Методы психологической коррекции эмоциональных нарушений у детей — Республиканский реабилитационный центр для детей и подростков с ограниченными возможностями
Психологическая коррекция эмоциональных нарушений у детей — это хорошо организованная система психологических воздействий. В основном она направлена на смягчение эмоционального дискомфорта у детей, повышение их активности и самостоятельности, устранение вторичных личностных реакций, обусловленных эмоциональными нарушениями, таких как агрессивность, повышенная возбудимость, тревожная мнительность и др.
Значительный этап работы с этими детьми — коррекция самооценки, уровня самосознания, формирование эмоциональной устойчивости и саморегуляции.
В отечественной и зарубежной психологии используются разнообразные методы, помогающие откорректировать эмоциональные нарушения у детей. Эти методы можно условно разделить на две основные группы: групповые и индивидуальные. Однако такое деление не отражает основной цели психокоррекционных воздействий.
В мировой психологии существует два подхода к психологической коррекции психического развития ребенка: психодинамический и поведенческий. Главная задача коррекции в рамках психодинамического подхода — это создание условий, снимающих внешние социальные преграды на пути развертывания интрапсихического конфликта. Успешному разрешению способствуют психоанализ, семейная психокоррекция, игры и арт-терапия. Коррекция в рамках поведенческого подхода помогает ребенку усвоить новые реакции, направленные на формирование адаптивных форм поведения, или угасание, торможение имеющихся у него дезадаптивных форм поведения. Различные поведенческие тренинги, психорегулирующие тренировки закрепляют усвоенные реакции.
Методы ПК эмоциональных нарушений у детей целесообразно разделить на две группы: основные и специальные. К основным методам ПК эмоциональных нарушений относятся методы, которые являются базисными в психодинамическом и поведенческом направления. Сюда входят игротерапия, арт-терапия, психоанализ, метод денсибилизации, аутогенной тренировки, поведенческий тренинг.
При подборе методов психокоррекции эмоциональных нарушений необходимо исходить из специфической направленности конфликта, определяющего эмоциональное неблагополучие ребенка. При внутриличностном конфликте следует использовать игровые, психоаналитические методы, методы семейной психокоррекции. При преобладании межличностных конфликтов применяют групповую психокоррекцию, способствующую оптимизации межличностных отношений, психорегулирующие тренировки с целью развития навыков самоконтроля поведения и смягчения эмоционального напряжения. Кроме того, необходимо учитывать и степень тяжести эмоционального неблагополучия ребенка.
В отечественной психологии разработаны и описаны методы группы психокоррекции преневротических нарушений у детей (Спиваковская, 1988). Рассматривая психокоррекционный процесс как систему, автор выделяет в ней основные блоки: диагностический, установочный, коррекционный и оценочный.
Диагностический блок отвечает за изучение индивидуальных особенностей ребенка, анализ факторов, способствующих его эмоциональному неблагополучию.
Перед началом психокоррекционной работы психологу необходимо выяснить влияние этих факторов на формирование у ребенка невротического конфликта. Отметим, что при анализе причины невротического конфликта у ребенка следует учитывать единство субъективных и объективных факторов возникновения и развития конфликта. Конфликт занимает центральное место в жизни ребенка, оказывается для него неразрешимым и, затягиваясь, создает аффективное напряжение, которое, в свою очередь, обостряет противоречия, повышает неустойчивость и возбудимость, углубляет и болезненно фиксирует переживания, негативно отражается на умственной работоспособности ребенка, дезорганизует его поведение.
Содержательный анализ детских конфликтов наиболее полно раскрывается в процессе игровой и продуктивной (рисование) деятельности. Целесообразно также использовать прожективные психологические методики: методику КАТ, Рене-Жиля, Розенцвейга и др.
Установочный блок включает в себя главную цель — формирование положительной установки ребенка и его родителей на занятия.
Основными задачами этого психокоррекционного блока являются:
- снижение эмоционального напряжения у ребенка;
- активизация родителей на самостоятельную психологическую работу с ребенком;
- повышение веры родителей в возможность достижения позитивных результатов психокоррекции;
- формирование эмоционально-доверительного контакта психолога с участниками психокоррекции (Спиваковская, 1988).
Для реализации этих задач используются разнообразные психотехнические приемы: организация встреч родителей, дети которых успешно закончили курс психокоррекции, с начинающими, проведение веселой, эмоционально насыщенной игры с детьми в начале психокоррекции, с привлечением родителей и прочее. Особое значение для установочного этапа психокоррекции имеет место, где проходят занятия. Это должно быть просторное, хорошо оборудованное помещение, с мягким освещением, где ребенок будет чувствовать себя спокойно и безопасно.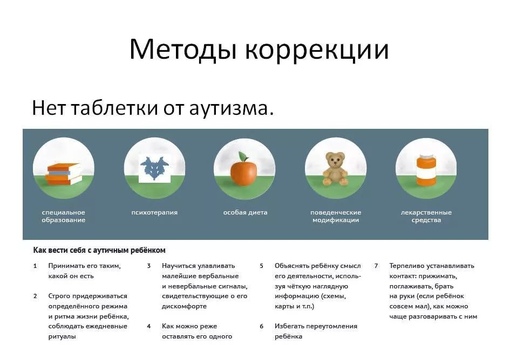
Коррекционный блок. Основной целью данного блока занятий является гармонизация процесса развития личности ребенка с эмоциональным неблагополучием.
Конкретные задачи:
- преодоление внутрисемейного кризиса;
- изменение родительских установок и позиций;
- снятие проявлений дезадаптации в поведении ребенка;
- расширение сферы социального взаимодействия ребенка;
- формирование у ребенка адекватного отношения к себе и к другим.
Внутри этого блока выделяют три основных этапа.
Первый этап — ориентировочный (2–3 занятия), где ребенку предоставляется возможность спонтанной игры. Психолог на данном этапе наблюдает за детьми, а у детей формируется положительный эмоциональный настрой на занятие, что очень важно в процессе сглаживания внутренних конфликтов. Кроме того, на данном этапе продолжается диагностика форм поведения и особенностей общения детей с целью окончательного формирования группы.
Психотехнические приемы здесь состоят из различных невербальных коммуникаций, коммуникативных игр.
Второй этап — реконструктивный, когда проводится коррекция неадекватных эмоциональных и поведенческих реакций. Психотехническими приемами на данном этапе являются сюжетно-ролевые игры, разыгрывание детьми проблемных жизненных ситуаций. Эти игры способствуют эмоциональному отреагированию и вытеснению негативных переживаний. Ребенок обучается самостоятельно находить нужные способы поведения и формы эмоционального реагирования (Спиваковская, 1988).
При оценке эффективности психологической коррекции {оценочный блок) просматриваются отчеты родителей о поведении детей в начале занятий. Разбираются поведенческие и эмоциональные реакции ребенка с помощью метода наблюдения, анализа результатов деятельности ребенка до занятий и после. Оценивая эмоциональное состояние ребенка до и после занятий, целесообразно использовать цветовой тест Люшера, методику цветописи, разработанную Лутошкиным, рисуночные тесты, а для оценки значимых межличностных отношений лучше обратиться к цветовому тесту отношений (ЦТО), адаптированному Эдкиным.
Методы психологической коррекции в деятельности педагога и психолога
Педагоги, воспитатели, психологи, социальные педагоги, руководители школ и образовательных центров
Форма обучения:
Очно-заочнаяТема 1. Понятие психологической коррекции.
Предмет психологической коррекции. ее связь с другими отраслями практической психологии (психодиагностикой, психологическим консультированием, психотерапией). Психологическая коррекция в системе профессиональной деятельности психолога. Основные принципы, цели и задачи психокоррекционной работы. Принципы психологической коррекции. Модели коррекции: общая, типовая, индивидуальная. Виды и формы психологической коррекции. Индивидуальная психокоррекция: показания к индивидуальной психокоррекции, основные методы индивидуального психокоррекционного воздействия, основные стадии индивидуальной психологической коррекции. Групповая психокоррекция: специфика групповой формы психокоррекции, особенности комплектования групп, групповая динамика, руководство психокоррекционной группой.
Принципы составления и основные виды психокоррекционных программ. Методические требования к составлению психокоррекционных программ. Структура психокоррекционного комплекса. Психокоррекционная технология и метод психологической коррекции. Психокоррекционные технологии для детей с проблемами в развитии. Организационные аспекты психокоррекционных технологий.
Оценка эффективности психокоррекционных мероприятий. Факторы, определяющие эффективность психокоррекции.
Взаимодействие психолога с клиентов в процессе осуществления психологической коррекции. Требования, предъявляемые к психологу, осуществляющему психокоррекционные мероприятия
Тема 2. Основные теоретические направления психологической коррекции.
Психодинамическое направление. Клиент центрированный подход К. Роджерса; основные понятия и техники клиент центрированного подхода. Логотерапия и ее техники. Экзистенциальное направление; основные понятия и техники экзистенциальной коррекции. Поведенческое направление. Техники поведенческой псхиокоррекции. Когнитивное направление. Особенности когнитивной псхиокоррекции, техники. Рационально-эмотивная терапия А.Эллиса, техники. Когнитивный подход А. Бека, этапы коррекционной работы, техники. Реальностная терапия У. Глассера. Трансактный анализ Э. Берна, принципы,техники. Гештальттерапия Ф. Перлза, принципы, техники. Психодрама (Я.Л.Морено). Описание методы, его формы и виды. Методики психодрамы. Игротренинг.
Поведенческое направление. Техники поведенческой псхиокоррекции. Когнитивное направление. Особенности когнитивной псхиокоррекции, техники. Рационально-эмотивная терапия А.Эллиса, техники. Когнитивный подход А. Бека, этапы коррекционной работы, техники. Реальностная терапия У. Глассера. Трансактный анализ Э. Берна, принципы,техники. Гештальттерапия Ф. Перлза, принципы, техники. Психодрама (Я.Л.Морено). Описание методы, его формы и виды. Методики психодрамы. Игротренинг.
Тема 3. Организация психокоррекционной работы с различными категориями детей с отклонениями в развитии на разных возрастных этапах
Тема 4. Психокоррекционная работа и раннее вмешательство.
Развитие системы ранней помощи детям с ОВЗ. Принципы ее построения Раннее вмешательство. Междислиплинарность как принцип раннего вмешательства. Организация психокоррекционной работы с детьми младенческого и раннего возраста (Разенкова, Е.Морозова). Раннее домашнее сопровождение. Психологическая коррекция развития ребенка, находящегося в условиях ранней депривации. Психологическая коррекция и абилитация. Психологическая коррекция в условиях Центра игровой поддержки ребенка раннего возраста.
Психологическая коррекция развития ребенка, находящегося в условиях ранней депривации. Психологическая коррекция и абилитация. Психологическая коррекция в условиях Центра игровой поддержки ребенка раннего возраста.
Тема 5. Психокоррекционная работа с дошкольниками с ОВЗ.
Основные линии психического развития и психологические новоообразования в дошкольном возрасте. Направления психологической коррекция развития дошкольников с разными видами дизонтогенеза. Психологическая профилактика и коррекция вторичных нарушений развития. Методы психологической коррекция познавательной сферы, эмоционально-волевых, поведенческих, коммуникативных нарушений. Методы психологической работы с дошкольниками, ставшими жертвами жесткого обращения.
Тема 6. Психокоррекционная работа с младшими школьниками с ОВЗ.
Основные линии психического развития и психологические новоообразования младшего школьного возраста. Профилактика и коррекция трудностей в обучении. Методы психологической коррекции школьной дезадаптации, межличностных взаимоотношений младших школьников. Методы психологической работы с младшими школьниками, ставшими жертвами жесткого обращения.
Методы психологической коррекции школьной дезадаптации, межличностных взаимоотношений младших школьников. Методы психологической работы с младшими школьниками, ставшими жертвами жесткого обращения.
Тема 7. Психокоррекционная работа с подростками с ОВЗ.
Основные линии психического развития и психологические новоообразования подросткового возраста. Профилактика и коррекция трудностей в обучении. Методы психологической коррекции процессов самосознания, межличностных взаимоотношений подростков. Профилактика и коррекция трудностей в обучении Проблема мобинга. Методы психологической коррекции полоролевой идентификации. Методы психокоррекционной работы с подростками, пережившими насилие. Методы психокоррекционной работы с подростками, имеющими отклоняющееся поведение.
Тема 8. Психокоррекционная работа со старшеклассниками с ОВЗ.
Основные линии психического развития и психологические новоообразования раннего юношеского возраста. Профилактика и коррекция трудностей в обучении. Методы психологической коррекции процессов самосознания, межличностных взаимоотношений старшеклассников. Проблема мобинга. Методы психокоррекционной работы со старшеклассниками, пережившими насилие. Методы психокоррекционной работы со старшеклассниками, имеющими отклоняющееся поведение. Психологическая коррекция профессионального самоопределения.
Методы психологической коррекции процессов самосознания, межличностных взаимоотношений старшеклассников. Проблема мобинга. Методы психокоррекционной работы со старшеклассниками, пережившими насилие. Методы психокоррекционной работы со старшеклассниками, имеющими отклоняющееся поведение. Психологическая коррекция профессионального самоопределения.
Тема 9. Психокоррекционная работа с семьей и социальной микросредой.
Типология психологических проблем родителей, воспитывающих ребенка с ОВЗ (Е.Спиваковская, Е.Синягина, А. Аксенова). Проблема формирования осознанного родительства. Семья как объект психокоррекционного воздействия.
Организация психокоррекционной работы с семьей воспитывающей ребенка с ОВЗ: принципы, задачи, методы. Составляющие психологической коррекции детско-родительских отношений. Технологии психологической коррекции детско-родительских отношений. Методики коррекции детско-родительских и семейных отношений. Семейная фотография, семейная скульптура, семейная хореография.
Игровая психокоррекция детско-родительских отношений. Родительские группы. Технология проведения семейных встреч.
Игра как метод психологической коррекции
Психологическая коррекция с детьми – это увлекательный творческий процесс, который развивает каждого участника и дает неповторимый опыт взаимодействияВажным критерием психологического здоровья человека является способность адаптироваться к окружающей среде, конструктивно взаимодействовать с другими людьми и быть активным участником социальной жизни.
Детство – это начальный этап формирования адаптационных способностей развивающейся личности. Когда ребенок живет и развивается в безопасной психологической среде, своевременно удовлетворяет свои базальные потребности в еде, сне, уходе, общении и любви, то у него формируются представления о себе и об окружающем мире. Такой ребенок научается осознавать свои потребности, находить адекватные способы удовлетворять их, принимать ответственность за свой выбор. У ребенка развивается согласованность между внутренними ощущениями, эмоциями, мыслями и действиями и не возникает трудностей в общении, потому что он гармоничен.
У ребенка развивается согласованность между внутренними ощущениями, эмоциями, мыслями и действиями и не возникает трудностей в общении, потому что он гармоничен.
Но бывает, когда с малых лет ребенок попадает в среду, которая не удовлетворяет должным образом его основным потребности. Ребенок не чувствует себя в безопасности, любви и принятии. Ему приходится прилагать большие усилия, чтобы быть замеченным и получить необходимое внимание, он тревожится и формируется недоверие к миру. Зачастую это приводит к неэффективным и разрушительным способам поведения, неуверенности в себе, тревожности, дезадаптации. Своим непослушанием, агрессией, капризами ребенок стремиться получить внимания и любовь. Он не умет иначе себя выражать, потому что окружающий его мир для него воспринимается как опасный, не понимающий.
Для благополучного психосоциального развития ребенка не достаточно объяснений и нравоучений, нужно использовать его способ общения, его язык, а именно — игру. Именно посредством игры ребенок изображает реальность так, как он в настоящий момент ее воспринимает, переживает, чувствует и понимает с учетом возрастных особенностей. А задача психолога, создать особое игровое пространство, где игра будет нести исцеляющее действие.
А задача психолога, создать особое игровое пространство, где игра будет нести исцеляющее действие.
В совместной игре с психологом, ребенок не только отражает свою действительность, но еще и параллельно трансформирует ее, позволяя себе отреагировать на не пережитые травмирующие ситуации, изменить способы поведения в конфликтах и сформировать новые навыки взаимодействия с внешним миром.
Игра не погружает ребенка в проблему, а позволяет безболезненно (экологично) разрешать ее в созданном безопасном психокоррекционном пространстве.
