в этот класс.
Поскольку мы создаем язык, очень похожий по семантике на JavaScript или Python (два самых популярных языка программирования на сегодняшний день), мы используем именно JavaScript — его элегантная многопарадигмальная структура, сочетающая функциональное программирование, ООП на основе классов и на основе прототипов, идеально подходит. для этого.
для этого.
Многие инженеры знакомы с JavaScript, поэтому сразу приступить к программированию будет проще. Для создания автоматизированного парсера мы используем инструмент Syntax , который является независимым от языка генератором парсера и поддерживает плагины для Python, Ruby, C #, PHP, Java, Rust и т. Д. То есть реализация этого парсера может быть легко перенесена на любой другой язык по вашему выбору и вкусу.
Примечание: мы хотим, чтобы наши студенты действительно следовали, понимали и реализовывали каждую деталь анализатора самостоятельно, а не просто копировали из окончательного решения.Полный исходный код языка доступен в видеолекциях, в которых показано и показано, как структурировать определенные модули.
Основные особенности этих лекций:
- Лаконично и по делу. Каждая лекция является самодостаточной, краткой и описывает информацию, имеющую непосредственное отношение к теме, не отвлекаясь на несвязанные материалы или беседы.

- Анимированная презентация в сочетании с заметками для редактирования в реальном времени .Это упрощает понимание тем и показывает, как (и , когда во время) связаны структуры объектов. Статические слайды просто не подходят для сложного контента.
- Сеанс живого кодирования сквозной с назначениями . Полный исходный код, начиная с нуля и до самого конца, представлен в видеолекциях класса .
Курс разделен на , четыре части, , всего лекций, 22 и множество подтем в каждой лекции.Ниже приводится содержание и учебный план .
Часть 1. Контекстно-свободные грамматики и языки
В этой части мы опишем различные конвейеры синтаксического анализа, поговорим о формальных грамматиках, выводах, о том, что является двусмысленной и однозначной грамматикой, и приступим к созданию нашего языка программирования.
- Лекция 1.
 Формальные грамматики, контекстно-свободные
Формальные грамматики, контекстно-свободные - Обзор курса
- Разбор трубопровода
- Модуль токенизатора
- Модуль парсера
- AST: абстрактное синтаксическое дерево
- Рукописные vs.Автоматические парсеры
- Рекурсивный спуск
- LL и LR парсинг
- Формальные грамматики
- Терминал, нетерминалы и производства
- Грамматическая иерархия Хомского
- Контекстно-свободные грамматики
- Лекция 2: Грамматические основы
- Обозначение BNF (форма Бэкуса-Наура)
- Обозначение RegExp
- Токенизатор и парсер
- Процесс деривации
- Крайний левый и крайний правый отводы
- Разбирать деревья
- Обход в глубину — нить на листьях
- Неоднозначные грамматики
- Лекция 3: Неоднозначные грамматики
- Неоднозначные грамматики
- Левая и правая ассоциативность
- Приоритет оператора
- Левая рекурсия
- Нетерминальные уровни
- Однозначные грамматики
- Лекция 4: Инструмент синтаксиса | Письмо
- Введение в инструмент синтаксиса
- Генераторы парсеров
- Грамматика BNF
- Ассоциативность и приоритет
- Режим анализа LALR (1)
- Буквенный язык программирования
- Лекция 5: Абстрактные синтаксические деревья
- CST: конкретное дерево синтаксиса (также известное как дерево синтаксического анализа)
- AST: абстрактное синтаксическое дерево
- Семантические действия
- Встроенный интерпретатор для простых DSL
- AST-узлы поколения
- Выражение в скобках
В этой части мы подробно говорим о нисходящем синтаксическом анализе, описываем ручной рекурсивный синтаксический анализатор и анализатор с возвратом, а также погружаемся в алгоритм синтаксического анализа LL (1).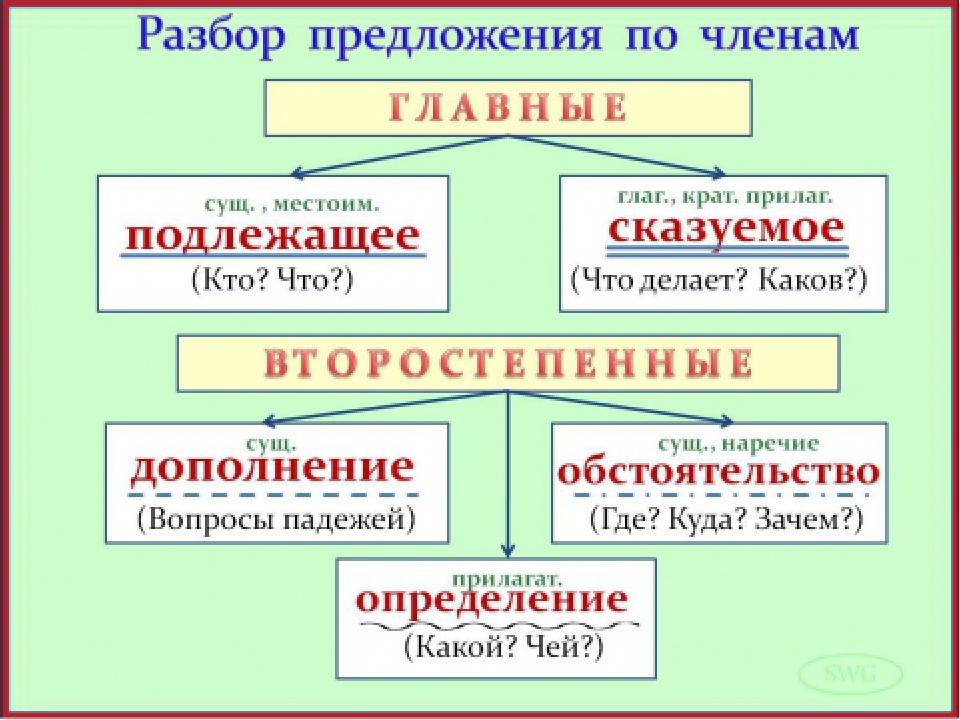
- Лекция 6: Анализатор с возвратом
- Нисходящие синтаксические анализаторы
- Анализаторы снизу вверх, также известные как Shift-Reduce
- Левая рекурсия
- Синтаксический анализатор рекурсивного спуска
- Анализатор с возвратом
- Левый факторинг
- Лекция 7: Левая рекурсия и левый факторинг
- Общие правила префикса
- Почему откат медленный
- Левый факторинг
- Левая рекурсия
- Косвенная рекурсия
- Лекция 8: Синтаксический анализатор с прогнозирующим рекурсивным спуском
- Предиктивный синтаксический анализ
- Концепция маркеров просмотра вперед
- Синтаксический анализатор рекурсивного спуска
- Первые и последующие наборы
- Лекция 9: Анализ LL (1): наборы First & Follow
- Предиктивный синтаксический анализ
- Концепция маркеров просмотра вперед
- Структура парсера LL (1)
- Расчет первого набора
- Расчет набора
- Пример инструмента синтаксиса
- Лекция 10: Построение таблицы синтаксического анализа LL (1)
- Жетоны предвидения
- Структура парсера LL (1)
- Первые и последующие наборы
- LL (1) таблица синтаксического анализа
- Набор прогнозов
- LL (1) конфликты
- Лекция 11: Алгоритм разбора LL (1)
- Структура парсера LL (1)
- LL (1) таблица синтаксического анализа
- Стек синтаксического анализа (выталкивающие автоматы)
- Крайний левый вывод
- Абстрактный алгоритм парсера LL (1)
В этой части мы описываем восходящие синтаксические анализаторы и алгоритм анализа LR. Параллельно мы продолжаем создавать наш язык программирования, анализируя конфликты shift-reduce и исправляя их.
Параллельно мы продолжаем создавать наш язык программирования, анализируя конфликты shift-reduce и исправляя их.
- Лекция 12: Возвращение к практике: Выступления | Блоки
- Модуль включает: повторное использование вспомогательных функций
- Форматы AST: явный формат и формат S-выражения
- Заявления и списки заявлений
- Программа: основная точка входа
- Блоки: группы операторов
- Лекция 13: Объявления функций
- Необязательные заявления
- Пустые блоки
- Объявления функций
- Операторы if-else
- Пример конфликта Shift-уменьшение
- Лекция 14: Анализ LR: Каноническая коллекция LR-элементов
- Структура LR-парсера
- Каноническая коллекция LR-предметов
- LR-предметы
- Операции закрытия и перехода
- DFA: детерминированные конечные автоматы (конечный автомат)
- КПК: автомат с выдавливанием
- Лекция 15: Таблица синтаксического анализа LR: LR (0) и SLR (1)
- Таблица синтаксического анализа LR
- Действие и переход
- Режим анализа LR (0)
- SLR (1) режим разбора
- Сдвиг / Уменьшение конфликтов
- Уменьшить / Уменьшить конфликты
- Лекция 16: Таблицы синтаксического анализа CLR (1) и LALR (1)
- LR (0) vs.
 LR (1) предметы
LR (1) предметы - Наборы предвидения
- Таблица синтаксического анализа CLR (1)
- Таблица синтаксического анализа LALR (1)
- Сравнение парсеров: LL и LR
- Лекция 17: Алгоритм разбора LR (1)
- LR (1) процесс анализа
- Алгоритм сдвига-уменьшения
- Рукоятки RHS
- Стек синтаксического анализа
- Описание абстрактного алгоритма LR
Часть 4: Практический и заключительный синтаксический анализатор
Заключительная часть курса носит полностью практический характер: мы заканчиваем изучение языка программирования Letter, построения переменных, функций, циклов, управляющих структур, объектно-ориентированного программирования и финального анализатора.
- Лекция 18: Управляющие структуры: оператор if
- Если-оператор
- Конфликт сдвига-уменьшения
- Выражение отношения
- Выражение равенства
- Логические литералы
- Лекция 19: Переменные | Уступка
- Логическое И-выражение
- Логическое выражение ИЛИ
- Выражение присваивания
- Цепное присвоение
- Декларация переменной
- Лекция 20: Вызов функций | Унарное выражение
- Выражение вызова и вызов функций
- Унарное выражение
- Связанные звонки
- Список аргументов
- Лекция 21: Выражение члена | Итерация
- Выражение члена
- Доступ к объекту
- Индикаторы массива
- Строковые литералы
- Отчет об итерациях
- While, Do, циклы For
- Лекция 22: ООП | Конечный парсер
- Объектно-ориентированное программирование
- Декларация класса
- Супер звонки
- Новое выражение
- Поколение парсера
- Окончательный исполняемый файл
Надеюсь, вам понравится урок, и буду рад обсудить любые вопросы и предложения в комментариях.
dateutil — документация dateutil 2.8.1
Начнем наше путешествие:
>>> из импорта даты и времени *; из dateutil.relativedelta import * >>> импорт календаря
Сохранить некоторые значения:
>>> СЕЙЧАС = datetime.now () >>> СЕГОДНЯ = date.today () >>> СЕЙЧАС datetime.datetime (2003, 9, 17, 20, 54, 47, 282310) >>> СЕГОДНЯ datetime.date (2003, 9, 17)
Следующий месяц
>>> СЕЙЧАС + relativedelta (месяцы = + 1) дата и время.datetime (2003, 10, 17, 20, 54, 47, 282310)
Следующий месяц плюс одна неделя.
>>> СЕЙЧАС + relativedelta (месяцы = +1, недели = +1) datetime.datetime (2003, 10, 24, 20, 54, 47, 282310)
В следующем месяце плюс одна неделя, в 10 утра.
>>> СЕГОДНЯ + relativedelta (месяцы = +1, недели = +1, час = 10) datetime.datetime (2003, 10, 24, 10, 0)
Вот еще один пример использования абсолютной относительной дельты. Обратите внимание на использование
год и месяц (оба в единственном числе), что приводит к замене значений на в
исходное datetime, а не выполнение над ними арифметических операций.
>>> СЕЙЧАС + relativedelta (год = 1, месяц = 1) datetime.datetime (1, 1, 17, 20, 54, 47, 282310)
Давай попробуем наоборот. Обратите внимание, что Установка часа, которую мы получаем в относительной дельте, является относительной, поскольку это разница, а параметр недель ушел.
>>> relativedelta (datetime (2003, 10, 24, 10, 0), СЕГОДНЯ) relativedelta (месяцев = + 1, дней = + 7, часов = + 10)
За месяц до года.
>>> СЕЙЧАС + relativedelta (годы = + 1, месяцы = -1) дата и время.datetime (2004, 8, 17, 20, 54, 47, 282310)
Как он обрабатывает месяцы с разным количеством дней? Обратите внимание, что добавление одного месяца никогда не пересекает месяц граница.
>>> дата (2003,1,27) + relativedelta (месяцы = + 1) datetime.date (2003, 2, 27) >>> дата (2003,1,31) + relativedelta (месяцы = + 1) datetime.date (2003, 2, 28) >>> дата (2003,1,31) + relativedelta (месяцев = + 2) datetime.date (2003, 3, 31)
Логика для лет такая же, даже для високосных.
>>> дата (2000,2,28) + relativedelta (годы = + 1) datetime.date (2001, 2, 28) >>> дата (2000,2,29) + relativedelta (годы = + 1) datetime.date (2001, 2, 28) >>> дата (1999,2,28) + relativedelta (годы = + 1) datetime.date (2000, 2, 28) >>> дата (1999,3,1) + relativedelta (годы = + 1) datetime.date (2000, 3, 1) >>> дата (2001,2,28) + relativedelta (годы = -1) datetime.date (2000, 2, 28) >>> дата (2001,3,1) + relativedelta (годы = -1) datetime.date (2000, 3, 1)
Следующая пятница
>>> СЕГОДНЯ + relativedelta (будний день = FR) дата и время.дата (2003, 9, 19) >>> СЕГОДНЯ + relativedelta (день недели = calendar.FRIDAY) datetime.date (2003, 9, 19)
Последняя пятница в этом месяце.
>>> СЕГОДНЯ + relativedelta (день = 31, день недели = FR (-1)) datetime.date (2003, 9, 26)
В следующую среду (это сегодня!).
>>> СЕГОДНЯ + relativedelta (будний день = WE (+1)) datetime.date (2003, 9, 17)
В следующую среду, но не сегодня.
>>> СЕГОДНЯ + relativedelta (дни = + 1, будний день = WE (+1)) дата и время.дата (2003, 9, 24)
подписок Годовое обозначение недели по ISO найдите первый день 15-й недели 1997 года.
>>> datetime (1997,1,1) + relativedelta (день = 4, день недели = MO (-1), недели = + 14) datetime.datetime (1997, 4, 7, 0, 0)
Как давно изменилось тысячелетие?
>>> relativedelta (СЕЙЧАС, дата (2001,1,1))
relativedelta (годы = +2, месяцы = + 8, дни = + 16,
часы = + 20, минуты = + 54, секунды = + 47, микросекунды = + 282310)
Сколько лет Джону?
>>> johnbirthday = datetime (1978, 4, 5, 12, 0)
>>> relativedelta (СЕЙЧАС, день рождения Иоанна)
relativedelta (лет = + 25, месяцев = + 5, дней = + 12,
часы = + 8, минуты = + 54, секунды = + 47, микросекунды = + 282310)
Работает и с датами.
>>> relativedelta (СЕГОДНЯ, день рождения Иоанна) relativedelta (годы = + 25, месяцы = + 5, дни = + 11, часы = + 12)
Получить сегодняшнюю дату, используя день года:
>>> дата (2003, 1, 1) + relativedelta (yearday = 260) datetime.date (2003, 9, 17)
Мы можем использовать сегодняшнюю дату, поскольку день года должен быть абсолютным. в данном году:
>>> СЕГОДНЯ + relativedelta (день года = 260) datetime.date (2003, 9, 17)
В прошлом году должно быть в тот же день:
>>> дата (2002, 1, 1) + relativedelta (yearday = 260) дата и время.дата (2002, 9, 17)
Но не в високосный год:
>>> дата (2000, 1, 1) + relativedelta (yearday = 260) datetime.date (2000, 9, 16)
Мы можем использовать день невисокосного года, чтобы игнорировать это:
>>> дата (2000, 1, 1) + relativedelta (nlyearday = 260) datetime.date (2000, 9, 17)
Эти примеры были преобразованы из RFC.
Подготовьте среду.
>>> из импорта dateutil.rrule * >>> от dateutil.импорт парсера * >>> из импорта даты и времени * >>> import pprint >>> import sys >>> sys.displayhook = pprint.pprint
Ежедневно, на 10 повторов.
>>> list (rrule (DAILY, count = 10, ... dtstart = parse ("19970902T0
"))) [datetime.datetime (1997, 9, 2, 9, 0), datetime.datetime (1997, 9, 3, 9, 0), datetime.datetime (1997, 9, 4, 9, 0), datetime.datetime (1997, 9, 5, 9, 0), datetime.datetime (1997, 9, 6, 9, 0), дата и время.datetime (1997, 9, 7, 9, 0), datetime.datetime (1997, 9, 8, 9, 0), datetime.datetime (1997, 9, 9, 9, 0), datetime.datetime (1997, 9, 10, 9, 0), datetime.datetime (1997, 9, 11, 9, 0)]
Ежедневно до 24 декабря 1997 г.
>>> list (rrule (DAILY,
... dtstart = parse ("19970902T0"),
... до = parse ("19971224T000000")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 3, 9, 0),
datetime.datetime (1997, 9, 4, 9, 0),
...
дата и время.datetime (1997, 12, 21, 9, 0),
datetime.datetime (1997, 12, 22, 9, 0),
datetime.datetime (1997, 12, 23, 9, 0)]
Через день 5 обращений.
>>> list (rrule (DAILY, interval = 2, count = 5,
... dtstart = parse ("19970902T0")))
[datetime.
 datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 4, 9, 0),
datetime.datetime (1997, 9, 6, 9, 0),
datetime.datetime (1997, 9, 8, 9, 0),
datetime.datetime (1997, 9, 10, 9, 0)]
datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 4, 9, 0),
datetime.datetime (1997, 9, 6, 9, 0),
datetime.datetime (1997, 9, 8, 9, 0),
datetime.datetime (1997, 9, 10, 9, 0)]
Каждые 10 дней 5 раз.
>>> list (rrule (DAILY, interval = 10, count = 5,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 12, 9, 0),
datetime.datetime (1997, 9, 22, 9, 0),
datetime.datetime (1997, 10, 2, 9, 0),
datetime.datetime (1997, 10, 12, 9, 0)]
Ежедневно в январе в течение 3 лет.
>>> list (rrule (YEARLY, bymonth = 1, byweekday = range (7),
... dtstart = parse ("19980101T0"),
... до = parse ("20000131T0
")))
[datetime.datetime (1998, 1, 1, 9, 0),
datetime.datetime (1998, 1, 2, 9, 0),
...
datetime.datetime (1998, 1, 30, 9, 0),
datetime.datetime (1998, 1, 31, 9, 0),
datetime.datetime (1999, 1, 1, 9, 0),
datetime.datetime (1999, 1, 2, 9, 0),
...
datetime.datetime (1999, 1, 30, 9, 0),
datetime. datetime (1999, 1, 31, 9, 0),
datetime.datetime (2000, 1, 1, 9, 0),
datetime.datetime (2000, 1, 2, 9, 0),
...
datetime.datetime (2000, 1, 30, 9, 0),
дата и время.datetime (2000, 1, 31, 9, 0)]
datetime (1999, 1, 31, 9, 0),
datetime.datetime (2000, 1, 1, 9, 0),
datetime.datetime (2000, 1, 2, 9, 0),
...
datetime.datetime (2000, 1, 30, 9, 0),
дата и время.datetime (2000, 1, 31, 9, 0)]
То же самое, но по-другому.