Иногда в психокоррекционном процессе можно столкнуться с обострением проблемных зон ребенка, что внешне проявляется как усиление негативных реакций в эмоциях, поведении. Это потому что ребенок исследует себя, проверяет среду на безопасность и принятие. Это самый ответственный момент в психокоррекции. Важно продолжать удерживать атмосферу принятия личности ребенка с учетом границ здорового взаимодействия, уважительного отношения к нему, а родителям необходимо понимать причины актуальных эмоциональных и поведенческих реакций ребенка. Ребенку важен опыт нового взаимодействия, где учитываются потребности каждого из участников психологического процесса, членов семьи и других значимых людей в его близком окружении.
Ребенку важен опыт нового взаимодействия, где учитываются потребности каждого из участников психологического процесса, членов семьи и других значимых людей в его близком окружении.
Психокоррекционное игровое пространство способствует развитию творческого потенциала ребенка, его адаптационных способностей и формированию адекватной самооценки.
Это позволяет ему стать и быть активным участником социальной жизни и чувствовать ответственность за свои потребности и решения.
Детский психолог
Сабенина Ирина Викторовна
Методики коррекции аутизма — РИА Новости, 21.01.2013
— желание уйти от контакта
— одиночество
— стремление к навязчивым стереотипным формам поведения
— необычное речевое развитие
— неадекватная реакция на сенсорные, воздействующие на органы чувств, раздражители
Методики, направленные на раннее вмешательство при аутизме:
Прикладной анализ поведения
Методика основана на научных принципах поведения, благодаря которым можно сформировать необходимый социальный набор навыков и знаний ребенка. В этой методике основную роль играет мотивация детей и система поощрения их успеха в учебе. Желаемое поведение ребенка награждается, что побуждает его действовать в нужном ключе.
В этой методике основную роль играет мотивация детей и система поощрения их успеха в учебе. Желаемое поведение ребенка награждается, что побуждает его действовать в нужном ключе.
Обучение основным реакциям
Терапия обучения основным реакциям — это концентрация на развитии у ребенка ключевых поведенческих навыков, таких как мотивация, реакция на многочисленные сигналы, самоуправление и социальная инициация. Терапия используется для обучения языковым, социальным, коммуникационным навыкам и способности к восприятию информации образовательного характера. Особое внимание также уделяется роли родителей ребенка в его адаптации/лечении.
The P.L.A.Y. Project
Программа призвана обучить родителей и специалистов осуществлять интенсивное развивающее воздействие на маленьких детей с аутизмом с целью научить их взаимодействовать с окружающим миром. Программа практикуется в США, Австралии, Канаде, Великобритании, Ирландии и Швейцарии.
The P.L.A.Y. Project при работе с детьми с расстройствами аутистического спектра следует рекомендациям Национальной академии наук:
— программа наиболее эффективна для детей в возрасте от полутора до 5 лет
— интенсивное вмешательство должно осуществляться по 25 часов в неделю
— ребенка необходимо вовлекать во взаимодействие с родителем/специалистом
— необходимо определить стратегическое направление терапии (например, развитие социальных или языковых навыков)
— родитель/специалист должен помнить, что при взаимодействии с ребенком он должен исполнять роль учителя/партнера по игре в отношении 1:1 или 1:2
«Игровое время» (Floortime/DIR)
Подход The Floortime/DIR основан на концепции развивающего вмешательства и взаимодействия с ребенком, страдающим аутизмом. В рамках программы выделяют шесть стадий развития ребенка: стадия интереса к миру, стадия привязанности, стадия двухсторонней коммуникации, стадия осознания себя и решения социальных проблем, стадия символической игры, стадия осознания эмоциональных идей и эмоционального мышления. Аутисты обычно не проходят все стадии, а останавливаются на одной из них. Задача «игрового времени» — помочь ребенку пройти через все стадии.
Аутисты обычно не проходят все стадии, а останавливаются на одной из них. Задача «игрового времени» — помочь ребенку пройти через все стадии.
Спорные и нетрадиционные методики коррекции при аутизме:
Терапия отвращения
Терапия заключающаяся в применении электрошока для контроля поведения пациентов.
«Модификация поведения», основанная на чередовании поощрений и наказаний, считается одним из самых жестоких методов лечения. Кроме того, этот метод не всегда оказывается результативным, и бывшие пациенты продолжают испытывать сложности с контролем над поведением. Однако наряду с противниками, существуют и сторонники методики, заявляющие о терапии отвращения как о крайней, но, тем не менее, действенной мере по возвращению пациентов к жизни в обществе
Хелатная терапия или хелирование
Хелирование — очищение организма от тяжёлых металлов. Симптомы отравления ртутью схожи с симптомами аутизма. К тому же у аутистов часто наблюдается повышенная концентрация ртути в эритроцитах крови или в волосах. Все это заставило исследователей предположить, что аутизм может быть следствием отравления ртутью в раннем возрасте.
Все это заставило исследователей предположить, что аутизм может быть следствием отравления ртутью в раннем возрасте.
Предполагают, что источником ртути могут являться вакцины. Для консервации вакцин применяются препараты ртути. В течение первого года жизни ребенок получает несколько прививок, и суммарная доза ртути из них получается довольно высокой. Лечение, заключающееся в выведении ртути из организма, помогает уменьшить или устранить аутичные симптомы как поведенческие, так и биохимические.
Хиропрактика
Концепция, согласно которой возникновение некоторых болезней обусловлено вывихом определенного позвонка, в связи с чем излечение этих болезней, включая аутизм, должно достигаться вправлением вывиха соответствующим ручным приемом или поколачиванием специальным деревянным молотком. Распространена в некоторых странах и не имеет достаточного научного обоснования.
Хиропрактика помогает при болях в спине, однако нет никаких доказательств того, что с ее помощью можно вылечить аутизм.
Краниосакральная терапия
Терапия основана на теории о том, что небольшое смещение швов черепа влияет на ритмические импульсы, передаваемые через черепно-мозговую жидкость. Мягкое давление на внешние области черепа (манипуляции рук специалиста на швах) позволяет изменить положения костей черепа относительно друг друга и восстановить поврежденную синхронность их движения. Налаженный ритм движения черепа в свою очередь является благоприятным условием для циркуляции спинномозговой жидкости.
Такая терапия не может вылечить ребенка, однако родители, чьи дети с расстройствами аутистического спектра подвергались данному лечению, отмечали впоследствии более спокойное поведение, более длительный визуальный контакт и повышение вербальной общительности своих детей.
Протезирование
На сегодняшний день не существует медицинских приборов, способных помочь восстановлению когнитивных функций, таких как способность направлять и поддерживать внимание, некоторых языковых функций и типов памяти, потерянных при вышеперечисленных заболеваниях. В будущем возможно создание нейрокогнитивных протезов (Neurocognitive prostheses), которые, как и нейромоторные протезы (Neuromotor prostheses), будут способны модулировать нейронные функции для того, чтобы физически восстановить когнитивные процессы, такие как исполнительные функции и язык.
В будущем возможно создание нейрокогнитивных протезов (Neurocognitive prostheses), которые, как и нейромоторные протезы (Neuromotor prostheses), будут способны модулировать нейронные функции для того, чтобы физически восстановить когнитивные процессы, такие как исполнительные функции и язык.
Лечение стволовыми клетками
В отдельных клинических случаях применение клеток пуповинной крови вызывало ответ у аутичных детей. В качестве терапии последствий аутизма специалисты предлагают комбинированное использование клеток пуповинной крови и мезенхимальных стволовых клеток.
Диета
Нетипичная реакция на продукты питания наблюдаются у ¾ детей с расстройствами аутистического спектра. Избирательность в еде является наиболее распространенной проблемой, что приводит к дополнительным нарушениям работы желудочно-кишечного тракта. В начале 1990-х, было высказано предположение, что аутизм может быть вызван или может усугубляться за счет наличия в пище опиоидных пептидов, таких как «casomorphine», которые являются продуктами метаболизма клейковины и казеина. На основании этой гипотезы, была разработана диета, которая исключает продукты, содержащие глютен или казеин или, или оба. Исследование, проведенное в 2008 г., показало, что, в сравнении со сверстниками, мальчики-аутисты, соблюдающие бесказеиновую диету, имеют более тонкие кости из-за недостатка витамина D.
На основании этой гипотезы, была разработана диета, которая исключает продукты, содержащие глютен или казеин или, или оба. Исследование, проведенное в 2008 г., показало, что, в сравнении со сверстниками, мальчики-аутисты, соблюдающие бесказеиновую диету, имеют более тонкие кости из-за недостатка витамина D.
Биологически активные добавки
Многие родители выбирают биологически активные добавки в качестве средства для лечения аутизма и облегчения симптомов заболевания.
Витамин С
Согласно исследованию, проведенному в 1993 г., применение витамина С способствует снижению интенсивности стереотипного поведения при аутизме. При этом отмечается, что аналогичных исследований впоследствии не проводилось, а также то, что высокие дозы витамина С могут способствовать образованию камней в почках и провоцировать желудочно-кишечные расстройства, в том числе диарею.
Мелатонин
Согласно опубликованной в 2007 г. исследовательской работе для лечения проблем со сном при нарушениях развития иногда используется мелатонин. Он является относительно безопасным и хорошо переносимым средством для лечения бессонницы у детей с расстройствами аутистического спектра. Однако отмечается, что при его применении на фоне таких побочных эффектов как сонливость, головная боль, головокружение и тошнота, встречаются и более острая реакция в виде учащения случаев припадков у некоторых детей.
Он является относительно безопасным и хорошо переносимым средством для лечения бессонницы у детей с расстройствами аутистического спектра. Однако отмечается, что при его применении на фоне таких побочных эффектов как сонливость, головная боль, головокружение и тошнота, встречаются и более острая реакция в виде учащения случаев припадков у некоторых детей.
Методики, направленные на инклюзию и интеграцию аутистов:
Сенсорная интеграция
Большинство людей учатся комбинировать свои чувства и ощущение собственного тела, чтобы получить представление об окружающем мире. Дети с аутизмом сталкиваются с проблемой обучения этим навыкам.
Терапия с помощью сенсорной интеграции основывается на предположении, что ребенок либо чересчур возбужден, либо недостаточно возбужден окружающей обстановкой. Таким образом, цель сенсорной интеграции — совершенствовать способность мозга обрабатывать сенсорную информацию, таким образом, что ребенок начинает лучше коммуницировать в повседневной жизни.
Примеры сенсорной интеграции:
— Раскачивание в гамаке (ориентация в пространстве)
— Танец под музыку (слуховая система)
— Игра с коробочками, наполненными фасолью (тактильные ощущения)
— Ползание в туннелях (прикосновение и ориентация в пространстве)
— Прикосновение к раскачивающимся шарикам (зрительно-тактильная координация)
— Вращение на стуле (баланс и зрение)
— Балансирование на перекладине (баланс)
TEACCH-программа:
Treatment and Education of Autistic and related Communication handicapped Children (TEACCH) — лечение и обучение детей, страдающих аутизмом и нарушениями общения (другой вариант названия — «Структурное обучение»). Программа предоставляет общественные сервисы для детей с аутизмом и сходными нарушениями, начиная с дошкольного возраста и до зрелости. Школьная программа предлагает индивидуальный курс обучения, ориентированный на развитие навыков, которые соответствуют возрасту ребенка, в четко структурированных условиях обучения. Главные области для развития навыков — общение, социализация, практические навыки, обучение независимости и подготовка к взрослой жизни. В основе методики — четкое структурирование пространства и времени через различные формы расписаний, т.е. через визуализацию.
Программа предоставляет общественные сервисы для детей с аутизмом и сходными нарушениями, начиная с дошкольного возраста и до зрелости. Школьная программа предлагает индивидуальный курс обучения, ориентированный на развитие навыков, которые соответствуют возрасту ребенка, в четко структурированных условиях обучения. Главные области для развития навыков — общение, социализация, практические навыки, обучение независимости и подготовка к взрослой жизни. В основе методики — четкое структурирование пространства и времени через различные формы расписаний, т.е. через визуализацию.
Необычные методики:
Массаж
Сеансы массажа часто используются в качестве дополнения к основному курсу терапии. Ключевым моментов в применении массажа является постепенное привыкание пациента к процедурам. В отдельных случаях массаж начинался с коротких сеансов по несколько секунд, и требовалось более полугода для того, чтобы пациент давал согласие на регулярные длительные процедуры. В результате регулярных сеансов массажа у пациентов постепенно проявлялась повышенная допустимость прикосновений, даже в том случае, если изначально реакция была крайне негативной.
В результате регулярных сеансов массажа у пациентов постепенно проявлялась повышенная допустимость прикосновений, даже в том случае, если изначально реакция была крайне негативной.
За все время не было написано ни одного серьезного научного исследования, доказывающего, что эффект сравним с другими видами лечения этой болезни
Гипноз
Гипноз как составляющая психотерапии наиболее эффективен для терапии позднего детского аутизма. При этом гипноз вполне совместим с методами интенсивной терапии и призван увеличить ее эффективность. Несомненным плюсом является возможность более тесного контакта с контролируемым, находящемся в трансе ребенком, чем при традиционных методах общения, когда пациент постоянно отводит взгляд, не отвечает на вопросы и полностью или частично игнорирует окружающих. Но эффективность применения гипноза для терапии врожденного аутизма подлежит дальнейшему изучению.
Музыкальная терапия
Терапия широко используется с середины XX в. Эксперты отмечают такие положительные результаты:
Эксперты отмечают такие положительные результаты:
— развитие коммуникативных навыков
— мотивация к взаимодействию
— развитие творческих навыков и потребности в самовыражении
— улучшение памяти и концентрации
Терапия начинается со знакомства пациента с инструментом. Инструктор все время находится на виду у больного, чтобы он ассоциировал необычные звуки с инструментом. Затем пациент пробует самостоятельно извлекать звуки или подражать им голосом. Лечение также может проходить в форме танца
Пет-терапия (лечение с помощью животных)
Терапия направлена на развитие коммуникативных навыков пациента. Доказано, что тесное взаимодействие с животными снижает частоту вспышек насилия у больных, а также избавляет от головных болей и бессонницы. Чаще всего пет-терапию проводят с собаками и лошадьми, однако встречаются случаи использования в лечении кошек и дельфинов. Практика лечения аутизма с помощью дельфинов не так распространена, но признана не менее эффективной. При общении с дельфином дети развивают концентрацию и коммуникативные способности.
При общении с дельфином дети развивают концентрацию и коммуникативные способности.
Материал подготовлен на основе информации из открытых источников
Методы коррекции профильной информации в процессе компиляции | Четверина
1. Chang P. P., Mahlke S. A., Hwu W. W. Using profile information to assist classic compiler code optimizations. Software Practice and Experience, V. 21, No12. -1991.-P. 1301-1321
2. W. Chen, R. Bringmann, S. Mahlke, S. Anik, T. Kiyohara, N. Warter, D. Lavery, W. -M. Hwu, R. Hank and J. Gyllenhaal., Using profile information to assist advanced compiler optimization and scheduling, 1993
3. Jan Hunicka, Profile driven optimisations in GCC, Proceedings of the GCC Developers’ Summit June 22nd-24th, 2005, Ottawa, Ontario Canada
4. Волконский В. Ю., Ермолицкий А. В., Ровинский Е. В. Развитие метода векторизации циклов при помощи оптимизирующего компилятора. Высокопроизводительные вычислительные системы и микропроцессоры: сборник трудов ИМВС РАН, Выпуск N8, 2005.
Волконский В. Ю., Ермолицкий А. В., Ровинский Е. В. Развитие метода векторизации циклов при помощи оптимизирующего компилятора. Высокопроизводительные вычислительные системы и микропроцессоры: сборник трудов ИМВС РАН, Выпуск N8, 2005.
5. Dmitry M Maslennikov, Vladimir Y Volkonsky: Compiler method and apparatus for elimination of redundant speculative computations from innermost loops. Elbrus International October 9, 2001: US06301706
6. Pengfei Yuan, Yao Guo , Xiangqun Chen, Experiences in profile-guided operating system kernel optimization, Proceedings of 5th Asia-Pacific Workshop on Systems, June 25-26, 2014, Beijing, China
7. Bo Wu, Mingzhou Zhou, Xipeng Shen, Yaoqing Gao, Raul Silvera, Graham Yiu, Simple profile rectifications go a long way, Proceedings of the 27th European conference on Object-Oriented Programming, July 01-05, 2013, Montpellier, France
8. Дроздов А.Ю., Степаненков А.М. Технология оптимизации цикловых участков процедур в компиляторах для архитектур с аппаратной поддержкой конвейризации циклов. Информационные технологии и вычислительные системы №3, М. 2004
Дроздов А.Ю., Степаненков А.М. Технология оптимизации цикловых участков процедур в компиляторах для архитектур с аппаратной поддержкой конвейризации циклов. Информационные технологии и вычислительные системы №3, М. 2004
9. Иванов Д.С. Распределение регистров при планировании инструкций для VLIW-архитектур. Программирование, № 6, 2010, С.74-80
10. Bo Wu, Zhijia Zhao, Xipeng Shen, Yunlian Jiang, Yaoqing Gao, Raul Silvera, Exploiting inter-sequence correlations for program behavior prediction, Proceedings of the ACM international conference on Object oriented programming systems languages and applications, October 19-26, 2012, Tucson, Arizona, USA [doi>10.1145/2384616.2384678]
11. Calin Cascaval , Luiz De Rose , David A. Padua , Daniel A. Reed, Compile-Time Based Performance Prediction, Proceedings of the 12th International Workshop on Languages and Compilers for Parallel Computing, p. 365-379, August 04-06, 1999
365-379, August 04-06, 1999
12. Jeremy Lau , Matthew Arnold , Michael Hind , Brad Calder, Online performance auditing: using hot optimizations without getting burned, Proceedings of the 2006 ACM SIGPLAN conference on Programming language design and implementation, June 11-14, 2006, Ottawa, Ontario, Canada
13. Ананий В. Левитин. Алгоритмы: введение в разработку и анализ — М.: «Вильямс», 2006.- С. 220-224. — ISBN 5-8459-0987-2
14. Steven S. Muchnick, Advanced Compiler Design & Implementation, 2003
15. Introduction to algorithms, Third Edition, Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein, 2009
16. Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman «Compilers: Principles, Techniques, and Tools» Book, Pearson Education, ISBN 0-321-48681-1, 2006
Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman «Compilers: Principles, Techniques, and Tools» Book, Pearson Education, ISBN 0-321-48681-1, 2006
Технологии лазерной коррекции зрения
First efficacy and safety study of femtosecond lenticule extraction for the correction of myopia: Six-month results
W.Sekundo, C. Russmann, A. Gille, W. Bissmann, G. Stobrawa, M. Sticker, M.Bischoff, M. Blum.
Journal of Cataract & Refractive Surgery
November 2008, Volume 34, Issue 11, Pages 18-19
Femtosekunden-Lentikel-Extraktion (FLEx)
M.Blum, W.Sekundo
Der Ophthalmologe
2010-08-08. — Bd. 107, H. 10. — S. 967–970. — DOI:10.1007/s00347-010-2222-8
Results of small incision lenticule extraction: All-in-one femtosecond laser refractive surgery
R.Shah, S.Shah, S.Sengupta
Journal of Cataract & Refractive Surgery
2011-01-01. — Т. 37, вып. 1. — С. 127–137. — DOI:10.1016/j.jcrs.2010.07.033
— Т. 37, вып. 1. — С. 127–137. — DOI:10.1016/j.jcrs.2010.07.033
Лазерная коррекция зрения: Фоторефракционная кератэктомия (ФРК), Ласик, Супер Ласик, Фемто Ласик, Лепто Ласик
www.vseoglazah.ru
Современные технологии коррекции зрения
tri-z.ru.
HIGH ADDS IN A NEW FORM
G.Jessen
Optometry & Vision Science
August 1969
Accuracy and Precision of LASIK Flap Thickness Using the IntraLase Femtosecond Laser in 1000 Consecutive Cases
G.Sutton, C.Hodge
Journal of Refractive Surgery
October 2008 — Volume 24 · Issue 8: 802-806
Refractive lenticule extraction (ReLEx flex) and wavefront-optimized Femto-LASIK: comparison of contrast sensitivity and high-order aberrations at 1 year
J.Gertnere, I.Solomatin, W.Sekundo
Graefe’s Archive for Clinical and Experimental Ophthalmology
2012-12-05. — Vol. 251, fasc. 5. — P. 1437–1442. — DOI:10.1007/s00417-012-2220-4
One-year refractive results, contrast sensitivity, high-order aberrations and complications after myopic small-incision lenticule extraction (ReLEx SMILE)
W. Sekundo, J.Gertnere, T.Bertelmann, I.Solomatin
Sekundo, J.Gertnere, T.Bertelmann, I.Solomatin
Graefe’s Archive for Clinical and Experimental Ophthalmology
2014-03-20. — Vol. 252, fasc. 5. — P. 837–843. — DOI:10.1007/s00417-014-2608-4
Усовершенствование технологии ReLEx SMILE: среднесрочные результаты, развитие технологии и перспективы применения
www.eyepress.ru
Ein-Jahres-Ergebnisse bei Small-Incision-Lentikel-Extraktion (SMILE) zur Myopiekorrektur
K. Kunert, J. Melle, W. Sekundo, J. Dawczynski, M. Blum
Klinische Monatsblätter für Augenheilkunde
2015-01-01. — Т. 232, вып. 01. — С. 67–71. — ISSN 0023-2165. — DOI:10.1055/s-0034-1383053
Small incision corneal refractive surgery using the small incision lenticule extraction (SMILE) procedure for the correction of myopia and myopic astigmatism: results of a 6 month prospective study
Walter Sekundo, Kathleen S. Kunert, Marcus Blum
British Journal of Ophthalmology
2011-03-01. — Vol. 95, fasc. 3. — P. 335–339. — ISSN 1468-2079. — DOI:10.1136/bjo.2009.174284
3. — P. 335–339. — ISSN 1468-2079. — DOI:10.1136/bjo.2009.174284
SMILE – новейшая малоинвазивная технология полностью фемтосекундной коррекции зрения. Результаты 6 месяцев наблюдения
www.eyepress.ru
ReLEx SMILE – третье поколение методов лазерной коррекции аномалий рефракции
www.eyepress.ru
Эволюция процедуры ReLEx SMILE
www.eyepress.ru
Past and present of corneal refractive surgery
Anders Højslet Vestergaard
Acta Ophthalmologica
2014-03-01. — Vol. 92. — P. 1–21. — ISSN 1755-3768. — DOI:10.1111/aos.12385
LASIK for Myopia Using the Zeiss VisuMax Femtosecond Laser and MEL 80 Excimer Laser
K.Kunert; M.Blum; A.Gille; W.Sekundo
Journal of Refractive Surgery
April 2009 — Volume 25 · Issue 4: 350-356
Comparison of the Visual Results After SMILE and Femtosecond Laser-Assisted LASIK for Myopia
Fangyu Lin, MD; Yesheng Xu, MD; Yabo Yang, PhD, MD
Journal of Refractive Surgery
April 2014 — Volume 30 · Issue 4: 248-254
Осложнения при поверхностной абляции — ФРК, LASEK, epi-LASIK
zrenue. com
com
Хирургическое лечение стромального помутнения роговицы методом LASIK
www.eyepress.ru
Лазерная коррекция зрения ReLEx SMILE
relexsmile.tilda.ws
Роль повреждения нервного аппарата роговицы в нарушении слезопродуцирующей функции после фоторефракционных операций
Румяецева, О. А., Кузнецова, Т. Е.
Казанский медицинский журнал
2002-01-01. — Т. 83, вып. 3. — ISSN 0368-4814
Коррекция некоторых интраоперационных осложнений при выполнении операции Фемто-Lasik
Костенёв, С. В.
Вестник новых медицинских технологий
2011-01-01. — Т. XVIII, вып. 4. — ISSN 1609-2163
Femtosecond laser FLEx surgery — first experience of application
search.proquest.com
Femtosecond technology of myopia correction
search.proquest.com
Лазерные воздействия на роговицу: современные тенденции и направления развития. Поиск новых решений
Онищенко Е. С, Альхави А.А., Новиков С.А., Кузнецова Н.Ю.
С, Альхави А.А., Новиков С.А., Кузнецова Н.Ю.
Офтальмологические ведомости
2010-01-01. — Т. 3, вып. 4. — ISSN 1998-7102
Risk factors and retreatment results of intraoperative flap complications in LASIK
Mitsutoshi Ito, Yoshiko Hori-Komai, Ikuko Toda, Kazuo Tsubota
Journal of Cataract & Refractive Surgery
2004-06-01. — Т. 30, вып. 6. — С. 1240–1247. — DOI:10.1016/j.jcrs.2003.10.018
Экстракция лентикулы через малый разрез — новая технология в рефракционной хирургии
Писаревская, О. В., Щуко, А. Г., Юрьева, Т. Н., Букина, В. В., Ивлева, Е. П.
Практическая медицина
2015-01-01. — Вып. 2-1 (87). — ISSN 2072-1757
Фемтосекундная экстракция лентикулы «SMILE». Первые клинические результаты и технические сложности на этапе освоения метод
www.eyepress.ru
Усовершенствование технологии ReLEx SMILE: среднесрочные результаты, развитие технологии и перспективы применения
www. eyepress.ru
eyepress.ru
Small Incision Corneal Refractive Surgery using the SMILE procedure for the Correction of Myopia and Myopic Astigmatism: Results of a 6 months prospective study
W.Sekundo, K.Kunert, M.Blum
British Journal of Ophthalmology
2010-07-01. — Т. 95, вып. 3. —С. 335. — DOI:10.1136/bjo.2009.174284
Mathematical Model to Compare the Relative Tensile Strength of the Cornea After PRK, LASIK, and Small Incision Lenticule Extraction
D.Z.Reinstein, T.J.Archer, J. B.Randleman
Journal of Refractive Surgery
July 2013 — Volume 29 · Issue 7: 454-460
Comparison of biomechanical effects of small-incision lenticule extraction and laser in situ keratomileusis: Finite-element analysis
A.S.Roy, W.Dupps, C.Roberts
Journal of Cataract & Refractive Surgery. — 2014-06-01. — Т. 40, вып. 6. — С. 971–980. —DOI:10.1016/j.jcrs.2013.08.065
Differences in the Corneal Biomechanical Changes After SMILE and LASIK
D. Wang, M.Liu, Y.Chen, X.Zhang, Y.Xu, J.Wang, C.To, Q.Liu
Wang, M.Liu, Y.Chen, X.Zhang, Y.Xu, J.Wang, C.To, Q.Liu
Journal of Refractive Surgery
October 2014 — Volume 30 · Issue 10: 702-707
ReLEx SMILE – третье поколение методов лазерной коррекции аномалий рефракции
Российская офтальмология онлайн № 16
Dry Eye After Small Incision Lenticule Extraction and LASIK for Myopia
Yesheng Xu, MD; Yabo Yang, MD, PhD
Journal of Refractive Surgery
March 2014 — Volume 30 · Issue 3: 186-190
Small incision lenticule extraction (SMILE) history, fundamentals of a new refractive surgery technique and clinical outcomes
Dan Z. Reinstein, Timothy J. Archer, Marine Gobbe
Eye and Vision
2014-01-01. — Т. 1. — С. 3. — ISSN 2326-0254. — DOI:10.1186/s40662-014-0003-1
Dry Eye Disease after Refractive Surgery: Comparative Outcomes of Small Incision Lenticule Extraction versus LASIK
www.sciencedirect.com
SMILE – новейшая малоинвазивная технология полностью фемтосекундной коррекции зрения. Результаты 6 месяцев наблюдения
Результаты 6 месяцев наблюдения
www.eyepress.ru
Качественная оценка результатов операций ReLEx (технология SMILE) на основе контрастной чувствительности
www.eyepress.ru
Рефракционные результаты SMILE
www.eyepress.ru
Результаты и осложнения технологии SMILE
www.eyepress.ru
Visual and Refractive Outcomes of Femtosecond Lenticule Extraction and Small-Incision Lenticule Extraction for Myopia
www.sciencedirect.com
Efficacy, safety, predictability, contrast sensitivity, and aberrations after femtosecond laser lenticule extraction
Anders H. Vestergaard, Jakob Grauslund, Anders R. Ivarsen, Jesper Ø. Hjortdal
Journal of Cataract & Refractive Surgery
2014-03-01. — Т. 40, вып. 3. — С. 403–411. —DOI:10.1016/j.jcrs.2013.07.053
Five-year results of refractive lenticule extraction
www.sciencedirect.com
Comparison of Visual and Refractive Outcomes Following Femtosecond Laser-Assisted LASIK With SMILE in Patients With Myopia or Myopic Astigmatism
Sri Ganesh, MS, DNB; Rishika Gupta, MS
Journal of Refractive Surgery
September 2014 — Volume 30 · Issue 9: 590-596
Five-year results of Small Incision Lenticule Extraction (ReLEx SMILE)
Marcus Blum, Kathrin Täubig, Christin Gruhn, Walter Sekundo, Kathleen S. Kunert
Kunert
British Journal of Ophthalmology
2016-01-08. — P. bjophthalmol–2015-306822. — ISSN 1468-2079. —DOI:10.1136/bjophthalmol-2015-306822
ESCRS | European Society of Cataract & Refractive Surgeons
www.escrs.org
Will SMILE Overtake LASIK?
CRSToday
Методика ReLEx SMILE – нежная форма лазерной коррекции зрения
EuroEyes.ru
FDA approves VisuMax Femtosecond Laser to surgically treat nearsightedness
www.fda.gov
ReLEx SMILE — Femtosecond Laser Solutions — Cornea & Refractive — Medical Technology | ZEISS International
| ZEISS International
| ZEISS International
| ZEISS International
| ZEISS International
www.zeiss.com
Технология ReLEx SMILE в рефракционной хирургии
www.eyepress.ru
Implications and Management of Suction Loss During Refractive Lenticule Extraction (ReLEx)
Ratnesh Sharma, MD; Pravin Krishna Vaddavalli, MD
Journal of Refractive Surgery
July 2013 — Volume 29 · Issue 7: 502-503
Safety and Complications of More Than 1500 Small-Incision Lenticule Extraction Procedures
A. Ivarsen, S.Asp, J. Hjortdal
Ivarsen, S.Asp, J. Hjortdal
Dry Eye Disease after Refractive Surgery: Comparative Outcomes of Small Incision Lenticule Extraction versus LASIK
A.Denoyer, E.Landman, L.Trinh, J.F.Faure, F.Auclin
Ophthalmology
2015-04-01. — Т. 122, вып. 4. — С. 669–676. —DOI:10.1016/j.ophtha.2014.10.004
Incidence and management of suction loss in refractive lenticule extraction
Chee Wai Wong, Cordelia Chan, Donald Tan, Jodhbir S. Mehta
Journal of Cataract & Refractive Surgery
2014-12-01. — Т. 40, вып. 12. — С. 2002–2010. — DOI:10.1016/j.jcrs.2014.04.031
Diffuse lamellar keratitis after small-incision lenticule extraction
Jing Zhao, Li He, Peijun Yao, Yang Shen, Zimei Zhou
Journal of Cataract & Refractive Surgery
2015-02-01. — Т. 41, вып. 2. — С. 400–407. — DOI:10.1016/j.jcrs.2014.05.041
Современные методики коррекции зубов | Стоматология Смаил-клиник в г. Казань
2018-02-04
В наше время придумано достаточно много новых современных способов для коррекции зубов. И все чаще и чаще эти процедуры становятся популярными. О некоторых поговорим и разберем на примерах.
Эстетическая коррекция зубов: «О проблемах и решениях»
Основные параметры, которые подвергаются корректировке, создание голливудской улыбки. Специалист даст рекомендации и примет решение вместе с пациентом.
О коррекции формы зубов
Одна из причин c которой пациент обращается к стоматологу – коррекция формы зубов. Иногда зубы имеют неэстетичную форму с рождения, а могут приобрести в течение жизни.
Специалисты часто сталкиваются с гиперплазией десны или с непропорциональным развитием зубов.
Форма зубов может быть нарушена по причинам:
- повышенная стираемость;
- в результате травмы.
Методов коррекций существует множество, они отличаются друг от друга только качеством и скоростью восстановления.
Капы и пластины чаще используют для детей, для взрослых они малоэффективны, носятся они определенное время, снимаются на время приема пищи.
Брекеты более современный способ выравнивания зубов. Выравниваются зубы за счет механического воздействия конструкции. Применять можно как для детей, так и для взрослых. Существуют некоторые типы брекетов (пластиковые, керамические, металлические, сапфировые).
Лингвальные брекеты, отличаются от привычных, крепятся брекеты на заднюю поверхность зубов, поэтому они совсем незаметны.
Коррекция цвета зубов: «О профессиональной чистке, отбеливании и винирах»
Специальные капы
Средство для домашнего отбеливания — капы, изготавливаются после консультации в клинике индивидуально (осветление эмали на 2-3 тона).
Ультрафиолетовое отбеливание зубов
Ультрафиолетовое отбеливание при использовании специальной световой установки (осветление эмали до 10 тонов).
Фотоотбеливание зубов
Вид аппаратного отбеливания — фотоотбеливание, когда врач вместо ультрафиолетового потока использует галогеновый (осветление эмали до 7-10 тонов).