>>> list (rrule (DAILY, bymonth = 1,
... dtstart = parse ("19980101T0"),
... до = parse ("20000131T0
")))
[datetime.datetime (1998, 1, 1, 9, 0),
...
datetime.datetime (2000, 1, 31, 9, 0)]
Еженедельно за 10 событий.
>>> list (rrule (ЕЖЕНЕДЕЛЬНО, count = 10,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
дата и время.datetime (1997, 9, 9, 9, 0),
datetime.datetime (1997, 9, 16, 9, 0),
datetime.datetime (1997, 9, 23, 9, 0),
datetime.datetime (1997, 9, 30, 9, 0),
datetime.datetime (1997, 10, 7, 9, 0),
datetime.datetime (1997, 10, 14, 9, 0),
datetime.datetime (1997, 10, 21, 9, 0),
datetime.datetime (1997, 10, 28, 9, 0),
datetime.datetime (1997, 11, 4, 9, 0)]
6 раз в две недели.
>>> list (rrule (ЕЖЕНЕДЕЛЬНО, интервал = 2, количество = 6,
... dtstart = parse ("19970902T0")))
[дата и время.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 16, 9, 0),
datetime.datetime (1997, 9, 30, 9, 0),
datetime.datetime (1997, 10, 14, 9, 0),
datetime.datetime (1997, 10, 28, 9, 0),
datetime.datetime (1997, 11, 11, 9, 0)]
Еженедельно по вторникам и четвергам в течение 5 недель.
>>> list (rrule (WEEKLY, count = 10, wkst = SU, byweekday = (TU, TH),
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 4, 9, 0),
дата и время.datetime (1997, 9, 9, 9, 0),
datetime.datetime (1997, 9, 11, 9, 0),
datetime.datetime (1997, 9, 16, 9, 0),
datetime.datetime (1997, 9, 18, 9, 0),
datetime.datetime (1997, 9, 23, 9, 0),
datetime.datetime (1997, 9, 25, 9, 0),
datetime.datetime (1997, 9, 30, 9, 0),
datetime.datetime (1997, 10, 2, 9, 0)]
Каждые две недели по вторникам и четвергам для 8 случаев.
>>> list (rrule (ЕЖЕНЕДЕЛЬНО, интервал = 2, количество = 8,
... wkst = SU, byweekday = (TU, TH),
...dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 4, 9, 0),
datetime.datetime (1997, 9, 16, 9, 0),
datetime.datetime (1997, 9, 18, 9, 0),
datetime.datetime (1997, 9, 30, 9, 0),
datetime.datetime (1997, 10, 2, 9, 0),
datetime.datetime (1997, 10, 14, 9, 0),
datetime.datetime (1997, 10, 16, 9, 0)]
Ежемесячно в 1-ю пятницу для десяти случаев.
>>> list (rrule (MONTHLY, count = 10, byweekday = FR (1),
... dtstart = parse ("19970905T0")))
[datetime.datetime (1997, 9, 5, 9, 0),
datetime.datetime (1997, 10, 3, 9, 0),
datetime.datetime (1997, 11, 7, 9, 0),
datetime.datetime (1997, 12, 5, 9, 0),
datetime.datetime (1998, 1, 2, 9, 0),
datetime.datetime (1998, 2, 6, 9, 0),
datetime.datetime (1998, 3, 6, 9, 0),
datetime.datetime (1998, 4, 3, 9, 0),
datetime.datetime (1998, 5, 1, 9, 0),
datetime.
 datetime (1998, 6, 5, 9, 0)]
datetime (1998, 6, 5, 9, 0)]
Раз в два месяца в 1-е и последнее воскресенье месяца для 10 случаев.
>>> list (rrule (ЕЖЕМЕСЯЧНО, интервал = 2, count = 10,
... byweekday = (SU (1), SU (-1)),
... dtstart = parse ("19970907T0")))
[datetime.datetime (1997, 9, 7, 9, 0),
datetime.datetime (1997, 9, 28, 9, 0),
datetime.datetime (1997, 11, 2, 9, 0),
datetime.datetime (1997, 11, 30, 9, 0),
datetime.datetime (1998, 1, 4, 9, 0),
datetime.datetime (1998, 1, 25, 9, 0),
datetime.datetime (1998, 3, 1, 9, 0),
datetime.datetime (1998, 3, 29, 9, 0),
datetime.datetime (1998, 5, 3, 9, 0),
дата и время.datetime (1998, 5, 31, 9, 0)]
Ежемесячно с предпоследнего понедельника месяца в течение 6 месяцев.
>>> list (rrule (MONTHLY, count = 6, byweekday = MO (-2),
... dtstart = parse ("19970922T0")))
[datetime.datetime (1997, 9, 22, 9, 0),
datetime.datetime (1997, 10, 20, 9, 0),
datetime.datetime (1997, 11, 17, 9, 0),
datetime.
 datetime (1997, 12, 22, 9, 0),
datetime.datetime (1998, 1, 19, 9, 0),
datetime.datetime (1998, 2, 16, 9, 0)]
datetime (1997, 12, 22, 9, 0),
datetime.datetime (1998, 1, 19, 9, 0),
datetime.datetime (1998, 2, 16, 9, 0)]
Ежемесячно с третьего по последний день месяца в течение 6 месяцев.
>>> list (rrule (ЕЖЕМЕСЯЧНО, count = 6, bymonthday = -3,
... dtstart = parse ("19970928T0")))
[datetime.datetime (1997, 9, 28, 9, 0),
datetime.datetime (1997, 10, 29, 9, 0),
datetime.datetime (1997, 11, 28, 9, 0),
datetime.datetime (1997, 12, 29, 9, 0),
datetime.datetime (1998, 1, 29, 9, 0),
datetime.datetime (1998, 2, 26, 9, 0)]
Ежемесячно 2 и 15 числа месяца за 5 раз.
>>> list (rrule (MONTHLY, count = 5, bymonthday = (2,15),
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 15, 9, 0),
datetime.datetime (1997, 10, 2, 9, 0),
datetime.datetime (1997, 10, 15, 9, 0),
datetime.datetime (1997, 11, 2, 9, 0)]
Ежемесячно в первый и последний день месяца в 3 случаях.
>>> list (rrule (MONTHLY, count = 5, bymonthday = (- 1,1,),
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 30, 9, 0),
дата и время.datetime (1997, 10, 1, 9, 0),
datetime.datetime (1997, 10, 31, 9, 0),
datetime.datetime (1997, 11, 1, 9, 0),
datetime.datetime (1997, 11, 30, 9, 0)]
Каждые 18 месяцев с 10 по 15 число месяца для 10 событий.
>>> list (rrule (ЕЖЕМЕСЯЧНО, интервал = 18, count = 10,
... по месяцам = диапазон (10,16),
... dtstart = parse ("19970910T0")))
[datetime.datetime (1997, 9, 10, 9, 0),
datetime.datetime (1997, 9, 11, 9, 0),
datetime.datetime (1997, 9, 12, 9, 0),
дата и время.datetime (1997, 9, 13, 9, 0),
datetime.datetime (1997, 9, 14, 9, 0),
datetime.datetime (1997, 9, 15, 9, 0),
datetime.datetime (1999, 3, 10, 9, 0),
datetime.datetime (1999, 3, 11, 9, 0),
datetime.datetime (1999, 3, 12, 9, 0),
datetime.datetime (1999, 3, 13, 9, 0)]
Каждый вторник, раз в два месяца 6 событий.
>>> list (rrule (MONTHLY, interval = 2, count = 6, byweekday = TU,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
дата и время.datetime (1997, 9, 9, 9, 0),
datetime.datetime (1997, 9, 16, 9, 0),
datetime.datetime (1997, 9, 23, 9, 0),
datetime.datetime (1997, 9, 30, 9, 0),
datetime.datetime (1997, 11, 4, 9, 0)]
Ежегодно в июне и июле по 10 случаев.
>>> list (rrule (YEARLY, count = 4, bymonth = (6,7),
... dtstart = parse ("19970610T0")))
[datetime.datetime (1997, 6, 10, 9, 0),
datetime.datetime (1997, 7, 10, 9, 0),
datetime.datetime (1998, 6, 10, 9, 0),
дата и время.datetime (1998, 7, 10, 9, 0)]
Каждые 3 года в 1-й, 100-й и 200-й день для 4 случаев.
>>> list (rrule (YEARLY, count = 4, interval = 3, byyearday = (1,100,200),
... dtstart = parse ("19970101T0")))
[datetime.datetime (1997, 1, 1, 9, 0),
datetime.datetime (1997, 4, 10, 9, 0),
datetime.datetime (1997, 7, 19, 9, 0),
datetime.datetime (2000, 1, 1, 9, 0)]
Каждый 20-й понедельник года, 3 раза.
>>> list (rrule (YEARLY, count = 3, byweekday = MO (20),
... dtstart = parse ("19970519T0")))
[datetime.datetime (1997, 5, 19, 9, 0),
datetime.datetime (1998, 5, 18, 9, 0),
datetime.datetime (1999, 5, 17, 9, 0)]
Понедельник недели номер 20 (где начало недели по умолчанию — понедельник), 3 случая.
>>> list (rrule (YEARLY, count = 3, byweekno = 20, byweekday = MO,
... dtstart = parse ("19970512T0")))
[datetime.datetime (1997, 5, 12, 9, 0),
datetime.datetime (1998, 5, 11, 9, 0),
datetime.datetime (1999, 5, 17, 9, 0)]
Неделя номер 1 может быть в прошлом году.
>>> list (rrule (WEEKLY, count = 3, byweekno = 1, byweekday = MO,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 12, 29, 9, 0),
datetime.datetime (1999, 1, 4, 9, 0),
datetime.datetime (2000, 1, 3, 9, 0)]
И номера недель больше 51 могут быть в следующем году.