Лазерное отбеливание
Лазерное отбеливание зубов — одна из современных процедур, в это время на эмаль воздействуют лазерным лучом (осветление эмали на 7-10 тонов).
Виниры
Сейчас виниры называют одним из популярных способов.
Виниры – пластинки из фарфора. Крепятся они на зубную эмаль специальным цементом, он имеет натуральный цвет. С помощью виниров можно изменить высоту зуба, улучшить цвет эмали и даже скрыть большие промежутки.
Даже если природа не одарила безупречной улыбкой, современные стоматологические методы коррекции помогут добиться великолепной улыбки.
3 СПОСОБЫ ИСПРАВЛЕНИЯ ОШИБОК
3 СПОСОБЫ ИСПРАВЛЕНИЯ ОШИБОК Далее: 4 ПРОВЕРКА ТЕХНИКИ Пред .: 2 ОБНАРУЖЕНИЕ ОШИБОККак только ошибка обнаружена, система может предпринять действия, чтобы исправьте его или попросите помощи у пользователя в исправлении (через какой-то интерфейса обработки ошибок). В качестве альтернативы система может поддерживать комплексная обработка ошибок. Например, интерактивный система украшения, показанная на рисунке 2А отображает альтернативы после каждого удара.Тот же интерфейс также поддерживает уведомление — если пользователь выбирает альтернативу, система может сделать вывод, что исходное значение по умолчанию было неправильным, и альтернативой является правильный.
Большинство поддерживаемых задач требует выбора одного правильная интерпретация пользовательского ввода (единственным исключением является поиск двигателей, которые могут иметь несколько правильных ответов). Один важный выбор, стоящий перед разработчиком методов обработки ошибок, — насколько активен система должна выбирать эту интерпретацию.По сути, дизайнер должен решить, принимать ли наиболее верный выбор, по умолчанию или дождаться подтверждения пользователя. Первая часть этого в разделе обсуждается, где каждый вариант был отражен в литературе, и почему. В оставшихся частях обсуждаются два обычно используемых метода для обработка ошибок, поощрение менее двусмысленного ввода и имитация естественные стратегии коррекции человека.
Количество ответов, возвращаемых подверженной ошибкам системой, часто бывает больше, чем количество ответов, ожидаемых пользователем.Это оставляет дизайнер интерфейса с возможностью выбора ни одного из ответы или выбор одного (или нескольких) ответов как « правильный » дефолт. Например, упомянутая выше система понимания чертежей по умолчанию выбирает одну строку (выделена жирным шрифтом Рисунок 2A) (Игараши и др., 1997). В разработчик интерфейса должен использовать информацию о вероятности правильность и накладные расходы на исправление ошибочного выбора default, чтобы решить, когда следует выбрать значение по умолчанию. в в случае системы понимания чертежей интерфейс спроектирован так что пользователь не выполняет больше работы, когда система выбирает значение по умолчанию, чем когда это не так.И если система сделает правильный выбор, пользователь выполняет меньше работы (поскольку ему не нужно выбирать его самостоятельно прежде, чем они продолжат рисовать).
Примером системы, которая по умолчанию ничего не выбирает, является Rhodes & Starner’s (1996) агент памяти . Агент памяти извлекает документы на основе их соответствия текущему тексту в редактор. Вместо того, чтобы сразу отображать наиболее релевантный документ, у него есть маленькое постоянное окошко, где показано по одной строке от каждого из трех потенциально интересных документов.Собственно выбирая документ и его отображение было бы гораздо более инвазивным, трудным для правильно, и часто не то, что хочет пользователь. Даже если в системе найдены соответствующие документы, пользователь может не захотеть, чтобы его отвлекали чтобы их прочитать.
Системы предсказания слов также демонстрируют, почему дизайнер может выбрать не выбирать значение по умолчанию. Если, например, система принимает верхнюю предсказание верное, он вставит его. Но предсказание слова — это особенно сложная задача, в которой часто выбирают неправильный.И пользователю, скорее всего, потребуется больше нажатий клавиш, чтобы удалите ошибку и продолжите ввод, чем если бы просто напечатал все слово в первую очередь, особенно если похожие ошибки происходят автоматически после ввода каждого символа.
Даже если для пользователя уместно выбрать значение по умолчанию, это выбор может быть неправильным, и из-за этого пользовательский интерфейс должен поддержка исправления ошибок. Один из способов поддержать это — отобразить альтернативы, из которых пользователь может сделать правильный выбор.Другой подход заключается в ненавязчивом предоставлении способов изменить значение по умолчанию без обязательного отображения альтернатив. Например, Голдберг и Гудисман (1991) предлагают использовать простой жест ( нажмите), чтобы выбрать следующий вариант. В качестве другого примера рассмотрим систему Tivoli , в которой некоторые вводимые данные интерпретируются как жесты, а другие — просто как рукописные вводы. нарисовано на экране (Moran et al., 1997). Если пользователь рисует жест который может вызвать действие, такое как « переместить », система по умолчанию предполагает, что действие предназначено (а не просто рисование на экране).Однако, если пользователь не выполняет (выбрав объект для двигаться в этом случае), Moran et al. автоматически отменить его, заменив его вместо этого с его альтернативной интерпретацией как простые чернила.
Известно, что одни режимы ввода менее подвержены ошибкам, чем другие. (сравните набор текста с распознаванием рукописного ввода), и бывают случаи, когда этот факт уместно использовать. Например, Сухм нашел что точность распознавания на самом деле снижает на 10-65% во время такого рода исправление ошибок в системе распознавания речи (Сухм, 1997).Один из вариантов — компьютер предлагать меньше неоднозначный метод ввода в качестве альтернативы. Эта техника была эффективно используется в Apple MessagePad, а также для речи ввод (Marx & Schmandt, 1994), ввод пером (Goldberg & Goodisman, 1991), и их смесь (Suhm et al., 1996b).
В качестве альтернативы разработчик интерфейса может поощрять меньшее ошибочный ввод с самого начала. Например, дизайнеры PalmPilot решил использовать алфавит unistroke (Голдберг и Ричардсон, 1993).Легче распознать однорядные удары чем распознавать почерк, потому что нет возможности ошибки сегментации, поскольку каждая буква — это ровно один штрих (перо до перо вниз). В другом примере Goldberg & Goodisman (1991) Предлагаем использовать метки (квадраты) на экране, чтобы уменьшить ошибки сегментации и не поощряйте скорописный почерк.
Некоторые исследователи использовали склонность человека имитировать вывод того, что они сообщают с. Золтан-Форд (1991) обнаружил, что люди будут подражать структуры предложений в ответах компьютера, что помогает сделать обработку естественного языка Полегче.Kurtenbach et al. (1994) исследовали использование детской кроватки листы, отображающие жесты для копирования пользователем. Пользователь может запросить анимацию команды, щелкнув ее изображение на детская кроватка. Также было обнаружено, что простыни для детской кроватки успешно улучшают распознавание в системе распознавания символов (Wolf, 1990).
Хотя компьютеры являются основным источником ошибок, люди также делают ошибки. Как опыт, так и исследования показали, что у людей уже есть способы исправлять ошибки.Они могут зачеркнуть букву или добавить другую букву или слово к тому, что они только что написал. Когда они говорят неправильно, они могут сделать паузу или повторить правильное слово; с или без добавления неречевых звуковых сигналов, чтобы указать ошибка. Это то, что мы называем «естественными» стратегиями коррекции.
Эти « исправления » настолько естественны, что пользователи могут их даже хотя большинство распознавателей не знают, как интерпретировать исправления. Huerst et al. (1998) экспериментировали с препроцессором рукописного ввода. который ищет и применяет эти исправления перед отправкой почерк до распознавателя.По сути, то, что делает пользователь в этой стратегии, исправляет их исходный ввод в исходной форме, возможно, даже в середине входа в него. Это делается почерком, речью и т. Д. типы ввода. Например, мы поддерживаем эту стратегию в нашем единомышленнике. клавиатура (Mankoff & Abowd, 1998). BrennanHulteen: 95 работ в области прикладных лингвистических исследований к дизайну интерфейса (описано выше в разделе об ошибках Discovery) также демонстрируют полезность имитации людей. Один человеческая стратегия, которую они не копируют, — это пауза.Тем не менее вопросы о том, когда и как долго делать паузу, были исследованы несколько исследователей (Ареф и др., 1995; Като и Накагава, 1995; Лопрести и Томкинс, 1995; Куртенбах и др., 1994).
Например, Kurtenbach et al. (1994) используйте паузу, чтобы Пользователь запрашивает указания при рисовании жеста. Каждый жест на самом деле выбор из кругового меню, которое отображается только в том случае, если пользовательские паузы (эти наборы жестов называются меню маркировки). Пауза также может использоваться для поддержки отложенных или ленивых признание.Schomaker (1994) предлагает повторить ввод в случай « невидимых » команд, таких как жесты. Система могла затем укажите момент, когда пользователь может отменить команду прежде, чем он станет постоянным.
Далее: 4 ПРОВЕРКА ТЕХНИКИ Пред .: 2 ОБНАРУЖЕНИЕ ОШИБОК
Джен Манкофф
Ср, 10 февраля, 14:45:55 EST 1999
Произошла ошибка при настройке вашего пользовательского файла cookie
Произошла ошибка при настройке вашего пользовательского файла cookieЭтот сайт использует файлы cookie для повышения производительности.Если ваш браузер не принимает файлы cookie, вы не можете просматривать этот сайт.
Настройка вашего браузера для приема файлов cookie
Существует множество причин, по которым cookie не может быть установлен правильно. Ниже приведены наиболее частые причины:
- В вашем браузере отключены файлы cookie. Вам необходимо сбросить настройки своего браузера, чтобы он принимал файлы cookie, или чтобы спросить вас, хотите ли вы принимать файлы cookie.
- Ваш браузер спрашивает вас, хотите ли вы принимать файлы cookie, и вы отказались.Чтобы принять файлы cookie с этого сайта, нажмите кнопку «Назад» и примите файлы cookie.
- Ваш браузер не поддерживает файлы cookie. Если вы подозреваете это, попробуйте другой браузер.
- Дата на вашем компьютере в прошлом. Если часы вашего компьютера показывают дату до 1 января 1970 г., браузер автоматически забудет файл cookie. Чтобы исправить это, установите правильное время и дату на своем компьютере.
- Вы установили приложение, которое отслеживает или блокирует установку файлов cookie.Вы должны отключить приложение при входе в систему или проконсультироваться с системным администратором.
Почему этому сайту требуются файлы cookie?
Этот сайт использует файлы cookie для повышения производительности, запоминая, что вы вошли в систему, когда переходите со страницы на страницу. Чтобы предоставить доступ без файлов cookie потребует, чтобы сайт создавал новый сеанс для каждой посещаемой страницы, что замедляет работу системы до неприемлемого уровня.
Что сохраняется в файле cookie?
Этот сайт не хранит ничего, кроме автоматически сгенерированного идентификатора сеанса в cookie; никакая другая информация не фиксируется.
Как правило, в файле cookie может храниться только информация, которую вы предоставляете, или выбор, который вы делаете при посещении веб-сайта. Например, сайт не может определить ваше имя электронной почты, пока вы не введете его. Разрешение веб-сайту создавать файлы cookie не дает этому или любому другому сайту доступа к остальной части вашего компьютера, и только сайт, который создал файл cookie, может его прочитать.
Сплайновые методы отложенной коррекции для обыкновенных дифференциальных уравнений
АннотацияМы представляем новый вариант отложенной коррекции интеграла Пикара, класс методов, направленных на решение задач начального значения с произвольно высоким порядком точности, называемых отложенной коррекцией сплайном (SplineDC). Подобно спектральной отложенной коррекции (SpectralDC), SplineDC применяет серию корректирующих разверток, полученных из интегральной формы Пикара, которые управляются либо явными, либо неявными схемами интегрирования Эйлера первого порядка для получения высокоточного численного решения.Однако, как следует из названия, SplineDC использует сплайн-интерполяцию в отличие от интерполяции Лагранжа в случае SpectralDC. Эта идея мотивирована нашим интересом обойти внутренние ограничения методов SpectralDC, которые применяются для предотвращения нестабильности, связанной с полиномиальной интерполяцией высокого порядка и / или с равным интервалом, то есть феномена Рунге. При этом мы разрабатываем класс методов с благоприятным поведением сходимости и отличными свойствами устойчивости, которые мы демонстрируем с помощью различных численных экспериментов.Кроме того, из-за свободы, которую SplineDC имеет в отношении выбора временного шага, мы демонстрируем преимущества реализации адаптивного временного шага в SplineDC над SpectralDC. Наконец, мы представляем альтернативный метод построения сплайнов, который упрощает построение сплайнов с произвольными условиями непрерывности и интерполяции.
Основное содержаниеЗагрузить PDF для просмотраПросмотреть больше
Дополнительная информация Меньше информации
Закрывать
Введите пароль, чтобы открыть этот PDF-файл:
Отмена Ok
Подготовка документа к печати…
Отмена
вариантов коррекции зрения | Хирургический центр офтальмологической клиники | Биллингс
Коррекция проблем с рефракционным зрением, таких как миопия (близорукость), дальнозоркость (дальнозоркость), астигматизм и пресбиопия (трудности с чтением мелкого шрифта), вышла за рамки простых очков и контактных линз.Сегодня пациенты могут рассмотреть несколько методов коррекции зрения. В Billings наши врачи могут помочь вам разобраться в ваших возможностях и выбрать лучшее решение для коррекции зрения в соответствии с вашими индивидуальными потребностями. Ниже приведены распространенные методы коррекции зрения:
Очки: Ношение очков — простой способ исправить ошибки рефракции. Улучшение зрения с помощью очков дает возможность выбирать из различных типов линз, дизайнов оправ и даже покрытий линз для различных стилей жизни, занятий и занятий.
Контактные линзы: Контактные линзы — популярная альтернатива очкам. Мягкие контактные линзы предлагают множество удобных вариантов, включая цветные версии, бифокальные линзы и линзы ежедневного использования. Контактные линзы пролонгированного ношения можно носить до 30 дней подряд без ухода.
LASIK: LASIK — самая популярная форма рефракционной хирургии, но сейчас есть несколько других альтернатив, таких как PRK, LASEK и Epi-LASIK. Хирургический центр офтальмологической клиники использует новейшие лазерные технологии и опыт, чтобы адаптировать вашу процедуру к вашим уникальным потребностям в области зрения.
Замена естественной линзы: Эта процедура, также известная как замена рефракционной линзы или извлечение прозрачной линзы, включает удаление естественного хрусталика в глазу и замену его искусственным хрусталиком, также называемым интраокулярной линзой (ИОЛ). Это позволяет нашим врачам предоставить вам новые линзы с улучшенной фокусирующей способностью, что снижает потребность в очках или контактных линзах.
Имплантат факичной линзы: В этой процедуре имплантированная линза располагается поверх естественного хрусталика.Он работает, увеличивая силу фокусировки естественного хрусталика, не заменяя его. Эта процедура может быть полезной для пациентов с сильной близорукостью.
Чтобы узнать больше о методах коррекции зрения, которые мы обсуждали, а также о других вариантах, свяжитесь с Хирургическим центром офтальмологической клиники по телефону 406-252-6608 или на веб-сайте.
Простой и эффективный метод радиометрической коррекции для улучшения обнаружения изменений ландшафта по датчикам и во времени
Спутниковые данные предлагают непревзойденную полезность для мониторинга и количественной оценки крупномасштабных изменений земного покрова с течением времени.Однако радиометрическую согласованность между совмещенными разновременными изображениями трудно поддерживать из-за различий в характеристиках датчика, атмосферных условиях, солнечном угле и углу обзора датчика, которые могут затруднить обнаружение изменений поверхности. Чтобы обнаружить точное изменение ландшафта с помощью разновременных изображений, мы разработали вариант схемы нормализации псевдоинвариантных признаков (PIF): метод временно инвариантных кластеров (TIC). Данные изображений были получены 9 июня 1990 г. (Landsat 4), 20 июня 2000 г. (Landsat 7) и 26 августа 2001 г. (Landsat 7) для анализа бореальных лесов вблизи сибирского города Красноярска с использованием нормированного разностного индекса растительности (NDVI). ), улучшенный вегетационный индекс (EVI) и уменьшенный простой коэффициент (RSR).Центры временно инвариантных кластеров (TIC) были идентифицированы с помощью карты плотности точек совместно размещенных пиксельных VI из базового изображения и целевого изображения, и была создана линия регрессии нормализации для пересечения всех центров TIC. Затем значения VI целевого изображения были пересчитаны с использованием функции регрессии, чтобы эти два изображения можно было сравнить, используя полученную общую радиометрическую шкалу. Мы обнаружили, что EVI очень хорошо показывает структуру растительности из-за его чувствительности к эффектам затенения и, таким образом, может использоваться для отделения хвойных лесов от лиственных лесов и травяных / сельскохозяйственных угодий.И наоборот, поскольку NDVI уменьшал радиометрическое влияние тени, он не позволял проводить различия между этими типами растительности. После нормализации корреляции NDVI и EVI с полевыми измерениями индекса площади листвы (LAI), объединенные за 2000 и 2001 годы, были значительно улучшены; значения r 2 в этих регрессиях выросли с 0,49 до 0,69 и с 0,46 до 0,61 соответственно. «Эффект отмены» EVI, когда EVI был положительно связан с озеленением подлеска, но отрицательно связан с покрытием лесного полога, был очевиден в хронопоследовательности после пожара с нормализованными данными.Эти результаты показывают, что метод TIC обеспечивает простой, эффективный и повторяемый метод создания радиометрически сопоставимых наборов данных для удаленного обнаружения изменений ландшафта. По сравнению с некоторыми предыдущими методами относительной радиометрической нормализации, этот новый метод не требует высокого уровня программирования и статистических навыков, но остается чувствительным к изменениям ландшафта, происходящим в сезонных и межгодовых временных масштабах. Кроме того, метод TIC сохраняет чувствительность к незначительным изменениям фенологии растительности и обеспечивает нормализацию, даже если инвариантные признаки редки.Хотя этот метод нормализации позволил выявить ряд изменений в землепользовании, растительном покрове и фенологических / биофизических изменениях в исследуемом здесь сибирском бореальном лесном регионе, необходимо дополнительно изучить изображения, представляющие широкий спектр экорегионов, чтобы тщательно оценить метод TIC в сравнении с другие схемы нормализации. ?? 2005 Elsevier Inc. Все права защищены.
Методы корректировки вывода на основе результатов, предсказанных машинным обучением
Значимость
Машинное обучение теперь используется во всем научном предприятии.Исследователи обычно используют прогнозы из случайных лесов или глубоких нейронных сетей в последующем статистическом анализе, как если бы они были данными наблюдений. Мы показываем, что этот подход может привести к чрезмерной систематической ошибке и неконтролируемой дисперсии последующих статистических моделей. Мы предлагаем статистическую корректировку для исправления предвзятого вывода в регрессионных моделях с использованием прогнозируемых результатов независимо от модели машинного обучения, используемой для этих прогнозов.
Abstract
Многие современные проблемы медицины и общественного здравоохранения используют методы машинного обучения для прогнозирования результатов на основе наблюдаемых ковариат.В самых разных условиях прогнозируемые результаты используются в последующем статистическом анализе, часто без учета различия между наблюдаемыми и прогнозируемыми результатами. Мы называем вывод предсказанным выводом постпредсказания. В этой статье мы разрабатываем методы исправления статистических выводов с использованием результатов, предсказанных с помощью произвольно сложных моделей машинного обучения, включая случайные леса и глубокие нейронные сети. Вместо того, чтобы пытаться получить поправку из первых принципов для каждого алгоритма машинного обучения, мы наблюдаем, что обычно существует низкоразмерное и легко моделируемое представление взаимосвязи между наблюдаемыми и прогнозируемыми результатами.Мы создаем подход для вывода постпрогнозирования, который естественным образом вписывается в стандартную структуру машинного обучения, где данные делятся на наборы для обучения, тестирования и проверки. Мы обучаем модель прогнозирования в обучающем наборе, оцениваем взаимосвязь между наблюдаемыми и прогнозируемыми результатами в тестовом наборе и используем эту взаимосвязь для исправления последующего вывода в проверочном наборе. Мы показываем, что наш подход постпредсказательного вывода (postpi) может исправить смещение и улучшить оценку дисперсии и последующий статистический вывод с предсказанными результатами.Чтобы показать широкий диапазон применимости нашего подхода, мы показываем, что postpi может улучшить вывод в двух разных областях: моделирование предсказанных фенотипов в данных по измененной экспрессии генов и моделирование предсказанных причин смерти в данных вербального вскрытия. Наш метод доступен через пакет R с открытым исходным кодом: https://github.com/leekgroup/postpi.
За последнее десятилетие произошел взрывной рост как данных, доступных для точного здравоохранения (1⇓ – 3), так и одновременно таких удобных инструментов, как пакет Caret (4) и Scikit-learn (5), которые усложняют реализацию Статистические методы и методы машинного обучения доступны для все более широкого круга ученых.Например, машинное обучение на основе электронных медицинских карт используется для прогнозирования фенотипов (6, 7), геномные данные используются для прогнозирования результатов для здоровья (8), а данные опросов используются для прогнозирования причины смерти в условиях, когда смерть происходит за пределами больницы (9, 10). Повышенное внимание к таким идеям, как точная медицина, означает, что роль машинного обучения в медицине и общественном здравоохранении будет только возрастать (11). Поскольку машинное обучение играет все более важную роль в научных дисциплинах, крайне важно учитывать все источники потенциальной изменчивости последующих выводов, чтобы обеспечить стабильные статистические результаты (12, 13).
Во многих случаях исследователи не наблюдают за результатами напрямую, поэтому наблюдаемые результаты часто заменяются прогнозируемыми результатами моделей машинного обучения в последующих анализах (6, 14–18). Одним из примеров из генетики являются исследования ассоциации между генетическими вариантами и болезнью Альцгеймера у молодых людей. Поскольку у молодых людей не развилась болезнь Альцгеймера, трудно связать фенотип с генетическими вариантами. Однако старших родственников этих взрослых можно использовать для прогнозирования окончательного фенотипа участников исследования, используя известные образцы наследования заболевания.Прогнозируемый результат можно использовать вместо наблюдаемого статуса болезни Альцгеймера при проведении полногеномного исследования ассоциации (15).
Это всего лишь один пример феномена вывода постпредсказания (postpi). Хотя этот подход является распространенным, он создает множество статистических проблем. Прогнозируемые результаты могут быть смещенными, или прогнозируемые результаты могут иметь меньшую изменчивость, чем фактические. Стандартной практикой во многих приложениях является трактовка предсказанных результатов так, как если бы они наблюдались в последующих регрессионных моделях (6, 14–18).Как мы покажем, нескорректированный вывод постпрогнозирования часто будет иметь дефлированные стандартные ошибки, систематическую ошибку и завышенную частоту ложных срабатываний.
Вывод постпрогнозирования появляется во всех полях и был признан потенциальным источником ошибок в недавней работе по оценке распространенности (см., Например, ссылки 19 и 20 в контексте сдвига набора данных и ссылку 21 в оценке распространенности классов документов). Здесь мы сосредоточены на разработке аналитических и основанных на бутстрапе подходов для исправления оценок регрессии, SE и статистики тестов в моделях выводимой регрессии с использованием прогнозируемых результатов.Мы исследуем параметры, в которых прогнозируемый результат становится зависимой переменной в последующем выводном регрессионном анализе. Мы выводим аналитическую поправку в случае линейной регрессии и поправки на основе начальной загрузки для более общих регрессионных моделей, уделяя особое внимание линейной и логистической регрессии, поскольку они являются наиболее распространенными моделями вывода. Однако наш подход, основанный на начальной загрузке, можно легко распространить на любую обобщенную модель вывода линейной регрессии.
И наши аналитические исправления, и исправления на основе начальной загрузки используют стандартную структуру для задач машинного обучения.Мы предполагаем, что у нас есть по крайней мере три отдельных подвыборки, которые мы здесь обозначаем как обучающий набор, набор для тестирования и набор для проверки (рис. 1). Мы предполагаем, что распределение генерирующих данных для трех наборов данных одинаково, а наборы для обучения и тестирования завершены — мы наблюдаем как интересующий результат (y), так и ковариаты (x). В наборе проверки мы предполагаем, что наблюдаются только ковариаты. Набор для проверки может представлять собой либо подмножество проверки из одной выборки, либо будущий проспективно собранный набор данных, в котором мы хотим выполнить вывод, но собрать результат слишком дорого или сложно.
Рис. 1.Диаграмма разделения данных. Общая структура нашего подхода состоит в том, чтобы разделить наблюдаемые данные на наборы для обучения, тестирования и проверки. Обучающий набор используется для обучения модели прогнозирования, набор для тестирования используется для оценки взаимосвязи между наблюдаемыми и прогнозируемыми результатами, а набор для проверки предназначен для подгонки нижестоящей модели вывода, где модель взаимосвязи используется для корректировки вывода в последующих статистических данных. (x)) генерируется в обучающем наборе и применяется в наборах для тестирования и проверки.В наборе проверки наша цель состоит в том, чтобы выполнить вывод на регрессионной модели формы g (E [y | X]) = Xβ. Однако в наборе проверки наблюдаются только ковариаты, поэтому вместо этого мы должны подобрать g (E [yp | X]) = Xβp. Наша цель — восстановить вывод, который мы получили бы, если бы наблюдали истинные результаты y в проверочном наборе. Чтобы исправить вывод с использованием предсказанных результатов, мы используем набор данных тестирования, в котором есть как предсказанные (yp), так и наблюдаемые (y) результаты. Мы получаем поправку для вывода, используя yp на основе отношения между y и yp.
Преимущество этого подхода в том, что он не зависит от конкретной модели машинного обучения. То есть нам не нужно заранее знать ожидаемые рабочие характеристики вне выборки для данного метода. Вместо этого мы предполагаем, что взаимосвязь между прогнозируемыми и наблюдаемыми результатами в наборе тестирования хорошо характеризует те же отношения в наборе проверки.
Описываемая нами настройка имеет параллели с множественным вменением (22) для отсутствующих данных, но имеет несколько отличительных особенностей.Любая проблема прогнозирования может быть представлена как проблема с отсутствующими данными, когда отсутствуют все значения, и не существует механизма отсутствия различий между наблюдаемыми и ненаблюдаемыми результатами. Причина в том, что в наборе валидации или последующих анализах практических задач нет данных о наблюдаемых результатах. Множественное вменение также часто основывается на генеративной модели для имитации данных. Однако в наших условиях мы хотим создать фреймворк, который можно использовать для любой модели машинного обучения, независимо от ее рабочих характеристик.Следовательно, нам нужна методология, которая может использовать алгоритм машинного обучения черного ящика, но построить простую модель для взаимосвязи между прогнозируемыми и наблюдаемыми данными результатов. Эта проблема также связана с идеей ошибок в переменных (23) или моделями ошибок измерения (24), где либо результат, либо ковариаты измеряются с ошибкой. Однако в задачах прогнозирования мы больше не можем предполагать, что ошибки не зависят от прогнозируемых значений, поскольку прогнозы машинного обучения могут быть более точными для подмножеств значений y.
Помимо использования в медицине и здравоохранении, предлагаемый нами метод также широко применим в социальных науках. В политологии, например, исследователи используют инструменты машинного обучения для классификации настроений или политической идентификации в сегментах текста, а затем подбирают регрессионные модели для выявления особенностей текста, склоняющегося к той или иной стороне (25). В социологии исследователи используют инструменты машинного обучения для определения расы глав домохозяйств, подлежащих выселению, а затем используют регрессионные модели, чтобы понять неоднородность обстоятельств, связанных с выселением лиц определенной расы (26).
Здесь мы применяем наш постпи-подход к двум открытым проблемам: моделирование взаимосвязи между уровнями экспрессии генов и типами тканей (8) и понимание тенденций в (прогнозируемой) причине смерти (27, 28). Мы показываем, что наш метод может уменьшить систематическую ошибку, соответствующим образом моделировать изменчивость и исправить проверку гипотез в случае, когда наблюдаются только предсказанные результаты. Мы также обсуждаем чувствительность нашего подхода к изменениям в исследуемой популяции, которые могут привести к нарушению предположений нашего подхода.Наш подход postpi доступен в виде пакета R с открытым исходным кодом, доступного на GitHub: https://github.com/leekgroup/postpi.
Иллюстративный пример
Мы начинаем с иллюстративного смоделированного примера, чтобы выделить проблемы, которые могут возникнуть при неисправленном выводе постпрогнозирования. Методы, которые мы представляем в следующих разделах, охватывают более широкий диапазон настроек и не требуют допущений о распределении, которые мы делаем здесь для описания. Здесь мы моделируем наблюдения для результата yi и коварифицируем xij для i = 1,…, n, j = 1,…, p.Мы используем xi для обозначения вектора [xi1,…, xip]. В нашем моделировании мы генерируем данные в соответствии со следующей истинной зависимостью между y и x, которую мы обозначаем через f (⋅): yi = f (xi) + eui. [1] Эта модель представляет истинное базовое распределение, генерирующее данные, которое неизвестно в реальных настройках анализа.
Линейные или обобщенные линейные модели являются обычным подходом к выполнению логического вывода, даже если процесс создания данных неизвестен. Мы используем Xi для обозначения матрицы плана. Например, нас может заинтересовать подгонка моделей вида yi = Xiβ + eii.p на основе подгонки модели с использованием ypi в качестве результата, так что E (ypi | Xi) = Xiβp. Уравнение 4 не отражает должным образом нашу неопределенность в отношении результата, что приводит к смещению оценок, слишком малым SE и антиконсервативно смещенным значениям P и ложноположительным результатам.
На рис. 2 показаны результаты нашего смоделированного примера. Мы моделируем ковариаты xi1, xi2, xi3 и xi4 и члены ошибок eui из нормальных распределений и моделируем наблюдаемый результат yi, используя простую модель регрессии в качестве естественного состояния, f (⋅).(xi). Затем мы оцениваем взаимосвязь между прогнозируемыми и наблюдаемыми результатами. В наборе проверки мы подбираем модель линейной регрессии в качестве модели вывода.
Рис. 2.Имитационный пример. Данные были смоделированы из наземной модели в виде линейной модели. ( A ) Наблюдаемые результаты в сравнении с интересующей переменной. Ось x показывает интересующую ковариату x1, а ось y показывает наблюдаемые результаты y. ( B ) Прогнозируемые результаты в сравнении с интересующей ковариатой.Ось x показывает интересующую ковариату x1, а ось y показывает прогнозируемые результаты yp. ( C ) Наблюдаемые результаты по сравнению с прогнозируемыми. Ось x показывает наблюдаемые результаты y, а ось y показывает прогнозируемые результаты yp.
Это моделирование предназначено для выявления проблем, возникающих при выводе постпрогнозирования в условиях, когда доступны как yi, так и ypi. При фактическом анализе данных с прогнозируемыми результатами мы не наблюдали бы истинного yi в проверочном наборе, и все выводы выполнялись бы с ypi.
На рис. 2 A мы проиллюстрировали истинную взаимосвязь между смоделированными y и x1 (синий цвет). На рис. 2 B мы показываем прогнозируемые значения yp в зависимости от x1 (красный цвет). На рис. 2 B соотношение изменилось с другим наклоном и отклонением. На рис. 2 C мы показываем взаимосвязь между наблюдаемыми и прогнозируемыми результатами. В этом смоделированном примере мы знаем, что оценочный коэффициент связи между наблюдаемым результатом y и x равен 3.87 с SE 0,14. Однако, когда мы подбираем модель с использованием прогнозируемого результата yp, мы получаем оценку 3,7 с SE 0,068. Этот простой смоделированный пример показывает, что выводы, сделанные на основе прогнозируемых результатов, могут иметь 1) смещенные оценки, 2) слишком маленькие SE и, следовательно, 3) значения P и выводы, которые являются антиконсервативно смещенными.
Для корректировки ошибок в прогнозах одним из вариантов может быть получение поправок смещения и SE для конкретного метода машинного обучения. Этот подход позволит использовать знания о том, как работает конкретный инструмент прогнозирования.Чтобы вычислить смещение и SE аналитически, нам обоим необходимо: 1) знать, какая модель машинного обучения использовалась, и 2) иметь возможность теоретически охарактеризовать свойства прогнозов этой модели машинного обучения. Такой подход ограничивает аналитика только подходами к машинному обучению, чьи выводимые рабочие характеристики были получены. Рис. 2 C предлагает альтернативный подход. В этом случае связь между наблюдаемым и прогнозируемым результатом можно легко смоделировать с помощью линейной регрессии.Мы покажем, что это наблюдение справедливо для множества методов машинного обучения.
Ключевая идея нашего подхода заключается в том, что мы используем взаимосвязь между прогнозируемыми и наблюдаемыми данными в тестовом наборе, чтобы оценить систематическую ошибку и дисперсию, вносимую путем использования прогнозируемого результата в качестве зависимой переменной в нижестоящей модели выводимой регрессии в проверочном наборе. . Этот подход не требует особой информации о каждом подходе к машинному обучению и, вместо этого, предполагает, что относительно простая модель фиксирует взаимосвязь между прогнозируемыми и наблюдаемыми результатами.