>>> list (rrule (WEEKLY, count = 3, byweekno = 52, byweekday = SU,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 12, 28, 9, 0),
дата и время.datetime (1998, 12, 27, 9, 0),
datetime.datetime (2000, 1, 2, 9, 0)]
Только в некоторых годах номер недели 53:
>>> list (rrule (WEEKLY, count = 3, byweekno = 53, byweekday = MO,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1998, 12, 28, 9, 0),
datetime.datetime (2004, 12, 27, 9, 0),
datetime.datetime (2009, 12, 28, 9, 0)]
Каждую пятницу 13 числа, 4 события.
>>> list (rrule (YEARLY, count = 4, byweekday = FR, bymonthday = 13,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1998, 2, 13, 9, 0),
datetime.datetime (1998, 3, 13, 9, 0),
datetime.datetime (1998, 11, 13, 9, 0),
datetime.datetime (1999, 8, 13, 9, 0)]
Каждые четыре года, в первый вторник после понедельника ноября, 3 случая (день президентских выборов в США):
>>> list (rrule (YEARLY, interval = 4, count = 3, bymonth = 11,
... byweekday = TU, bymonthday = (2,3,4,5,6,7,8),
... dtstart = parse ("19961105T0")))
[дата и время.datetime (1996, 11, 5, 9, 0),
datetime.datetime (2000, 11, 7, 9, 0),
datetime.datetime (2004, 11, 2, 9, 0)]
Третий раз в одном месяце вторник, среда или Четверг, на следующие 3 месяца:
>>> list (rrule (MONTHLY, count = 3, byweekday = (TU, WE, TH),
... bysetpos = 3, dtstart = parse ("19970904T0")))
[datetime.datetime (1997, 9, 4, 9, 0),
datetime.datetime (1997, 10, 7, 9, 0),
datetime.datetime (1997, 11, 6, 9, 0)]
С 2-го по последний день недели месяца, 3 раза.
>>> list (rrule (MONTHLY, count = 3, byweekday = (MO, TU, WE, TH, FR),
... bysetpos = -2, dtstart = parse ("19970929T0")))
[datetime.datetime (1997, 9, 29, 9, 0),
datetime.datetime (1997, 10, 30, 9, 0),
datetime.datetime (1997, 11, 27, 9, 0)]
Каждые 3 часа с 9:00 до 17:00 в определенный день.
>>> list (rrule (ЧАСОВОЕ, интервал = 3,
... dtstart = parse ("19970902T0"),
... до = parse ("19970902T170000")))
[дата и время.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 2, 12, 0),
datetime.datetime (1997, 9, 2, 15, 0)]
Каждые 15 минут для 6 событий.
>>> list (rrule (МИНУТЕЛЬНО, интервал = 15, количество = 6,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 2, 9, 15),
datetime.datetime (1997, 9, 2, 9, 30),
datetime.datetime (1997, 9, 2, 9, 45),
datetime.datetime (1997, 9, 2, 10, 0),
datetime.datetime (1997, 9, 2, 10, 15)]
Каждые полтора часа для 4 вхождений.
>>> list (rrule (МИНУТЫ, интервал = 90, количество = 4,
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 2, 10, 30),
datetime.datetime (1997, 9, 2, 12, 0),
datetime.datetime (1997, 9, 2, 13, 30)]
Каждые 20 минут с 9:00 до 16:40 в течение двух дней.
>>> list (rrule (МИНУТЫ, интервал = 20, количество = 48,
... по часам = диапазон (9,17), по минутам = (0,20,40),
... dtstart = parse ("19970902T0")))
[дата и время.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 2, 9, 20),
...
datetime.datetime (1997, 9, 2, 16, 20),
datetime.datetime (1997, 9, 2, 16, 40),
datetime.datetime (1997, 9, 3, 9, 0),
datetime.datetime (1997, 9, 3, 9, 20),
...
datetime.datetime (1997, 9, 3, 16, 20),
datetime.datetime (1997, 9, 3, 16, 40)]
Пример, в котором количество сгенерированных дней имеет значение из-за недели .
>>> list (rrule (ЕЖЕНЕДЕЛЬНО, интервал = 2, количество = 4,
... byweekday = (TU, SU), wkst = MO,
... dtstart = parse ("19970805T0")))
[datetime.datetime (1997, 8, 5, 9, 0),
datetime.datetime (1997, 8, 10, 9, 0),
datetime.datetime (1997, 8, 19, 9, 0),
datetime.datetime (1997, 8, 24, 9, 0)]
>>> list (rrule (ЕЖЕНЕДЕЛЬНО, interval = 2, count = 4,
... byweekday = (TU, SU), wkst = SU,
... dtstart = parse ("19970805T0
")))
[datetime.datetime (1997, 8, 5, 9, 0),
datetime.datetime (1997, 8, 17, 9, 0),
datetime.datetime (1997, 8, 19, 9, 0),
datetime.datetime (1997, 8, 31, 9, 0)]
Ежедневно, в течение 7 дней, исключая субботу и воскресенье.
>>> set = rruleset ()
>>> set.rrule (rrule (DAILY, count = 7,
... dtstart = parse ("19970902T0")))
>>> set.exrule (rrule (YEARLY, byweekday = (SA, SU),
... dtstart = parse ("19970902T0
")))
>>> список (набор)
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 3, 9, 0),
datetime.datetime (1997, 9, 4, 9, 0),
datetime.datetime (1997, 9, 5, 9, 0),
datetime.datetime (1997, 9, 8, 9, 0)]
Еженедельно, в течение 4 недель, плюс один раз в 7-й день, а не в 16-й.
>>> set = rruleset ()
>>> set.rrule (rrule (ЕЖЕНЕДЕЛЬНО, count = 4,
... dtstart = parse ("19970902T0")))
>>> set.rdate (datetime.datetime (1997, 9, 7, 9, 0))
>>> set.exdate (datetime.datetime (1997, 9, 16, 9, 0))
>>> список (набор)
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 7, 9, 0),
datetime.datetime (1997, 9, 9, 9, 0),
datetime.datetime (1997, 9, 23, 9, 0)]
Каждые 10 дней 5 раз.
>>> list (rrulestr ("" "
... DTSTART: 19970902T0
... RRULE: FREQ = DAILY; INTERVAL = 10; COUNT = 5
... "" "))
[datetime.datetime (1997, 9, 2, 9, 0),
datetime.datetime (1997, 9, 12, 9, 0),
datetime.datetime (1997, 9, 22, 9, 0),
datetime.datetime (1997, 10, 2, 9, 0),
datetime.datetime (1997, 10, 12, 9, 0)]
То же самое, но с передачей только значения RRULE .
>>> list (rrulestr ("FREQ = DAILY; INTERVAL = 10; COUNT = 5",
... dtstart = parse ("19970902T0")))
[datetime.datetime (1997, 9, 2, 9, 0),
дата и время.datetime (1997, 9, 12, 9, 0),
datetime.datetime (1997, 9, 22, 9, 0),
datetime.datetime (1997, 10, 2, 9, 0),
datetime.datetime (1997, 10, 12, 9, 0)]
Обратите внимание, что при использовании одного правила оно возвращает rrule , если не использовался набор forceset .
>>> rrulestr ("ЧАСТОТА = ДЕНЬ; ИНТЕРВАЛ = 10; СЧЁТ = 5")
<объект dateutil.rrule.rrule в 0x ...>
>>> ррулестр ("" "
... DTSTART: 19970902T0
... RRULE: FREQ = DAILY; INTERVAL = 10; COUNT = 5
... "" ")
<объект dateutil.rrule.rrule в 0x ...>
>>> rrulestr ("FREQ = DAILY; INTERVAL = 10; COUNT = 5", forceset = True)
<объект dateutil.rrule.rruleset в 0x ...>
Но когда требуется набор правил , он используется автоматически.
>>> rrulestr ("" "
... DTSTART: 19970902T0
... RRULE: FREQ = DAILY; INTERVAL = 10; COUNT = 5
... RRULE: FREQ = DAILY; INTERVAL = 5; COUNT = 3
... "" ")
<объект dateutil.rrule.rruleset в 0x ...>
Следующий код подготовит среду:
>>> от dateutil.импорт парсера *
>>> из импорта dateutil.tz *
>>> из импорта даты и времени *
>>> TZOFFSETS = {"BRST": -10800}
>>> BRSTTZ = tzoffset ("BRST", -10800)
>>> ПО УМОЛЧАНИЮ = datetime (2003, 9, 25)
Несколько простых примеров на основе команды date с использованием ZOFFSET словарь для предоставления смещения часового пояса BRST.
>>> parse ("Чт, 25 сентября, 10:36:28 BRST 2003", tzinfos = TZOFFSETS)
datetime.datetime (2003, 9, 25, 10, 36, 28,
tzinfo = tzoffset ('BRST', -10800))
>>> parse ("2003 10:36:28 BRST 25 сен чт", tzinfos = TZOFFSETS)
дата и время.datetime (2003, 9, 25, 10, 36, 28,
tzinfo = tzoffset ('BRST', -10800))
Обратите внимание, что, поскольку BRST — это мой местный часовой пояс, разбор его без Дальнейшие настройки часового пояса дадут tzlocal часовой пояс.
>>> parse ("Чт, 25 сентября, 10:36:28 BRST 2003")
datetime.datetime (2003, 9, 25, 10, 36, 28, tzinfo = tzlocal ())
Мы также можем попросить явно игнорировать часовой пояс:
>>> parse ("Thu Sep 25 10:36:28 BRST 2003", ignoretz = True)
дата и время.datetime (2003, 9, 25, 10, 36, 28)
То же, что и обработка строки без часового пояса:
>>> parse ("Чт, 25 сентября, 10:36:28 2003")
datetime.datetime (2003, 9, 25, 10, 36, 28)
Без года, но с передачей DEFAULT datetime для возврата в том же году, независимо от того, в каком году мы сейчас находимся:
>>> parse ("Чт, 25 сентября, 10:36:28", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 10, 36, 28)
Дальнейшая полоса:
>>> parse ("Чт, сен, 10:36:28", по умолчанию = ПО УМОЛЧАНИЮ)
дата и время.datetime (2003, 9, 25, 10, 36, 28)
>>> parse ("Чт 10:36:28", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 10, 36, 28)
>>> parse ("Чт 10:36", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 10, 36)
>>> parse ("10:36", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 10, 36)
Зачистить другим способом:
>>> parse («Чт, 25 сентября 2003 г.»)