Метод
Обзор нашего подхода.
Наша цель — разработать метод корректировки вывода для параметров в модели выводимой регрессии, в которой прогнозируемые результаты рассматриваются как наблюдаемые.
Мы делаем следующие предположения о структуре данных и модели. Мы предполагаем, что данные генерируются из неизвестной модели генерации данных вида g [E (yi | xi1, xi2,…, xip)] = f (xi1, xi2,…, xip). [5] Эта модель представляет собой «Истинное состояние природы», но напрямую не наблюдается ни в одной практической задаче.(⋅) (см. SI Приложение , раздел 2C для дальнейшего обсуждения этого предположения).
На практике истинный процесс генерации данных известен редко. Обычной статистической практикой является подгонка линейных или обобщенных линейных моделей для связи результатов с ковариатами для вывода (6, 14, – 18). Если обозначить Xi интересующую ковариату в матричной записи, тогда типичная модель регрессии может иметь вид gE (yi | Xi) = Xiβ. [6] Когда результат наблюдается, мы можем напрямую вычислить оценку β.Однако здесь мы рассматриваем случай, когда будет невозможно наблюдать результат в будущих наборах данных из-за затрат или неудобств, поэтому прогнозируемый результат ypi будет использоваться в уравнении. 6 .
Самый прямой подход к выполнению вывода постпрогнозирования — использовать предсказанные результаты и игнорировать тот факт, что они предсказаны. Однако этот подход может привести к смещению оценок, небольшим SE, статистике антиконсервативных тестов и ложным срабатываниям для оцененных коэффициентов, как мы видели в простом примере в иллюстративном примере .Мы продемонстрируем, что этот подход приводит к неизменно неточным выводам при моделировании и реальных настройках приложения. Несмотря на эти потенциальные предубеждения, этот подход к прямому использованию прогнозируемых результатов в моделях вывода популярен в геномике (18), генетике (15), здравоохранении (10) и фенотипировании электронных медицинских карт (6) среди других приложений. (⋅).Когда прогноз основан на достаточно простом алгоритме машинного обучения, это можно сделать напрямую. Однако в настоящее время модели машинного обучения обычно включают сложные алгоритмические подходы, включающие тысячи или миллионы параметров, в том числе k-ближайших соседей (31), опорную векторную машину (SVM) (32), случайный лес (29, 30) и глубокую нейронную сеть. (33).
Вместо этого мы сосредотачиваемся на моделировании взаимосвязи между наблюдаемыми и прогнозируемыми результатами. Наше ключевое понимание состоит в том, что даже когда мы используем сложный инструмент машинного обучения для прогнозирования результатов, относительно простая модель может описывать взаимосвязь между наблюдаемыми и прогнозируемыми результатами (рис.3). Затем мы используем эту предполагаемую взаимосвязь для вычисления смещения и поправок SE для последующих выводных анализов с использованием прогнозируемых значений в качестве зависимой переменной.
Рис. 3.Связь между наблюдаемыми и прогнозируемыми результатами с использованием различных моделей машинного обучения. Данные моделировались на основе наземной модели как линейная модель с нормально распределенным шумом. По оси x — наблюдаемый результат y, а по оси y — прогнозируемые результаты yp.Мы показываем, что независимо от метода прогнозирования, ( A ) k-ближайших соседей, ( B ) случайный лес, ( C ) SVM или ( D ) нейронная сеть, наблюдаемые и прогнозируемые результаты следуют распределение, которое можно точно аппроксимировать с помощью модели линейной регрессии.
Основываясь на наблюдении на рис. 3, мы связываем наблюдаемые с прогнозируемыми данными с помощью гибкой модели k (⋅): ypi = k (yi). [7] Для непрерывных результатов мы можем оценить эту взаимосвязь как линейную регрессионная модель.Для категориальных результатов мы можем использовать модель логистической регрессии или простую модель машинного обучения. Чтобы соответствовать этой модели отношений, мы используем стандартную структуру разработки модели машинного обучения. В этих задачах наблюдаемые данные разделяются на наборы для обучения, тестирования и проверки, и мы предполагаем, что эти три набора имеют одну и ту же систему генерации данных. Как показано на рис. 1, мы можем построить модель прогнозирования в обучающем наборе, а затем вычислить несмещенную оценку модели взаимосвязи в наборе тестирования.Используя эту модель отношений, мы получаем поправку для оценок, SE и статистики тестов для нашей модели вывода. Затем в проверочном наборе мы можем оценить качество нашей коррекции на независимой выборке.
В следующих двух разделах мы выводим основанные на начальной загрузке и аналитические методы для исправления вывода для параметров в модели вывода на будущих наборах данных, где прогнозируемые результаты рассматриваются как наблюдаемые. Для обоих методов мы обобщаем подход к разделению данных на наборы для обучения, тестирования и проверки и предполагаем, что эти три набора следуют одним и тем же процедурам генерации данных.(⋅). Наши методы не обеспечивают оптимальных результатов коррекции вывода в случае, когда новые ковариаты (не наблюдаемые в обучающих и тестовых наборах) вводятся как независимые переменные в последующей модели вывода (см. SI Приложение , раздел 2C для примера и рисунки ).
В Bootstrap-Based Correction мы разрабатываем гибкую процедуру начальной загрузки для коррекции вывода постпрогнозирования. Подход, основанный на начальной загрузке, обеспечивает гибкость как модели отношений, так и последующих моделей вывода.Этот подход применим при условии, что взаимосвязь может быть смоделирована с помощью любой достаточно простой взаимосвязи, которая позволяет осуществлять самозагрузочную выборку. В Analytical Correction мы выводим аналитическую поправку, которая может применяться при дополнительных допущениях. Для аналитического вывода мы предполагаем, что 1) результат непрерывен в наборах для обучения, тестирования и проверки, 2) взаимосвязь между наблюдаемыми и прогнозируемыми результатами может быть смоделирована с использованием нормальной модели линейной регрессии и 3) цель вывода. представляет собой модель линейной регрессии в проверочном наборе.При этих предположениях аналитическая коррекция сохраняется независимо от выбора алгоритма машинного обучения, используемого для прогнозирования.
Исправление на основе начальной загрузки.
В этом разделе мы предлагаем основанный на бутстрапе подход для исправления смещения и дисперсии в последующем выводном анализе. Этот подход может применяться для непрерывных, ненормальных данных, категориальных данных или данных подсчета. Для нашего подхода мы делаем следующие допущения: 1) У нас есть обучающий набор для построения модели прогнозирования, набор для тестирования для оценки параметров модели отношений и набор проверки для соответствия обобщенной регрессионной модели в качестве последующей модели вывода, и все три набора должны следовать одной и той же системе генерации данных; 2) взаимосвязь между наблюдаемыми и прогнозируемыми результатами может быть смоделирована с помощью гибкой, но конкретной простой модели в форме yi = k (ypi), из которой легко сделать выборку; 3) модель отношений сохранится в будущих выборках; и 4) ковариаты, представляющие интерес для последующих выводных анализов, должны быть переменными, которые уже были замечены в наборах для обучения и тестирования и использовались в модели прогнозирования.(Икс).
2) Используйте наблюдаемые результаты и прогнозируемые результаты в наборе тестирования (y (te), yp (te)) для оценки модели отношений y = k (yp), где k (⋅) может быть любой гибкой функцией. .
3) Используйте прогнозируемые результаты и наблюдаемые ковариаты в наборе проверки (yp (val), x (val)) для начальной загрузки следующим образом:
Итерация начальной загрузки b = от 1 до B.
i ) Для i = 1,2,…, n, выборка предсказанных значений и совпадающих ковариат (ypi (val) b, xi (val) b) с заменой.B.
Подход, основанный на начальной загрузке, включает два типа ошибок: ошибку из-за случайной выборки и ошибку предсказания. Ошибка предсказания вводится путем выборки из модели отношений в цикле for, шаг 3, ii. Мы снова делаем упрощающее предположение, что y и yp можно связать с помощью модели, которую легко подобрать. Здесь мы можем сосредоточиться на классе обобщенных линейных моделей, но на шаге 2 процедуры начальной загрузки функция отношения k (⋅) могла бы быть более общей, даже гибкой, как алгоритм машинного обучения, при условии, что ее можно легко оценить и выбрать.(⋅). Это может быть произвольно усложнено, если возможна выборка оценочной взаимосвязи между наблюдаемыми и прогнозируемыми значениями.
Аналитическая поправка.
В этом разделе мы предлагаем аналитический метод для корректировки выводов для параметров в линейной модели нисходящего потока. Мы предполагаем, что данные были разделены на наборы для обучения (tr), тестирования (te) и проверки (val) и что распределение генерации данных одинаково для всех трех наборов: y∼N (f (x), σt2 ), где f (⋅) — произвольная и неизвестная функция ковариат.(Икс). В наборе тестирования мы используем прогнозируемые и наблюдаемые результаты (y (te), yp (te)) для оценки модели линейной зависимости. В наборе проверки мы бы поместили модель линейного вывода, используя предсказанные результаты и ковариаты в матричной нотации (yp (val), X (val)). Наша цель — вывести взаимосвязь между результатом y и некоторым подмножеством ковариат в наборе проверки или в будущем наборе данных, где набор результатов либо чрезмерно дорог, либо сложен.
Подход аналитического вывода вычисляет скорректированные параметры в модели вывода более эффективно, чем подход на основе бутстрапа, но с большими ограничениями в предположениях для расчета решения в замкнутой форме для параметров в последующей модели вывода: 1) Мы концентрируемся в условиях, когда результат может быть только непрерывным и приблизительно нормально распределенным, 2) модель отношений, оцененная в наборе тестирования, также приблизительно нормально распределена, и 3) последующая модель вывода должна быть линейной моделью, из которой мы можем исправить вывод.
В наборе проверки в идеале мы бы поместили модель (val) | X (val) ∼N (X (val) β (val), σi2). [8] Однако результат не наблюдается в наборе проверки . Вместо этого мы подбираем модель: p (val) | X (val) ∼N (X (val) βp (val), σp2). [9] В этом случае мы больше не оцениваем ту же величину из-за изменения зависимая переменная. Эта нескорректированная стратегия вывода постпрогнозирования обычно используется в реальной практике (6, 14⇓⇓⇓ – 18). Наша цель здесь — разработать поправку, чтобы восстановить вывод о β (val), как если бы наблюдаемые результаты были доступны.(val) нельзя вычислить напрямую. Итак, сначала мы хотим оценить y (val), используя условное ожидание E [y (val) | X (val)]. Это ожидание можно записать как Ey (val) | X (val) = EEy (val) | X (val), yp (val) | X (val) ≈EEy (val) | yp (val) | X (val) = γ0 (te) + γ1 (te) X (val) βp (val). [11] Здесь βp (val) представляет параметр в модели вывода линейной регрессии, где прогнозируемый результат используется в качестве зависимой переменной. Приближение в формуле. 11 основан на использовании отношения между прогнозируемым результатом и наблюдаемым результатом E (y (val) | yp (val)) в качестве приближения к условному ожиданию E (y (val) | X (val), yp (val) )) (см. SI Приложение , раздел 1A.(val). Проблема в том, что SE не может быть просто рассчитана путем подбора регрессионной модели в формуле. 8 , потому что y (val) не наблюдается. Вместо этого мы сначала оцениваем условную дисперсию Var [y (val) ∣X (val)], используя дисперсию, которая исходит из обеих моделей отношений в формуле. 10 и модель вывода в формуле. 9 с прогнозируемыми результатами. Это аналогичный подход к выводу ожидания выше, где мы предполагаем, что наблюдаемый результат неизвестен. Используя закон общей условной дисперсии Vary (val) ∣X (val) = EVary (val) ∣yp (val), X (val) ∣X (val) + VarEy (val) ∣yp (val), X (val) ∣X (val) ≈EVary (val) ∣yp (val) ∣X (val) + VarEy (val) ∣yp (val) ∣X (val) = σr (te) 2 + γ1 (te) 2σp (val) 2, [14] где на втором шаге уравнения.p (val) 2). [16]
Моделированные данные.
Мы моделируем независимую ковариату x и член ошибки eu, а затем наблюдаем результат y, используя модель истинного состояния природы в уравнении. 5 . Истинное состояние природы не наблюдается напрямую в практических задачах, но может быть определено в смоделированных задачах. Мы рассматриваем как случай непрерывного результата в Непрерывный случай , так и случай двоичного результата в Двоичный случай , которые демонстрируют, что нескорректированный вывод постпрогнозирования приводит к смещению оценок, малым SE и статистике антиконсервативных тестов.
Мы также включаем моделирование, демонстрирующее антиконсервативное смещение в значениях P из нескорректированного вывода постпредсказания в SI Приложение , раздел 2A. Ключевое понимание наших методов postpi зависит от соответствия отношения между наблюдаемыми и прогнозируемыми результатами (y и yp), оцененными в тестовой выборке. Во многих случаях эту взаимосвязь можно описать как простую модель, но это не всегда верно. Например, когда прогнозируемые значения получены от слабых учеников, корреляция между наблюдаемыми и прогнозируемыми результатами может быть недостаточно сильной, чтобы позволить скорректированный вывод.Как и ожидалось, мы наблюдаем улучшение рабочих характеристик наших методов с увеличением точности модели прогнозирования. Мы показываем, что наши методы postpi успешно аппроксимируют оценки, SE, статистику t и значения P , как мы получили бы, используя наблюдаемое y ( SI, приложение , рис. 1 и 2). Мы также показываем, что наши поправки достаточно устойчивы к уровням корреляции между y и yp в диапазоне от 0,1 до 0,8. На всех уровнях корреляции наши методы postpi успешно корректируют распределение значений P по сравнению с нескорректированным выводом постпрогнозирования — восстанавливая контроль частоты ошибок типа I ( SI, приложение , рис.1).
Сплошной корпус.
Для непрерывного случая мы моделируем ковариаты xij и члены ошибки eui из нормальных распределений, а затем моделируем наблюдаемый результат yi, используя линейную функцию h (⋅) в качестве модели истинного состояния природы для i = 1,…, n, j = 1,…, стр. (34)
В каждом цикле моделирования мы устанавливаем общий размер выборки n = 900 и размерность ковариантной матрицы p = 4. Чтобы имитировать сложное распределение генерации данных и сделать прогнозы достаточно вариабельными для иллюстративных целей, мы генерируем данные, включающие как линейные, так и сглаженные члены.Для сглаженных членов мы используем сглаживание скользящей медианы Тьюки с параметром сглаживания по умолчанию «3RS3R» (35). Члены ошибки также моделируются из нормального распределения с независимой дисперсией. Спецификация модели: xi1, xi2, xi3∼N (1,1) xi4∼N (2,1) eui∼N (0,1) yi = β1xi1 + β2xi2 + β3⋅smoothxi3 + β4⋅smoothxi4 + eui. [17] Мы создаем набор для обучения, тестирования и проверки путем случайной выборки наблюдаемых данных в три группы равного размера, каждая с размером выборки 300. Для 300 смоделированных случаев мы фиксируем значения β2 = 0.(⋅) мы используем все ковариаты xi1, xi2, xi3, xi4 в качестве признаков для прогнозирования наблюдаемых результатов yi. Этот прогноз предназначен для моделирования случая, когда мы пытаемся максимизировать точность прогнозирования, а не для выполнения статистического вывода. В наборе тестирования мы применяем обученную модель прогнозирования, чтобы получить прогнозируемые результаты ypi. Мы оцениваем взаимосвязь между наблюдаемым и прогнозируемым результатом (yi и ypi) в виде простой модели линейной регрессии: yi∼N (γ0 + γ1ypi, σr2).
Наша оценка эффективности различных методов выполняется на основе независимой проверки, установленной путем подбора модели линейной регрессии в качестве модели вывода.Мы сравниваем вывод с использованием прогнозируемого результата без коррекции, вывод постпредсказания через аналитический вывод postpi и вывод постпредсказания через параметрический бутстрап-постпи и непараметрический бутстрап-постпи (подробности метода см. В SI, приложение , раздел 2B). В этом моделировании у нас также есть наблюдаемый результат y, поэтому мы можем вычислить коэффициенты, оценки и статистику испытаний, которые получены при использовании наблюдаемых значений в моделях вывода. Базовая модель, с которой мы сравниваем, соответствует модели регрессии E [yi | xi1] = β0 + xi1β1 наблюдаемым данным в проверочном наборе.
Мы используем графики Hextri для одновременного сравнения нескольких графиков рассеяния (37). Эти графики разработаны таким образом, что размер каждой ячейки пропорционален количеству точек в ячейке, и они разделены на цвета пропорционально количеству точек из каждого сравнения. В этом примере моделирования прогноз имеет относительно небольшое смещение, поэтому оцененные коэффициенты, использующие прогнозируемый результат, относительно близки к оценкам, использующим наблюдаемый результат. На рис. 4 A все цвета лежат близко к линии равенства.Однако SE для подхода без коррекции (оранжевый цвет) на рис. 4 B намного ниже, чем то, что мы наблюдали бы в наблюдаемых результатах. Это связано с тем, что функция прогнозирования пытается уловить функцию среднего, но не дисперсию наблюдаемого результата. Мы вычисляем среднеквадратичную ошибку (rmse) (38), чтобы показать, что подходы аналитического вывода postpi и бутстрапа postpi превосходят подход без коррекции. SE ближе к истине со снижением rmse с 0.088 для отсутствия коррекции (оранжевый цвет) до 0,015 для аналитического вывода postpi (зеленый цвет), а также улучшено до 0,015 для параметрической начальной загрузки postpi (темно-синий цвет) и 0,019 для непараметрической начальной загрузки postpi (светло-синий цвет) на рис.4 B . Улучшенные SE отражены в улучшенной статистике t с использованием аналитического вывода postpi и двух подходов bootstrap postpi на рис.4 C , с rmse сниженным с 26,33 для отсутствия коррекции (оранжевый цвет) до 2,45 для аналитического вывода postpi (зеленый цвет). ) и улучшен до 2.41 для параметрической начальной загрузки postpi (темно-синий цвет) и 2,89 для непараметрической начальной загрузки postpi (светло-синий цвет).
Рис. 4.Непрерывное моделирование. Данные были смоделированы из наземной модели, как описано в непрерывном случае . По оси x отложены значения, рассчитанные с использованием наблюдаемого результата, а по оси y — значения, рассчитанные без коррекции (оранжевый цвет), аналитическая деривация postpi (зеленый цвет), параметрическая bootstrap postpi (темно-синий цвет), и непараметрический бутстрап postpi (голубой цвет).Мы показываем ( A, ), оценки одинаковы для всех четырех подходов, поскольку данные были смоделированы из нормальной модели, ( B ) SE слишком малы для неисправленного вывода (оранжевый цвет), но исправлены с помощью наших подходов, и ( C ) Статистика t антиконсервативно смещена из-за неисправленного вывода, но исправлена с помощью наших подходов.
Бинарный корпус.
Для двоичного случая мы моделируем категориальную ковариату xic, непрерывные ковариаты xi1, xi2 и член ошибки eui, а затем наблюдаемый результат yi, предполагая обобщенную линейную модель f (⋅) для i = 1,…, n.В этом случае мы указываем модель истинного естественного состояния f (⋅) как модель логистической регрессии. Чтобы смоделировать наблюдаемые результаты yi, мы сначала настраиваем ковариаты с помощью линейной комбинации, в которой мы сглаживаем подмножество непрерывных ковариат, используя сглаживание медианы Тьюки (35), и включаем ошибки для увеличения вариабельности результатов yi. Мы применяем обратную логит-функцию к линейному предиктору для моделирования вероятностей, которые мы используем для моделирования результатов Бернулли (yi = 0 или 1) с помощью биномиальных распределений.Моделируем следующим образом: xi1∼N (1,1) xi2∼N (2,1) xic∼Multinom (1, (1 / 3,1 / 3,1 / 3)) eui∼N (0,1) zi = βB1 (xic = B) + βC1 (xic = C) + β1⋅smoothxi1 + β2⋅smoothxi2 + euipri = 11 + e − ziyi∼Binom (1, pri). [18] Мы генерируем 1500 выборок для каждой итерации и разделяем данные в наборы для обучения, тестирования и проверки равного размера n = 500. Мы устанавливаем 1 (xc = C) в качестве интересующей ковариаты в последующей модели логической регрессии. Затем мы используем два метода начальной загрузки — параметрическую и непараметрическую postpi начальной загрузки — для оценки скорректированной оценки коэффициента, SE и тестовой статистики (39).(⋅). Затем мы применяем обученную модель прогнозирования в наборах для тестирования и проверки, чтобы получить прогнозируемый результат ypi, а также вероятность pri прогнозируемых результатов (то есть pri = Pr (yi = 1)). В тестовом наборе мы используем логистическую регрессию для оценки взаимосвязи между наблюдаемым результатом и прогнозируемой вероятностью: g (E [yi = 1 | pri]) = γ0 + priγ1, где g (⋅) — натуральный логарифм коэффициенты такие, что g (p) = Ln (p1 − p). Здесь мы формируем модель отношений с прогнозируемой вероятностью. Причина в том, что результат является дихотомическим, поэтому у нас мало гибкости для моделирования дисперсии наблюдаемого результата как функции предсказанного результата.Вместо этого использование предсказанной вероятности обеспечивает большую гибкость для моделирования взаимосвязи. В случае двоичного результата подход аналитического вывода больше не применяется, поэтому мы применяем только два метода коррекции начальной загрузки. В наборе проверки мы выполняем шаги с 1 по 5 процедуры начальной загрузки. Сначала мы устанавливаем размер начальной загрузки B = 100, чтобы запустить цикл for. На шаге 3, ii, ỹib = k (prib), мы моделируем значения в два этапа: 1) используем prib и модель предполагаемой взаимосвязи для прогнозирования вероятности получения «успешного» результата (i.е., Pr (ib = 1)), а затем 2) выборка ỹib из биномиального распределения с параметром вероятности Pr (ỹib = 1), полученным на шаге 1. На шаге 3, iii мы снова подгоняем модель логистической регрессии как модель вывода: g [E (ỹib | xcb)] = βp0 + 1 (xc = C) bβpC. Затем на шагах 4 и 5 мы оцениваем параметрический и непараметрический коэффициент postpi начальной загрузки, SE и тестовую статистику.
Для 300 смоделированных случаев мы фиксируем значения β1 = 1, β2 = −2, βB = 1. Здесь мы выбираем 1 (xc = C) в качестве ковариаты, представляющей интерес в последующем выводном анализе, и устанавливаем βC как диапазон значений в [−2, −1.5,…, 4.5,5]. Во многих симуляциях возникает проблема разреженности дихотомических ковариат, когда вывод из наблюдаемого yi был бы нестабильным. В этом примере мы исключаем из моделирования такие редкие случаи, которые приводят к чрезвычайно большим SE и неточным оценкам во всех подходах. На рис. 5 A и B мы видим, что оценки и SE завышены в случае отсутствия коррекции (оранжевый цвет). Более подробно, мы видим смещение в оценке коэффициента при использовании подхода без коррекции (оранжевый цвет) на рис.5 А с rmse 2.94 по сравнению с истиной. Это смещение исправляется с помощью методов postpi параметрического бутстрапа (темно-синий цвет) и непараметрического бутстрапа (голубой цвет) с rmse, сниженным до 0,53. SE для отсутствия коррекции (оранжевый цвет) на рис. 5 B имеют rmse 0,49, но уменьшены до 0,018 для параметрической начальной загрузки postpi (темно-синий цвет) и 0,025 для непараметрической начальной загрузки postpi (голубой цвет). На рис. 5 C статистика t имеет значение rmse 2.06 без коррекции (оранжевый цвет), 2,04 для параметрической начальной загрузки postpi (темно-синий цвет) и 2,12 для непараметрической начальной загрузки postpi (голубой цвет). Мы наблюдаем небольшое консервативное смещение в статистике t из-за поправок postpi — синие точки постоянно находятся немного ниже линии равенства. Это консервативное смещение является приемлемым компромиссом в случаях, когда наблюдаемые результаты недоступны.
Рис. 5.Двоичное моделирование. Данные были смоделированы из наземной модели, как описано в Двоичный случай .По оси x отложены значения, рассчитанные с использованием наблюдаемого результата, а по оси y — значения, рассчитанные без коррекции (оранжевый цвет), параметрической начальной загрузки postpi (темно-синий цвет) и непараметрической начальной загрузки postpi (светло-синий цвет). ). Мы показываем ( A ) нескорректированные оценки с антиконсервативной предвзятостью, но это смещение исправлено с помощью наших подходов postpi, ( B ) нескорректированные SE также раздуваются и корректируются postpi, и ( C ) статистика t показывают небольшое консервативное смещение по сравнению со случаем без коррекции.
Приложения.
Чтобы продемонстрировать широкую применимость нашей методологии для выполнения постпредсказательного вывода, мы представляем два примера из очень разных областей: геномика и вербальный анализ аутопсии. Эти приложения имеют очень мало общего с научной точки зрения, но представляют собой два громких примера, в которых логический вывод обычно выполняется с нескорректированными прогнозами в качестве конечной (зависимой) переменной.
Сначала рассмотрим проект «Recount2» (https: // jhubiostatistics.shinyapps.io/recount) (40), который состоит из данных экспрессии генов секвенирования РНК (RNA-seq) для более чем 70000 человеческих образцов, выровненных с использованием общего конвейера, обработанного в Rail-RNA (41). Хотя в человеческих образцах Recount2 имеется доступная информация об экспрессии генов, не все образцы содержат информацию о наблюдаемом фенотипе, поскольку большинство образцов взяты непосредственно из общедоступных данных в архиве чтения последовательностей (42). Однако ранее мы показали, что многие из этих недостающих фенотипических данных можно предсказать на основе геномных измерений (8).Наша цель — сделать вывод, используя эти предсказанные фенотипы.
Во-вторых, мы описываем распределение (прогнозируемых) причин смерти. В регионах мира, где рутинный мониторинг рождений и смертей невозможен, одним из подходов к оценке распределения смертей по причинам является вербальное вскрытие (VA). Эти опросы проводятся с опекуном или родственником умершего и задают вопросы об обстоятельствах смерти человека и обычно проводятся, когда смерть происходит за пределами больниц или обычной медицинской помощи.Для обучения алгоритмов, которые прогнозируют причины смерти на основе зарегистрированных симптомов, используются либо рекомендации экспертов о взаимосвязи между симптомами, о которых сообщалось до смерти, и возможной причиной, либо небольшие наборы данных «золотого стандарта». Разработка алгоритмов для прогнозирования причин смерти является активной областью исследований и является сложной задачей, поскольку данные обычно содержат смесь бинарных, непрерывных и категориальных симптомов, а многие причины смерти имеют схожие представления. После определения предполагаемой причины смерти общей задачей является описание закономерностей в распределении причин смерти.Например, ученому может быть интересно узнать, как распределение смертей зависит от региона или пола.
Прогнозирование типов тканей.
Мы рассматриваем мотивирующую проблему из проекта Recount2 (40) (https://jhubiostatistics.shinyapps.io/recount/). В этом примере интересующий нас фенотип — это тип ткани, из которой отбирается РНК (43). Понимание уровней экспрессии генов в тканях и типах клеток имеет множество применений в базовой молекулярной биологии. Многие темы исследований сосредоточены на поиске того, какие гены экспрессируются в каких тканях, с целью расширить наше фундаментальное понимание происхождения сложных признаков и заболеваний (44–48).Проект Genotype-Tissue Expression (GTEx) (49), например, изучает, как уровни экспрессии генов варьируются у разных людей и различных тканей человеческого тела для широкого спектра первичных тканей и типов клеток (44, 49). Следовательно, чтобы лучше понять клеточный процесс в биологии человека, важно изучить различия в уровнях экспрессии генов в разных типах тканей.
Несмотря на то, что типы тканей доступны в GTEx (49), они недоступны для большинства образцов в Recount2.В предыдущей статье (8) мы разработали метод прогнозирования отсутствующих фенотипов с использованием данных об экспрессии генов. В этом примере мы собрали подмножество образцов, в которых наблюдались типы тканей, такие как ткань груди или жировая ткань. У нас также были предсказанные значения для вышеуказанных выборок, рассчитанные в предыдущем обучающем наборе (8) с использованием 2281 экспрессируемых областей (50) в качестве предикторов. Наша цель в этом примере — понять, какая из этих областей больше всего связана с тканью груди в новых образцах (т. Е., образцы без наблюдаемых типов тканей), чтобы мы могли понять, на какие измеренные гены больше всего влияют биологические различия между грудной и жировой тканями. Хотя здесь нас интересует фенотип, состоящий в типах тканей, особенно в тканях груди и жировой ткани, наш метод может широко применяться для любых прогнозов для всех фенотипов.
Чтобы протестировать наш метод, мы собрали 288 образцов из Recount2 как с наблюдаемыми, так и с предсказанными типами тканей. Среди наблюдаемых типов тканей 204 образца рассматриваются как жировые ткани, а 84 образца — как ткани груди.Прогнозируемые значения, полученные из ранее обученного набора данных (8), включают прогнозируемый тип ткани (например, жировую ткань или ткань груди) и вероятность присвоения прогнозируемого типа ткани. В этом примере мы сравниваем подходы без коррекции и начальной загрузки postpi только потому, что результаты (типы тканей), о которых мы заботимся, являются категориальными.
Интересующая нас модель вывода — это g [E (yi = 1 | ERij)] = β0j + β1jERj. Здесь g (⋅) — функция логит-связи для j = 1,…, 2,281 (выраженные области), а i = 1,…, n, n — общее количество выборок в Recount2.В модели yi = 1 или yi = 0 представляют, наблюдается ли ткань груди или жировая ткань в i-м образце, а ERij — это уровень экспрессии гена для j-й области в i-м образце.
Для этого набора данных (288 образцов) у нас есть результаты бинарного типа ткани. Поскольку прогнозируемые результаты были получены в предварительно обученном наборе (8), нам нужно только разделить наши данные на набор для тестирования и проверки, каждый с размером выборки n = 144. В тестовом наборе мы подобрали модель k-ближайших соседей (31), чтобы оценить взаимосвязь между наблюдаемым типом ткани и вероятностью присвоения прогнозируемого значения.. Подобно тому, что мы сделали с смоделированными данными в Simulated Data , в этом примере мы устанавливаем Fγ как биномиальное распределение с параметром вероятности (то есть вероятностью присвоения результата как рак груди), оцененным из модели отношений. Таким образом, мы используем предполагаемую взаимосвязь для учета необходимых вариаций в смоделированных результатах.
Среди 2281 экспрессируемых областей (50), используемых для прогнозирования типа ткани (8), мы заботимся о регионах, которые имеют значения экспрессии в относительно большом количестве образцов в проверочном наборе.Хорошо известно, что многие измерения RNA-seq могут быть нулевыми, если количество собранных считываний невелико. Чтобы избежать подгонки моделей с высокой степенью вариабельности из-за ковариат с нулевой дисперсией, мы подбираем модели вывода логистической регрессии только для каждой отфильтрованной выраженной области с выраженными значениями по крайней мере для 20% выборок. В рамках этой процедуры фильтрации мы включаем 101 выраженную область в качестве регрессионных переменных и подгоняем модель вывода, описанную выше, к каждому региону в наборе проверки. Затем мы получаем 101 оценку, SE и статистику t .Мы сравниваем их с подходом без коррекции, как мы это делали с смоделированными данными.
Путем сравнения rmse мы заметили, что оценки, SE и тестовая статистика улучшаются от отсутствия коррекции до параметрических и непараметрических методов начальной загрузки postpi. На рис. 6 A оценки без коррекции (оранжевый цвет) имеют среднеквадратичное значение 0,36 по сравнению с истиной, и оно уменьшается до 0,08 с параметрическим бутстрапом postpi (темно-синий цвет) и непараметрическим бутстраповым postpi (голубой цвет). СЭ на рис.6 B имеют rmse 0,08 для отсутствия коррекции (оранжевый цвет), но исправлено до 0,01 для параметрической начальной загрузки postpi (темно-синий цвет) и 0,03 для непараметрической начальной загрузки postpi (светло-синий цвет). Итоговая статистика t улучшена с rmse 0,91 без коррекции (оранжевый цвет) до 0,63 для параметрической начальной загрузки postpi (темно-синий цвет) и 0,93 для непараметрической начальной загрузки postpi (голубой цвет).
Рис. 6.Прогнозирование зависимости груди от жировой ткани. Данные были собраны из Recount2, как описано в Прогнозирование типов тканей .По оси x отложены значения, рассчитанные с использованием наблюдаемого результата, а по оси y — значения, рассчитанные без коррекции (оранжевый цвет), параметрической начальной загрузки postpi (темно-синий цвет) и непараметрической начальной загрузки postpi (светло-синий цвет). ). Мы показываем ( A ) оценки, ( B ) SE и ( C ) статистику t . Два подхода начальной загрузки postpi явно улучшают оценки и SE по сравнению с отсутствием коррекции.