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("25 сентября 2003 г.")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("Сентябрь 2003 г.", по умолчанию = ПО УМОЛЧАНИЮ)
дата и время.datetime (2003, 9, 25, 0, 0)
>>> parse ("Сентябрь", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("2003", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 0, 0)
Другой формат, основанный на дате -R (RFC822):
>>> parse ("Чт, 25.09.2003 10:49:41 -0300")
datetime.datetime (2003, 9, 25, 10, 49, 41,
tzinfo = tzoffset (Нет, -10800))
Формат ISO:
>>> parse ("2003-09-25T10: 49: 41.5-03: 00 ")
datetime.datetime (2003, 9, 25, 10, 49, 41, 500000,
tzinfo = tzoffset (Нет, -10800))
Некоторые варианты:
>>> parse ("2003-09-25T10: 49: 41")
datetime.datetime (2003, 9, 25, 10, 49, 41)
>>> parse ("2003-09-25T10: 49")
datetime.datetime (2003, 9, 25, 10, 49)
>>> parse ("2003-09-25T10")
datetime.datetime (2003, 9, 25, 10, 0)
>>> parse ("2003-09-25")
datetime.datetime (2003, 9, 25, 0, 0)
Формат ISO, без разделителей:
>>> parse ("20030925T104941.5-0300 ")
datetime.datetime (2003, 9, 25, 10, 49, 41, 500000,
tzinfo = tzoffset (Нет, -10800))
>>> parse ("20030925T104941-0300")
datetime.datetime (2003, 9, 25, 10, 49, 41,
tzinfo = tzoffset (Нет, -10800))
>>> parse ("20030925T104941")
datetime.datetime (2003, 9, 25, 10, 49, 41)
>>> parse ("20030925T1049")
datetime.datetime (2003, 9, 25, 10, 49)
>>> parse ("20030925T10")
datetime.datetime (2003, 9, 25, 10, 0)
>>> parse ("20030925")
дата и время.datetime (2003, 9, 25, 0, 0)
Все вместе.
>>> parse ("1997000")
datetime.datetime (1997, 9, 2, 9, 0)
>>> parse ("199709020")
datetime.datetime (1997, 9, 2, 9, 0, 59)
Заказ на разные даты:
>>> parse ("2003-09-25")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("25 сентября 2003 г.")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("25 сентября 2003 г.")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("25 сен-2003")
дата и время.datetime (2003, 9, 25, 0, 0)
>>> parse ("25.09.2003")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("25-09-2003")
datetime.datetime (2003, 9, 25, 0, 0)
Отметьте двусмысленные даты:
>>> parse ("10-09-2003")
datetime.datetime (2003, 10, 9, 0, 0)
>>> parse ("10-09-2003", dayfirst = True)
datetime.datetime (2003, 9, 10, 0, 0)
>>> parse ("10-09-03")
datetime.datetime (2003, 10, 9, 0, 0)
>>> parse ("10-09-03", yearfirst = True)
дата и время.datetime (2010, 9, 3, 0, 0)
Допускаются другие разделители дат:
>>> parse ("2003.Sep.25")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("2003/09/25")
datetime.datetime (2003, 9, 25, 0, 0)
Даже с пробелами:
>>> parse ("25 сентября 2003 г.")
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("2003 09 25")
datetime.datetime (2003, 9, 25, 0, 0)
Часы работы с письмами:
>>> parse ("10х46м28.5 с ", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 10, 36, 28, 500000)
>>> parse ("01s02h03m", по умолчанию = DEFAULT)
datetime.datetime (2003, 9, 25, 2, 3, 1)
>>> parse ("01h02m03", по умолчанию = DEFAULT)
datetime.datetime (2003, 9, 25, 1, 2, 3)
>>> parse ("01h02", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 1, 2)
>>> parse ("01h02s", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 1, 0, 2)
С AM / PM:
>>> parse ("10 часов утра", по умолчанию = ПО УМОЛЧАНИЮ)
дата и время.datetime (2003, 9, 25, 10, 0)
>>> parse ("10 вечера", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 22, 0)
>>> parse ("12:00 am", по умолчанию = DEFAULT)
datetime.datetime (2003, 9, 25, 0, 0)
>>> parse ("12 вечера", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 12, 0)
Некоторые особые правила для отношений «принадлежность»:
>>> parse ("03 сентября", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 3, 0, 0)
>>> parse ("Сентябрь 03", по умолчанию = ПО УМОЛЧАНИЮ)
datetime.datetime (2003, 9, 25, 0, 0)
Нечеткий анализ:
>>> s = "Сегодня ровно 25 сентября 2003 года" \
... "в 10:49:41 с часовым поясом -03: 00."
>>> parse (s, fuzzy = True)
datetime.datetime (2003, 9, 25, 10, 49, 41,
tzinfo = tzoffset (Нет, -10800))
Другие случайные форматы:
>>> parse ("среда, 10 июля 1996 г.")
datetime.datetime (1996, 7, 10, 0, 0)
>>> parse ("1996.07.10 в 15:08:56 PDT", ignoretz = True)
datetime.datetime (1996, 7, 10, 15, 8, 56)
>>> parse ("Вторник, 12 апреля 1952 г., 15:30:42 PST", ignoretz = True)
datetime.datetime (1952, 4, 12, 15, 30, 42)
>>> parse ("5 ноября 1994 г., 8:15:30 EST", ignoretz = True)
дата и время.datetime (1994, 11, 5, 8, 15, 30)
>>> parse ("3 мая 2001 г.")
datetime.datetime (2001, 5, 3, 0, 0)
>>> parse ("5:50 13 июня 1990 г.")
datetime.datetime (1990, 6, 13, 5, 50)
Заменить parserinfo на пользовательскую parserinfo
>>> из dateutil.parser import parse, parserinfo
>>> класс CustomParserInfo (parserinfo):
... # например отредактируйте свойство parserinfo, чтобы разрешить пользовательский 12-часовой формат
... AMPM = [("am", "a", "xm"), ("pm", "p")]
>>> parse ('2018-06-08 12:06:58 XM', parserinfo = CustomParserInfo ())
дата и время.datetime (2018, 6, 8, 0, 6, 58)
>>> из импорта даты и времени * >>> от dateutil import tz >>> datetime.now () datetime.datetime (2003, 9, 27, 9, 40, 1, 521290) >>> datetime.now (tz.UTC) datetime.datetime (2003, 9, 27, 12, 40, 12, 156379, tzinfo = tzutc ()) >>> datetime.now (tz.UTC) .tzname () 'УНИВЕРСАЛЬНОЕ ГЛОБАЛЬНОЕ ВРЕМЯ'
>>> из импорта даты и времени *
>>> из импорта dateutil.tz *
>>> datetime.now (tzoffset ("BRST", -10800))
дата и время.datetime (2003, 9, 27, 9, 52, 43, 624904,
tzinfo = tzinfo = tzoffset ('BRST', -10800))
>>> datetime.now (tzoffset ("BRST", -10800)). tzname ()
'BRST'
>>> datetime.now (tzoffset ("BRST", -10800)). astimezone (UTC)
datetime.datetime (2003, 9, 27, 12, 53, 11, 446419,
tzinfo = tzutc ())
>>> из импорта даты и времени *
>>> из импорта dateutil.tz *
>>> datetime.now (tzlocal ())
datetime.datetime (2003, 9, 27, 10, 1, 43, 673605,
tzinfo = tzlocal ())
>>> datetime.сейчас (tzlocal ()). tzname ()
'BRST'
>>> datetime.now (tzlocal ()). astimezone (tzoffset (Нет, 0))
datetime.datetime (2003, 9, 27, 13, 3, 0, 11493,
tzinfo = tzoffset (Нет, 0))
Вот примеры распознанных форматов:
- EST5EDT
- EST5EDT4, M4.1.0 / 02: 00: 00, M10-5-0 / 02: 00
- EST5EDT4,95 / 02: 00: 00,298 / 02: 00
- EST5EDT4, J96 / 02: 00: 00, J299 / 02: 00
Обратите внимание, что если информация о дневном свете отсутствует, но было предоставлено сокращение дневного света, tzstr будет следовать соглашение об использовании первого воскресенья апреля для начала дневного света сохранение, и последнее воскресенье октября, чтобы закончить его.Если start или время окончания не указано, будет использоваться 2 часа ночи, а если дневной свет смещения нет, стандартное смещение плюс один час будет использоваться. Это соглашение такое же, как в GNU libc.
Это также означает, что некоторые из приведенных выше примеров в точности эквивалентны, и все эти примеры эквивалентны в 2003 году.
Вот пример, упомянутый в
[https://docs.python.org/3/library/time.html документация модуля времени].
>>> ос.Environment ['TZ'] = 'EST + 05EDT, M4.1.0, M10.5.0'
>>> time.tzset ()
>>> time.strftime ('% X% x% Z')
'02: 07: 36 05.08.03 EDT '
>>> os.environ ['TZ'] = 'AEST-10AEDT-11, M10.5.0, M3.5.0'
>>> time.tzset ()
>>> time.strftime ('% X% x% Z')
'16: 08: 12 05.08.03 AEST '
А вот пример, показывающий ту же информацию с использованием tzstr , не касаясь системных настроек.
>>> tz1 = tzstr ('EST + 05EDT, M4.1.0, M10.5.0')
>>> tz2 = tzstr ('AEST-10AEDT-11, M10.5.0, M3.5.0 ')
>>> dt = datetime (2003, 5, 8, 2, 7, 36, tzinfo = tz1)
>>> dt.strftime ('% X% x% Z')
'02: 07: 36 05.08.03 EDT '
>>> dt.astimezone (tz2) .strftime ('% X% x% Z')
'16: 07: 36 05/08/03 AEST '
Действительно ли они эквивалентны?
>>> tzstr ('EST5EDT') == tzstr ('EST5EDT, M4.1.0, M10.5.0')
Истинный
Проверьте ограничение дневного света.
>>> tz = tzstr ('EST + 05EDT, M4.1.0, M10.5.0')
>>> datetime (2003, 4, 6, 1, 59, tzinfo = tz).tzname ()
'СТАНДАРТНОЕ ВОСТОЧНОЕ ВРЕМЯ'
>>> datetime (2003, 4, 6, 2, 00, tzinfo = tz) .tzname ()
'EDT'
>>> datetime (2003, 10, 26, 0, 59, tzinfo = tz) .tzname ()
'EDT'
>>> datetime (2003, 10, 26, 2, 00, tzinfo = tz) .tzname ()
'СТАНДАРТНОЕ ВОСТОЧНОЕ ВРЕМЯ'
>>> tzstr ('EST5EDT') == tzrange ("EST", -18000, "EDT")
Истинный
>>> из импорта dateutil.relativedelta *
>>> range1 = tzrange ("EST", -18000, "EDT")
>>> range2 = tzrange ("EST", -18000, "EDT", -14400,
... relativedelta (часы = + 2, месяц = 4, день = 1,
... будний день = SU (+1)),
... relativedelta (часы = + 1, месяц = 10, день = 31,
... день недели = SU (-1)))
>>> tzstr ('EST5EDT') == диапазон1 == диапазон2
Истинный
Обратите внимание на небольшую деталь в последнем примере: в то время как летнее время должно закончиться в 2 часа ночи дельта поймает 1 час ночи. Это потому, что летнее время время должно закончиться в 2 часа ночи по стандартному времени (разница между STD и Летнее время в данном примере составляет 1 час) вместо времени летнего времени. Вот как подтипы tzinfo должны иметь дело с дополнительным часом, который происходит при возвращении к стандартному времени.Чек
[https://docs.python.org/3/library/datetime.html#datetime.tzinfo tzinfo документация]
для получения дополнительной информации.
>>> tz = tzfile ("/ etc / localtime")
>>> datetime.now (tz)
datetime.datetime (2003, 9, 27, 12, 3, 48, 392138,
tzinfo = tzfile ('/ и т.д. / локальное время'))
>>> datetime.now (tz) .astimezone (UTC)
datetime.datetime (2003, 9, 27, 15, 3, 53, 70863,
tzinfo = tzutc ())
>>> datetime.now (tz) .tzname ()
'BRST'
>>> datetime (2003, 1, 1, tzinfo = tz).tzname ()
"BRDT"
Проверьте ограничение дневного света.
>>> tz = tzfile ('/ usr / share / zoneinfo / EST5EDT')
>>> datetime (2003, 4, 6, 1, 59, tzinfo = tz) .tzname ()
'СТАНДАРТНОЕ ВОСТОЧНОЕ ВРЕМЯ'
>>> datetime (2003, 4, 6, 2, 00, tzinfo = tz) .tzname ()
'EDT'
>>> datetime (2003, 10, 26, 0, 59, tzinfo = tz) .tzname ()
'EDT'
>>> datetime (2003, 10, 26, 1, 00, tzinfo = tz) .tzname ()
'СТАНДАРТНОЕ ВОСТОЧНОЕ ВРЕМЯ'
Вот пример файла, извлеченного из RFC. Этот файл определяет часовой пояс EST5EDT , который будет использоваться в следующем примере.
НАЧАЛО: VTIMEZONE TZID: Восточная часть США ОБНОВЛЕНО: 19870101T000000Z TZURL: http: //zones.stds_r_us.net/tz/US-Eastern НАЧАТЬ: СТАНДАРТ DTSTART: 19671029T020000 ПРАВИЛО: FREQ = YEARLY; BYDAY = -1SU; BYMONTH = 10 TZOFFSETFROM: -0400 ТЗОФФСЕТТО: -0500 TZNAME: EST КОНЕЦ: СТАНДАРТ НАЧАТЬ: ДЕНЬ DTSTART: 19870405T020000 ПРАВИЛО: FREQ = YEARLY; BYDAY = 1SU; BYMONTH = 4 TZOFFSETFROM: -0500 ТЗОФФСЕТТО: -0400 TZNAME: EDT КОНЕЦ: ДЕНЬ КОНЕЦ: VTIMEZONE
А вот пример исследования типа tzical :
>>> от dateutil.tz import *; из импорта даты и времени *
>>> tz = tzical ('образцы / EST5EDT.ics')
>>> tz.keys ()
['Восточная часть США']
>>> est = tz.get ('Восток США')
>>> est
>>> datetime.now (est)
datetime.datetime (2003, 10, 6, 19, 44, 18, 667987,
tzinfo = )
>>> est == tz.get ()
Истинный
Проверим дневной свет, как обычно:
>>> datetime (2003, 4, 6, 1, 59, tzinfo = est).tzname () 'СТАНДАРТНОЕ ВОСТОЧНОЕ ВРЕМЯ' >>> datetime (2003, 4, 6, 2, 00, tzinfo = est) .tzname () 'EDT' >>> datetime (2003, 10, 26, 0, 59, tzinfo = est) .tzname () 'EDT' >>> datetime (2003, 10, 26, 1, 00, tzinfo = est) .tzname () 'СТАНДАРТНОЕ ВОСТОЧНОЕ ВРЕМЯ'
>>> tz = tzwin ("Стандартное время Восточной Америки")
parseFloat () — JavaScript | MDN
Функция parseFloat () анализирует
аргумент (преобразуя его сначала в строку, если необходимо) и возвращает плавающее
номер точки.
Исходный код этого интерактивного примера хранится в репозитории GitHub. Если вы хотите внести свой вклад в проект интерактивных примеров, клонируйте https://github.com/mdn/interactive-examples и отправьте нам запрос на перенос.
Параметры
-
строка - Значение для синтаксического анализа. Если этот аргумент не является строкой, он преобразуется в один
с использованием
ToStringаннотация операция. Начальные пробелы в этом аргументе игнорируются.
Возвращаемое значение
Число с плавающей запятой, полученное из заданной строки .
или NaN , когда первый непробельный символ не может быть преобразован в
номер.
parseFloat — это свойство функции глобального объекта.
- Если
parseFloatвстречает символ, отличный от знака плюс (+), знак минус (-U + 002D ДЕФИС-МИНУС), цифра (0—9), десятичная точка (.), или показатель степени (eилиE), он возвращает значение до этого символа, игнорирование недопустимого символа и следующих за ним символов. - вторая десятичная точка также останавливает синтаксический анализ (символы до этой точки все равно будет разбираться).
- Начальные и конечные пробелы в аргументе игнорируются.
- Если первый символ аргумента не может быть преобразован в число (это не
вышеуказанные символы),
parseFloatвозвращаетNaN. -
parseFloatтакже может анализировать и возвращатьInfinity. -
parseFloatпреобразует синтаксисBigIntвNumbers, теряя точность. Это происходит потому, что конечныйnсимвол отбрасывается.
Рассмотрим Число (значение) для более строгого анализа, которое преобразуется в NaN для аргументов с недопустимыми символами в любом месте.
parseFloat будет анализировать нестроковые объекты, если у них есть toString или valueOf метод.Возвращаемое значение такое же, как если бы был вызван parseFloat .
на результате этих методов.
parseFloat возвращает число Все следующие примеры возвращают 3,14 :
parseFloat (3.14);
parseFloat ('3,14');
parseFloat ('3,14');
parseFloat ('314e-2');
parseFloat ('0,0314E + 2');
parseFloat ('3.14 некоторые нецифровые символы');
parseFloat ({toString: function () {return "3,14"}});
parseFloat возвращает NaN В следующем примере возвращается NaN :
parseFloat ('FF2');
parseFloat и BigInt Оба следующих примера возвращают
parseFloat (9925474099267n);
parseFloat ('9925474099267n');
Таблицы BCD загружаются только в браузере
SyntaxError: JSON.parse: плохой синтаксический анализ — JavaScript
Исключения JavaScript, вызываемые JSON.parse () , возникают при сбое строки
для анализа как JSON.
SyntaxError: JSON.parse: незавершенный строковый литерал
SyntaxError: JSON.parse: неправильный управляющий символ в строковом литерале
SyntaxError: JSON.parse: недопустимый символ в строковом литерале
SyntaxError: JSON.parse: неправильный escape-код Unicode
SyntaxError: JSON.parse: неправильный escape-символ
SyntaxError: JSON.parse: незавершенная строка
SyntaxError: JSON.синтаксический анализ: без числа после знака минус
SyntaxError: JSON.parse: неожиданный нецифровой
SyntaxError: JSON.parse: пропущенные цифры после десятичной точки
SyntaxError: JSON.parse: незавершенное дробное число
SyntaxError: JSON.parse: пропущенные цифры после индикатора экспоненты
SyntaxError: JSON.parse: пропущенные цифры после знака экспоненты
SyntaxError: JSON.parse: в экспоненциальной части отсутствует число
SyntaxError: JSON.parse: неожиданный конец данных
SyntaxError: JSON.parse: неожиданное ключевое слово
SyntaxError: JSON.parse: неожиданный символ
SyntaxError: JSON.parse: конец данных при чтении содержимого объекта
SyntaxError: JSON.parse: ожидаемое имя свойства или '}'
SyntaxError: JSON.parse: конец данных, когда ожидалось ',' или ']'
SyntaxError: JSON.parse: ожидаемый ',' или ']' после элемента массива
SyntaxError: JSON.parse: конец данных, когда ожидалось имя свойства
SyntaxError: JSON.parse: ожидаемое имя свойства в двойных кавычках
SyntaxError: JSON.parse: конец данных после имени свойства, когда ожидалось ':'
SyntaxError: JSON.parse: expected ':' после имени свойства в объекте
SyntaxError: JSON.анализ: конец данных после значения свойства в объекте
SyntaxError: JSON.parse: ожидаемый ',' или '}' после значения свойства в объекте
SyntaxError: JSON.parse: ожидаемый ',' или '}' после пары свойство-значение в литерале объекта
SyntaxError: JSON.parse: имена свойств должны быть строками в двойных кавычках
SyntaxError: JSON.parse: ожидаемое имя свойства или '}'
SyntaxError: JSON.parse: неожиданный символ
SyntaxError: JSON.parse: неожиданный непробельный символ после данных JSON
SyntaxError: JSON.parse Ошибка: недопустимый символ в позиции {0} (край) JSON.parse () анализирует строку как JSON. Эта строка должна быть действительным JSON.