Мы также применили наш подход к правильному выводу для моделей, использующих прогнозируемое качество РНК в качестве примера того, как сделать вывод после прогнозирования для непрерывных результатов ( SI Приложение , раздел 3A).
Описание распределения причин смерти.
Теперь мы переходим ко второму примеру, где интересующий результат — это (прогнозируемая) причина смерти, а исходные данные — это симптомы или обстоятельства, о которых сообщил опекун или родственник (51). Симптомы могут включать, например, то, была ли у человека высокая температура перед смертью, как долго длился кашель (если о нем сообщалось) или сколько раз человек посещал медицинского работника. Мы используем данные Консорциума исследований показателей здоровья населения (PHMRC), который включает около 7800 смертей золотого стандарта из шести регионов мира.Эти данные редки, потому что они содержат как физическое вскрытие (включая патологию и диагностические тесты), так и устное вскрытие. Как правило, только небольшая часть смертей будет иметь назначенную причину (например, клиницист, читающий устное вскрытие трупа), и эти несколько помеченных смертей будут использоваться в качестве исходных данных для обучения модели для оставшихся смертей.
Мы разделяем данные на наборы для обучения и тестирования, при этом 75% данных используются для обучения. Данные PHMRC классифицируют причины смерти на нескольких уровнях детализации.В наших экспериментах мы объединили причины в 12 основных причин смерти (рак, диабет, почечные заболевания, заболевания печени, сердечно-сосудистые заболевания, инсульт, пневмония, ВИЧ / СПИД или туберкулез, материнские причины, внешние причины, другие инфекционные заболевания и другие неинфекционные заболевания). болезней). Мы спрогнозировали причину смерти с помощью InSilicoVA (52), который использует наивный байесовский классификатор, встроенный в байесовскую структуру, чтобы учесть неопределенность между классификациями причин.
В этом примере мы хотим понять тенденции 12 комбинированных причин смерти по множеству симптомов, представляющих поведение в отношении здоровья и демографические данные.Демографические симптомы включают возраст умершего и пол (мужской или женский) умершего. К поведенческим симптомам относятся: употреблял ли умерший табак (да или нет), употреблял ли алкоголь (да или нет) и пользовался ли медицинской помощью в связи с болезнью (да или нет). Дополнительные симптомы включают наличие у умершего ожирения (да или нет), несчастного случая (да или нет) и предыдущие медицинские записи (да или нет). Эти симптомы используются в модели обучения как подмножество симптомов для классификации причины смерти с помощью InSilicoVA (52) и снова используются для последующих статистических выводов.Нас интересует модель вывода: g [E (yi | SYMi j)] = β0j + β1jSYMj. Здесь g (⋅) — функция логит-связи для j = 1,…, 13 (симптомы), а i = 1,…, n, n — общее количество выборок в наборе данных. В этой модели yi представляет собой одну из 12 комбинированных причин в i-й выборке, а SYMi j представляет собой j-й интересующий симптом в i-й выборке.
Для этого набора данных мы используем категориальные исходы в качестве причин смерти для 1960 выборок и предполагаем, что результаты не наблюдаются, как это обычно бывает на практике, для остальных случаев.Поскольку предсказанные значения были получены в предварительно обученном наборе с использованием InSilicoVA (52), мы разделяем наши данные только на наборы для тестирования и проверки, каждый с размером выборки n = 980. В тестовом наборе мы подобрали модель k-ближайших соседей (31), чтобы оценить взаимосвязь между наблюдаемой причиной смерти и вероятностью определения причины. В наборе проверки мы следуем процедуре начальной загрузки..В этом примере мы устанавливаем Fγ как полиномиальное распределение с параметрами вероятности (то есть вероятностью присвоения каждой из 12 основных причин смерти), оцененными на основе модели взаимосвязи, как мы это делали в смоделированных данных.
Среди всех симптомов, используемых для прогнозирования причин смерти (52), мы используем подмножество симптомов, которые также имеют сбалансированные классы по 12 широким причинам смерти. Это сделано для того, чтобы избежать подгонки моделей с высокой вариабельностью из-за ковариат с нулевой дисперсией, которая классифицируется как хорошо известная проблема для редких результатов (53).Затем мы фильтруем восемь симптомов, которые нас интересуют в качестве регрессионных переменных, и подбираем модель логического вывода регрессии для каждого выбранного симптома в наборе проверки. Есть одна непрерывная переменная и семь категориальных регрессионных переменных, каждая с двумя уровнями факторов (да или нет). Для результатов вывода мы получаем восемь оценок, SE и статистику t в проверочном наборе. Затем мы сравниваем их с подходом без коррекции, как мы это делали с моделированными данными.
Мы заметили, что нескорректированные оценки, SE и статистика t (оранжевый цвет) имеют более высокое среднеквадратичное отклонение по сравнению с параметрическим методом начальной загрузки postpi (темно-синий цвет).На рис. 7 A оценки без коррекции имеют rmse 0,46 (оранжевый цвет) по сравнению с истинным значением, которое уменьшается до 0,24 с помощью параметрических (темно-синий цвет) и непараметрических (светло-синий цвет) методов начальной загрузки postpi. SE без коррекции на рис. 7 B имеют rmse 0,03 (оранжевый цвет), которые скорректированы до rmses 0,013 для параметрической начальной загрузки postpi (темно-синий цвет) и 0,024 для непараметрической начальной загрузки postpi (голубой цвет). Итоговая статистика t на рис.7 C улучшены с rmse 1,21 без коррекции (оранжевый цвет) до 0,79 для параметрической начальной загрузки postpi (темно-синий цвет) и до 0,73 для непараметрической начальной загрузки postpi (светло-синий цвет).
Рис. 7.Прогнозирование двенадцати причин смерти. Данные были собраны из PHMRC, описанного в Describing the cause of death distributions . По оси x отложены значения, рассчитанные с использованием наблюдаемого результата, а по оси y — значения, рассчитанные без коррекции (оранжевый цвет), параметрической начальной загрузки postpi (темно-синий цвет) и непараметрической начальной загрузки postpi (светло-синий цвет). ).Мы показываем ( A ) оценки, ( B ) SE и ( C ) статистику t . Подход параметрической начальной загрузки postpi улучшает среднеквадратичную ошибку оценок, SE и статистику t по сравнению с отсутствием коррекции.
Обсуждение
По мере того, как машинное обучение становится все более распространенным в различных научных условиях, прогнозируемые результаты будут все чаще использоваться в качестве зависимых переменных в последующих статистических анализах. Как мы показали, нескорректированный вывод постпрогнозирования может привести к сильно изменчивым или смещенным оценкам интересующих параметров, слишком маленьким SE, антиконсервативно смещенным значениям P и ложным срабатываниям.
Мы ввели методы корректировки вывода постпрогнозирования и корректировки точечных и интервальных оценок при использовании прогнозируемых результатов вместо наблюдаемых. Наш метод достаточно гибок, чтобы его можно было применять к непрерывным и категориальным данным о результатах, наблюдаемых в таких областях, как медицина, общественное здравоохранение и социология. С помощью смоделированных и реальных данных мы показываем, что наши результаты превосходят наиболее распространенный текущий подход, состоящий в игнорировании шага прогнозирования и выполнении вывода без исправлений.Путем надлежащего моделирования изменчивости и систематической ошибки из-за шага прогнозирования, оценки, SE, статистика тестов и значения P корректируются в соответствии с анализом золотого стандарта, который мы получили бы, как если бы мы использовали истинные результаты.
Наш подход основан на ключевом наблюдении: взаимосвязь между наблюдаемыми и прогнозируемыми результатами может быть описана как простая модель. Хотя это наблюдение эмпирически верно для рассмотренных нами моделей и алгоритмов, оно не может быть универсальным.Одним из ограничений нашего подхода является то, что он зависит от соответствия модели отношений. Например, когда прогнозируемые значения получены от слабых учеников, корреляция между наблюдаемыми и прогнозируемыми результатами не является сильной, что может не быть хорошо отражено простой моделью. Другое ограничение состоит в том, что мы предполагаем, что наборы для обучения, тестирования и проверки соответствуют одному и тому же распределению генерации данных. Если это предположение не выполняется, логический вывод, выполняемый для начальных значений в наборе проверки, больше не будет отражать истинный базовый процесс генерации данных.Потенциальное решение состоит в том, что мы должны сначала провести нормализацию данных, используя такие методы, как анализ суррогатных переменных (54), удалить нежелательные вариации (55) и removeBatchEffect в линейных моделях для данных микрочипа (56), чтобы исправить скрытые искажающие факторы при тестировании или валидации. наборы. Затем нормализованные образцы могут быть введены в наш метод для последующего логического анализа.
Несмотря на эти ограничения, корректировка вывода постпрогнозирования имеет решающее значение для точного вывода при использовании результатов, полученных с помощью методов машинного обучения.Наша поправка представляет собой шаг к общему решению проблемы вывода постпрогнозирования.
Выражение признательности
Исследование, представленное в этой публикации, было поддержано Национальным институтом общих медицинских наук Национальных институтов здравоохранения (NIH) в рамках награды R01GM121459, Национальным институтом психического здоровья Национального института здоровья (NIH) в рамках премии DP2Mh222405 и Юнис Национальный институт детского здоровья и развития человека им. Кеннеди Шрайвера Национального института здоровья, награда R21HD095451.
Сноски
Вклад авторов: S.W., T.H.M. и J.T.L. спланированное исследование; S.W., T.H.M. и J.T.L. проведенное исследование; S.W., T.H.M. и J.T.L. внесены новые реагенты / аналитические инструменты; С.В. проанализированные данные; и S.W., T.H.M. и J.T.L. написал газету.
Авторы заявляют об отсутствии конкурирующей заинтересованности.
Эта статья представляет собой прямое представление PNAS.
Эта статья содержит вспомогательную информацию на сайте https: // www.pnas.org/lookup/suppl/doi:10.1073/pnas.2001238117/-/DCSupplemental.
- Copyright © 2020 Автор (ы). Опубликовано PNAS.
Методы исправления ошибок и сверления слов
Ниже приведены несколько методов исправления ошибок и одна процедура для тренировки словарного запаса, которые учителя, наставники или родители могут использовать с развивающимися читателями.
Word Supply:
Перед тем, как ученик начнет читать, скажите ему: «Если вы подойдете к слову, которого вы не знаете, я помогу вам с ним.Я скажу вам правильное слово, а вы будете слушать и указывать на слово в книге. После этого я хочу, чтобы вы повторили это слово и продолжили чтение. Старайтесь изо всех сил не делать ошибок ». Когда ученик совершает ошибку при чтении (например, замена, пропуск, 5-секундное колебание), немедленно произнесите правильное слово для ученика, попросите ученика правильно повторить слово, а затем укажите ученик, чтобы продолжить чтение ПРИМЕЧАНИЕ: Чтобы избежать перерывов в чтении, не исправляйте мелкие ошибки ученика (например,g., неверное прочтение или опущение или, отбрасывание суффиксов, таких как -s, -ed или -ing)
Word — это самый простой способ исправления ошибок, поэтому он идеально подходит для использования репетиторами или родителями учащихся. С другой стороны, этот подход менее эффективен, чем другие описанные здесь, для создания словарного запаса учащихся для чтения (Singh, 1990).
Повторение предложения:
В начале сеанса чтения скажите студенту: «Если вы подойдете к слову, которого не знаете, я помогу вам с ним.Я скажу вам правильное слово, а вы будете слушать и указывать на слово в книге. После этого я хочу, чтобы вы повторили слово, а затем прочитали оставшуюся часть предложения. Затем я хочу, чтобы вы снова прочитали это предложение. Старайтесь изо всех сил не делать ошибок ».
Когда ученик совершает ошибку чтения (например, подстановка, пропуск, 5-секундное колебание), немедленно произнесите правильное слово для ученика и попросите ученика правильно повторить слово. Затем предложите студенту перечитать все предложение, в котором произошла ошибка.Затем ученик продолжает читать отрывок. (Если учащийся повторяет исходную ошибку чтения при перечитывании предложения, вы должны снова правильно произнести слово и попросить учащегося повторить слово. Затем продолжайте.) ПРИМЕЧАНИЕ: Чтобы избежать слишком частых перерывов в чтении, не исправляйте незначительные ошибки учащегося ( например, неправильное прочтение или пропуск или, отбрасывание суффиксов, таких как -s, -ed или -ing) (Singh, 1990).
Иерархия «Word Attack»:
При таком подходе преподаватель предлагает ученику применить иерархию навыков атаки слов всякий раз, когда ученик неправильно прочитал слово.Инструктор дает эти подсказки в порядке убывания. Если ученик правильно определяет слово после любой реплики, инструктор прекращает подачу реплики в этот момент и направляет ученика продолжить чтение. ПРИМЕЧАНИЕ. Чтобы избежать слишком частых перерывов в чтении, не исправляйте незначительные ошибки учащихся (например, неправильное чтение или пропуск или, удаление суффиксов, таких как -s, -ed или -ing).
Вот реплики инструктора по иерархии «Word Attack»:
- 1. «Попробуй другой способ». Этот сигнал дается сразу после ошибки чтения и предупреждает учащегося о том, что он или она неправильно прочитали слово.
- 2. «Закончи предложение и отгадай слово». Учащемуся предлагается использовать контекст предложения, чтобы найти правильное произношение слова.
- 3. «Разбей слово на части и произноси каждую». Учащемуся предлагается самостоятельно озвучивать части слова.
- 4. Используя учетную карточку, преподаватель перекрывает части слова, а каждый ученик произносит только ту часть слова, которая видна. Такой подход учит студента способу уменьшения количества визуальной информации в каждом слове.
- 5. «Какой звук издает ___?» Когда репетитор покрывает выбранные части слова с помощью каталожной карточки, студенту предлагается использовать звуковую информацию для произнесения слова.
- 6. «Слово ___». Если учащийся не может расшифровать слово, несмотря на поддержку инструктора, инструктор передает слово. Учащемуся предлагается повторить слово и продолжить чтение.
(Харинг и др., 1978).
Сверление слова ошибки:
Упражнение по слову ошибки — эффективный способ пополнить словарный запас для чтения.Процедура состоит из 4 шагов:
Если студент неправильно прочитал слово во время сеанса чтения, запишите слово ошибки и дату в отдельном «Журнале слов ошибки».
- 1. В конце сеанса чтения запишите все слова с ошибками из сеанса чтения на учетные карточки. (Если учащийся неправильно прочитал более 20 различных слов во время занятия, используйте только первые 20 слов из вашего списка слов-ошибок. Если учащийся неправильно прочитал менее 20 слов, обратитесь к «Журналу слов ошибок» и выберите достаточно дополнительных ошибок. слова из прошлых занятий, чтобы составить обзорный список до 20 слов.)
- 2. Просмотрите учетные карточки вместе с учеником. Каждый раз, когда ученик произносит слово правильно, выньте эту карту из колоды и отложите в сторону. (Слово считается правильным, если оно правильно прочитано в течение 5 секунд. Самокорректирующиеся слова считаются правильными, если они сделаны в течение 5-секундного периода. Слова, прочитанные правильно после истечения 5-секундного периода, считаются неправильными.)
- 3. Когда ученик пропустил слово, произнесите слово для ученика и попросите ученика повторить это слово.Затем скажите: «Какое слово?» и попросите ученика повторить слово еще раз. Поместите карту с пропущенным словом внизу колоды.
- 4. Ошибочные слова в колоде отображаются до тех пор, пока все не будут прочитаны правильно. Затем все карточки со словами собираются вместе, перетасовываются и снова предъявляются ученику. Упражнение продолжается до тех пор, пока не истечет время или пока ученик не пройдёт через колоду без ошибок на двух последовательных картах.
(Дженкинс и Ларсон, 1979)
Ссылки
- Харинг, Н.Г., Ловитт, Т.К., Итон, доктор медицины, и Хансен, К. (1978). Четвертый Р: Исследования в классе. Колумбус, Огайо: Издательство Чарльза Э. Меррилла.
- Дженкинс, Дж. И Ларсен, Д. (1979). Оценка процедур исправления ошибок при устном чтении. Журнал специального образования, 13, 145-156.
- Сингх, Н. (1990). Влияние двух процедур исправления ошибок на ошибки устного чтения: предложение слов по сравнению с повторением предложения. Модификация поведения, 14, 188-199.
Подсказки Джима
Коррекция парных ошибок с помощью вмешательств на беглость чтения. Учащимся, которые только учатся читать или у которых задерживаются навыки чтения, часто полезно, чтобы более опытный читатель слушал их чтение и немедленно исправлял любые ошибки чтения.