и выдаст эту ошибку, если обнаружен неправильный синтаксис.
JSON.parse () не работает
разрешить завершающие запятыеОбе строки выдадут SyntaxError:
JSON.parse ('[1, 2, 3, 4,]');
JSON.parse ('{"фу": 1,}');
Чтобы правильно разобрать JSON, опустите запятые:
JSON.parse ('[1, 2, 3, 4]');
JSON.parse ('{"фу": 1}'); Названия свойств должны быть заключены в двойные кавычки. strings
Вы не можете заключать свойства в одинарные кавычки, например ‘foo’.
JSON.parse ("{'foo': 1}");
Вместо этого напишите «foo»:
JSON.parse ('{"foo": 1}'); Начальные нули и десятичные точки
Нельзя использовать начальные нули, такие как 01, а после десятичных точек должен следовать как минимум одна цифра.
JSON.parse ('{"foo": 01}');
JSON.parse ('{"фу": 1.}');
Вместо этого напишите 1 без нуля и используйте хотя бы одну цифру после десятичной точки:
JSON.parse ('{"foo": 1}');
JSON.parse ('{"foo": 1.0}');
Анализировать предсказуемые шаблоны с помощью привязки
- Последнее обновление
- Сохранить как PDF
- Синтаксис
- Параметры
- Правила
- Инструмент пользовательского интерфейса привязки синтаксического анализа
- Примеры
- Поля имен со специальными символами
- Использование разрывов строк в качестве привязки
Оператор синтаксического анализа (также называемый привязкой синтаксического анализа) выполняет синтаксический анализ строки в соответствии с указанными начальными и конечными привязками, а затем помечают их как поля для использования в последующих функциях агрегирования в запросе, таких как сортировка, группировка или другие функции.
В этом разделе описывается, как использовать инструмент пользовательского интерфейса привязки синтаксического анализа для добавления синтаксического анализа к запросу, а также подробно рассказывается о структуре оператора привязки синтаксического анализа.
Синтаксис
-
| проанализировать "* " как -
| синтаксический анализ "* " как [nodrop] -
| проанализировать [field =] " * " как
Опции
- Параметр
nodropпринудительно включает в результаты также сообщения, не соответствующие какому-либо сегменту термина синтаксического анализа.Для получения дополнительной информации см. Parse nodrop. - Параметр
field = fieldnameпозволяет указать поле для синтаксического анализа, отличное от сообщения по умолчанию. Подробнее см. Поле анализа.
Правила
- Создаваемые пользователем поля, такие как извлеченные или проанализированные поля, могут быть названы с использованием буквенно-цифровых символов и подчеркиваний (
_). Поля должны начинаться с буквенно-цифрового символа. - Если поле не указано, используется весь текст входящих сообщений.
- Подстановочный знак используется в качестве заполнителя для извлеченного поля. Подстановочные знаки должны быть разделены пробелом или другим символом.
**недействителен. Вместо этого используйте другой оператор синтаксического анализа, например регулярное выражение синтаксического анализа. - Количество подстановочных знаков в строке шаблона должно соответствовать количеству переменных.
- Для одного оператора синтаксического анализа разрешено несколько извлечений.
- Символы, заключенные в двойные кавычки (а не в одинарные), являются строковыми литералами.Используйте обратную косую черту, чтобы избежать двойных кавычек в строке. Например:
-
| проанализировать "\" уровень \ ": *," как уровень
-
Анализатор пользовательского интерфейса привязки
Вы можете использовать инструмент пользовательского интерфейса привязки синтаксического анализа, чтобы выделить текст сообщения для синтаксического анализа, определить поля синтаксического анализа и выполнить действие синтаксического анализа.
Для синтаксического анализа с помощью инструмента привязки синтаксического анализа:
- Запустите поиск.
- В результатах поиска найдите сообщение с текстом, который нужно проанализировать.
- Выделите текст, щелкните правой кнопкой мыши и выберите Анализировать выделенный текст .
Откроется диалоговое окно Анализ текста , в котором отображается выделенный вами текст.
- Выделите текст для первого поля анализа и щелкните Щелкните, чтобы извлечь это значение .
Выделенный текст заменен звездочкой (*).
В этом примере снимка экрана GET является привязкой синтаксического анализа, а выделенный текст, который следует за ним, является первым полем синтаксического анализа. - Введите имя (без пробелов) для поля анализа в области Поля .
- Если вы хотите проанализировать дополнительные поля, добавьте запятую после имени поля и повторите действие синтаксического анализа. На следующем снимке экрана показаны три проанализированных поля: url , status_code и size (в указанном порядке). Обратите внимание, что три поля соответствуют трем звездочкам в тексте синтаксического анализа.
- Нажмите Отправить .
Снова откроется страница поиска, на которой будет показан только что созданный оператор синтаксического анализа, добавленный в поиск. - Нажмите Пуск , чтобы отобразить результаты поиска, которые теперь показывают проанализированное сообщение.
Примеры
Пример сообщения журнала:
2 августа 04:06:08: host = 10.1.1.124: local / ssl2 notice mcpd [3772]: [email protected]: severity = warning: 01070638: 5: член пула 172.31.51.22:0 состояние монитора отключено.
В следующих примерах start_anchor — это «user =» , а stop_anchor — «:» , который завершает адрес электронной почты.Звездочка ( * ) — это глобус, представляющий проанализированный термин. В примерах создается новое поле для каждого сообщения с именем «user» , и это поле будет содержать значение адреса электронной почты, в данном случае jsmith @ demo.com .
... | проанализируйте "user = *:" как пользователь
Оператор синтаксического анализа также позволяет извлекать несколько полей одной командой:
... | проанализировать "user = *: severity = *:" как user, severity | ...
В этом примере создаются два поля из примера сообщения журнала: user = jsmith @ demo.com и серьезность = предупреждение .
Поля имен со специальными символами
Вы можете создавать имена полей, содержащие специальные символы, например пробелы, дефисы, обратные или прямые косые черты, используя следующий синтаксис:
... | проанализировать "<строка>" как% "<имя поля со специальными символами>"
Например, этот запрос позволит вам разобрать фразу «ID класса», включая пробел:
... | проанализировать "[Классификация: *]" как% "ID класса"
extract "\ [Классификация :(? . *) \]" | class_id как% "ID класса" Использовать разрывы строк в качестве привязки
Если ваши журналы доставляются в многострочном формате, вы можете выполнить синтаксический анализ до разрыва строки в сообщении. Для этого используйте следующие регулярные выражения в качестве якоря остановки на разрыве строки:
Журналы Linux: \ n
Журналы Windows: \ r
Например, если у нас в журналах есть следующее сообщение:
12: 08: 10,651 INFO sample_server ReportEmailer: 178 - ОТЛАДКА ОТПРАВКИ СООБЩЕНИЯ:
Кому: example @ sumologic.com
Тема: Новые разрывы строк в сообщении
, чтобы получить адрес «Кому:», вы можете использовать следующие запросы:
... | проанализировать "To: * \ n" как toAddress
или
... | проанализировать "To: * \ r" как toAddress
, который возвращает [email protected] в столбце toAddress.
dpkt Учебное пособие № 2: Анализ файла PCAP
Как мы показали в первом дпкт учебник, dpkt делает это просто создавать пакеты.dpkt одинаково полезен для разбора пакетов и файлы, поэтому во втором уроке мы продемонстрируем разбор PCAP файл и пакеты, содержащиеся в нем.
dpkt — прекрасный фреймворк для создания и парсинг пакетов. Хотя у dpkt не так много документации, однажды вы освоите один модуль, остальные встают на свои места. с легкостью. Я буду делать несколько руководств по dpkt с простыми задачами в надеется предоставить некоторую «документацию на примерах». Если у тебя есть задачи, которые вы хотели бы видеть выполненными в dpkt, напишите мне.
В этом руководстве мы не только покажем, как анализировать необработанный файл PCAP. формат, но также как анализировать пакеты, содержащиеся в файле PCAP. Давайте начнем!
Давайте проанализируем ранее записанный файл PCAP, test.pcap, который содержит некоторые сеансы HTTP. Если мы посмотрим на модуль dpkt / pcap.py, мы увидим, что он предлагает класс Reader, который принимает файловый объект и предоставляет аналогичный интерфейс к pypcap для чтения записей из файла. Давайте сначала откроем test.pcap с классом Reader:
f = открытый ('test.pcap ')
pcap = dpkt.pcap.Reader (f)
Теперь мы можем взаимодействовать через объект pcap и получать доступ к каждому пакету содержится в дампе. Например, мы можем распечатать метку времени и длина пакета данных каждой записи:
>>> для ts, buf в pcap:
>>> вывести ts, len (buf)
12208,61 66
12208,68 66
...
Конечно, было бы гораздо полезнее разбирать пакетные данные в более удобная, удобная форма. Используя dpkt, мы можем просто передать необработанный буфер в соответствующий класс dpkt и его содержимое будет автоматически проанализировано и декодируется в дружественные объекты Python:
для ts, buf в pcap:
eth = dpkt.ethernet.Ethernet (buf)
Передача пакетных данных в класс Ethernet dpkt приведет к синтаксическому анализу и декодированию это в объект eth. Поскольку класс Ethernet dpkt также содержит некоторые дополнительная магия для анализа протоколов более высокого уровня, которые распознаются, мы видим что информация об уровне IP и TCP также была декодирована:
>>> печать eth
Ethernet (src = '\ x00 \ x1a \ xa0kUf', dst = '\ x00 \ x13I \ xae \ x84,', data = IP (src = '\ xc0 \ xa8 \ n \ n',
off = 16384, dst = 'C \ x17 \ x030', sum = 25129, len = 52, p = 6, id = 51105, data = TCP (seq = 9632694,
off_x2 = 128, ack = 3382015884, win = 54, sum = 65372, flags = 17, dport = 80, sport = 56145)))
Как видно из выходных данных, eth — это объект Ethernet, pkt.данные объект IP, а pkt.data.data — объект TCP. Мы можем назначить ссылки на эти объекты в более дружественной форме:
ip = eth.data
tcp = ip.data
Затем мы можем исследовать атрибуты различных объектов как обычно. За Например, мы можем посмотреть на исходный и целевой порты TCP заголовок:
>>> печать tcp.sport
56145
>>> распечатать tcp.dport
80
Конечно, поскольку мы знаем, что этот дамп пакета содержит сеансы HTTP, мы также можем захотеть выполнить синтаксический анализ за пределами уровня TCP и декодировать HTTP Запросы.Для этого мы убедимся, что наш порт назначения — 80 (указывает на запрос, а не на ответ) и что есть данные за пределами уровня TCP, доступного для анализа. Мы будем использовать HTTP от dpkt декодер для анализа данных:
, если tcp.dport == 80 и len (tcp.data)> 0:
http = dpkt.http.Request (tcp.data)
После того, как полезная нагрузка HTTP проанализирована, мы можем изучить ее различные атрибуты:
>>> распечатать http.method
ПОЛУЧАТЬ
>>> напечатайте http.ури
/ testurl
>>> распечатать http.version
1.1
>>> напечатать http.headers ['user-agent']
Mozilla / 5.0 (X11; U; Linux x86_64; en-US; rv: 1.9.0.5)
Для целей нашей обучающей программы мы просто выведем Атрибут http.uri.
На этом мы завершаем наше руководство по синтаксическому анализу файла PCAP и пакетов. внутри. Всего за 10 простых строк на Python мы создали мощный инструмент, который читает необработанный файл PCAP, анализирует и декодирует Ethernet, IP, Уровни TCP и HTTP и выводят URI HTTP-запросов.
Полный скрипт Python для этого руководства:
#! / Usr / bin / env питон
импортный дпкт
f = открытый ('test.pcap')
pcap = dpkt.pcap.Reader (f)
для ts, buf в pcap:
eth = dpkt.ethernet.Ethernet (buf)
ip = eth.data
tcp = ip.data
если tcp.dport == 80 и len (tcp.data)> 0:
http = dpkt.http.Request (tcp.data)
напечатать http.uri
f.close ()
Введение в парсеры. Парсинг — это на удивление сложно… | автор: Chet Corcos
Разбор — удивительно сложная задача.Неудивительно, что я часто рассматриваю простые проблемы синтаксического анализа как вопросы интервью. В своих проектах я мучил себя, пытаясь найти надежные и эффективные способы очистки данных с веб-сайтов. Я не мог найти много помощи в Интернете, за исключением людей, которые говорили, что с использованием регулярных выражений — плохой подход .
Оглядываясь назад, я могу сказать, что это был один из тех случаев, когда я просто не знал правильных ключевых слов для поиска. Я наконец-то чувствую, что все понял, но это был долгий путь, наполненный академическим жаргоном, который было трудно понять и часто неправильно использовали.Цель этой статьи — сделать более доступными теорию и практику парсеров.
Я собираюсь начать с некоторой теории о формальных грамматиках, потому что я обнаружил, что очень полезно понимать, когда люди начинают подбрасывать причудливые слова, такие как контекстно-зависимая грамматика и тому подобное. Во второй половине этой статьи мы создадим синтаксический анализатор с нуля, чтобы вы могли выбросить его из головы в своем следующем интервью. Это не для быстрого чтения, поэтому убедитесь, что у вас есть чашка хорошего кофе и свежий ум, прежде чем продолжить.
Теория синтаксических анализаторов уходит корнями в основополагающую статью Ноама Хомски в 1956 году, « Три модели для описания языка» . В этой статье он описывает иерархию Хомского четырех классов формальных грамматик. Каждый из них является подмножеством другого, отличающегося сложностью алгоритма, необходимого для их проверки. Мы рассмотрим их один за другим.
Тип 3 — обычные языки
Языки типа 3 называются обычными языками .Все, что вы можете сопоставить с регулярным выражением, является прекрасным примером регулярного языка — отсюда и название «регулярное выражение». Любой регулярный язык может быть решен с помощью детерминированных конечных автоматов (DFA). Для менее знакомых, DFA — это программа, которая может быть представлена как фиксированный набор состояний (узлов) и переходов (ребер). На основе этой идеи есть несколько замечательных инструментов визуализации регулярных выражений. Например, посмотрите этот:
Детерминированный конечный автомат, представляющий следующее регулярное выражение: / -? [0–9] + \.? [0–9] * /John : Некоторые механизмы регулярных выражений на самом деле более мощные, чем интерпретация только обычных языков. Движок Oniguruma, который использует Ruby, является прекрасным примером.
Я: Эй!
Тип 2 — контекстно-свободные языки
Языки типа 2 называются контекстно-свободными (также известными как CFG для контекстно-свободной грамматики) и могут быть представлены как выталкивающие автоматы, которые являются автоматами, которые могут поддерживать некоторое состояние с куча.п | n> = 0}
Если бы мы попытались записать это как регулярное выражение, , мы бы начали с написания чего-нибудь вроде 0 {n} 1 {n} . Но это неправильное регулярное выражение, потому что нам нужно было бы точно указать, что такое n , следовательно, это не обычный язык. Однако мы можем проверить эту грамматику с помощью автоматов выталкивания, используя следующую процедуру:
- Если вы видите 0, поместите его в стек и вернитесь к (1).
- Если вы видите 1, вытащите элемент из стопки и вернитесь к (2).
- Если стек пуст, мы проверили, что строка ввода «на языке».
Джон : У меня было много ситуаций, когда мне нужно было разобрать сбалансированные скобки, и я думаю, что это более благоприятный случай для программистов.
Я: Хорошее замечание! Это простой случай проблемы сбалансированных скобок.
Обычный способ определения контекстно-свободных грамматик — с помощью формы Бэкуса-Наура (BNF).Это отличная статья, объясняющая, как работает BNF, общие расширения для BNF (обычно называемые EBNF или ABNF), а также объясняется, как работают нисходящие (LL) и восходящие (LR) парсеры. Некоторые другие распространенные термины, которые вы можете услышать, — это SLR, CLR, LALR, и этот комментарий StackOverflow хорошо проясняет их.
Вы также можете услышать о так называемой грамматике синтаксического анализа (PEG). PEG — это то же самое, что и CFG, за исключением того, что это однозначный и жадный — если вы программист, а не математик, PEG чаще всего является тем, о чем вы думаете.
Неопределенность вызывает боль. Markdown — хороший пример неоднозначной грамматики, и это основная причина, по которой парсеры Markdown не имеют формального определения грамматики BNF. Следующие примеры представляют собой ожидаемые результаты синтаксического анализа, основанные на последней спецификации CommonMark.
*** полужирный ** курсив * => полужирный курсив *** курсив * полужирный ** => курсив полужирный * курсив ** не полужирный * => курсив ** не полужирный
Математик может определить CFG для Markdown, используя BNF, следующим образом:
Математик сказал бы, что это действительный CFG определение и убедитесь, что три приведенных выше примера написаны «на языке».Однако, если вы были программистом, пытающимся написать синтаксический анализатор уценки, это определение CFG практически бесполезно для вас. Если бы вы интерпретировали это определение в реальном синтаксическом анализаторе, это не удалось бы, потому что программа не может быть двусмысленной. PEG будет охотно сопоставлять токены, как если бы это была настоящая программа, тогда как математика на самом деле это не заботит.
John : Анализатор Markdown — отличный пример, а неоднозначность грамматики вызывает боль.Markdown превратился в слабый стандарт.
Я: Я думаю, что на самом деле все может быть наоборот. Ознакомьтесь с последней спецификацией, чтобы узнать, как работает жирный шрифт и курсив. Смею вас потратить 15 минут на чтение этой спецификации, попытаться понять ее и написать простой синтаксический анализатор жирного шрифта и выделения, который удовлетворяет примерам 328–455. Может быть, проблема в том, что CommonMark настолько чрезмерно определен и нелеп, что на самом деле никто ему не соответствует.
Для однозначных контекстно-свободных языков, таких как C, есть всевозможные инструменты.Наиболее популярны ANTLR, Bison и YACC. На самом деле они называются компиляторами-компиляторами , потому что они не просто проверяют грамматику, они также предоставляют инструменты для создания компиляторов для этих грамматик. Есть репо с кучей примеров грамматики ANTLR, которые довольно круто проверить. В мире JavaScript вы также можете проверить PEG.js и Jison.
Тип 1 — контекстно-зависимые языки
Языки типа 1 называются контекстно-зависимыми. Они могут быть представлены автоматом, не используя больше памяти, чем длина ввода.п | n> = 0}
Мы можем проверить, что строка находится на этом языке, используя автомат с помощью следующей процедуры:
- Прочтите первый a и перезапишите его на x.
- Перейдите к первому b и замените его на x.
- Перейти к первому c и заменить его на x.
- Затем вернитесь к началу и вернитесь к (1).
- Если вы дойдете до конца строки в поисках первых a , а все они будут x ’ s, значит, мы проверили строку.
По сравнению с предыдущим примером здесь следует отметить то, что этот синтаксический анализатор поддерживает состояние путем изменения входной памяти, которая не является просто стеком.
Тип 0 — R
эксурсивно перечисляемый языковЯзыки типа 0 называются рекурсивно перечисляемым и представляют собой все, что может быть решено компьютером, то есть не проблема остановки. Простое, но досадно сложное с математикой доказательство того, что язык типа 0, но не типа 1, — это язык, который читает два регулярных выражения и определяет, представляют ли они один и тот же язык.Это хорошо известная проблема EXPSPACE, поэтому она явно не может относиться к типу 1.