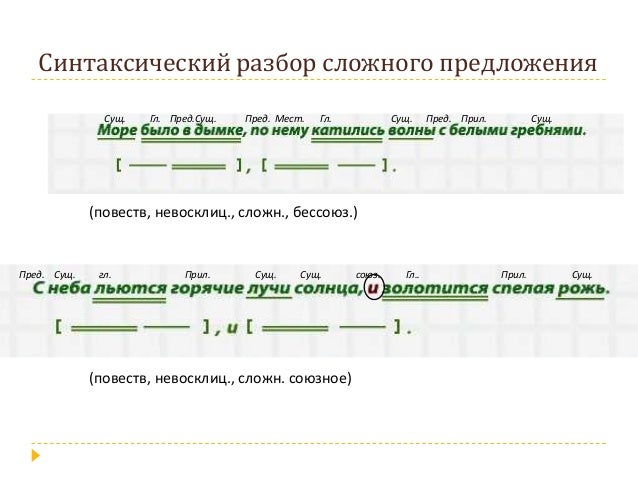
Алгоритм синтаксического разбора простого предложения
Главная / Начальные классы / Разное
Скачать
27.5 КБ, 595416.doc Автор: Глущенко Лариса Владимировна, 30 Мар 2015
Памятка, помогающая научить ребенка правильно производить разбор простых предложений, находить главные и второстепенные члены предложения, чертить схемы предложений такого вида.
Автор: Глущенко Лариса Владимировна
Похожие материалы
| Тип | Название материала | Автор | Опубликован |
|---|---|---|---|
| документ | Алгоритм синтаксического разбора простого предложения | Глущенко Лариса Владимировна | 30 Мар 2015 |
| аудио | Образец устного синтаксического разбора простого предложения | Анисимова Наталья Петровна | 31 Мар 2015 |
| документ | порядок синтаксического разбора простого предложения | Глемба Наталья Александровна | 1 Апр 2015 |
| документ | Порядок синтаксического разбора простого и сложного предложения. | Волкова Ольга Васильевна | 7 Дек 2015 |
| презентация | Урок -презентация русского языка в 5 классе на тему «Порядок синтаксического разбора простого предложения» | Невская Татьяна Петровна | 20 Мар 2015 |
| документ | Планы синтаксического разбора предложений (простого и сложного) | Грачева Наталья Александровна | 20 Мар 2015 |
| документ | Полная схема синтаксического разбора предложения | Трусова Валентина Валерьевна | 19 Мар 2016 |
| презентация | презентация синтаксического разбора предложения в 4 классе | Любовец Светлана Михайловна | 30 Янв 2016 |
| презентация | Интерактивный плакат по русскому языку «Общая схема синтаксического разбора предложения» | Хворова Ольга Владимировна | 20 Мар 2015 |
| документ | алгоритм разбора предложения. | Урываева Ольга Анатольевна | 31 Мар 2015 |
| документ | Чупакова Ольга Николаевна | 1 Апр 2015 | |
| документ | Порядок морфологического и синтаксического разбора по русскому языку | Егорова Юлия Сергеевна | 30 Апр 2015 |
| разное | Памятка разбора предложения | Нечепуренко Наталия Владимировна | |
| документ | Алгоритм разбора слова по составу | Ерохина Любовь Алексеевна | 20 Мар 2015 |
| документ | Алгоритм разбора слов по составу | Брянская Елена Ивановна | 30 Мар 2015 |
| документ | Алгоритм морфемного разбора | Плескач Елена Николаевна | 31 Мар 2015 |
| документ | Алгоритм звуко-буквенного разбора слов | Верхотурова Наталья Павловна | 31 Мар 2015 |
| документ | Алгоритм грамматического разбора слова по составу. | Каральева Агжан Мардановна | 1 Апр 2015 |
| документ | Алгоритм фонетического разбора слова | Каральева Агжан Мардановна | 1 Апр 2015 |
| документ | Алгоритм звуко-буквенного разбора слова | Глущенко Лариса Владимировна | 6 Ноя 2015 |
| документ | «Синтаксический разбор простого предложения» 5 класс | Хайруллина Зульфиря Вализановна | 20 Мар 2015 |
| презентация, документ | Пунктуация простого осложненного предложения. 11 класс 11 класс | Бацина Елена Александровна | 20 Мар 2015 |
| презентация | Синтаксический разбор простого предложения. | Воробьева Марина Отаровна | 20 Мар 2015 |
| документ | Синтаксический разбор простого предложения | Абдуллина Эльвира Дамировна | 20 Мар 2015 |
| документ | Шпаргалка ПО СИНТАКСИСУ ПРОСТОГО ПРЕДЛОЖЕНИЯ | Абдуллина Эльвира Дамировна | 20 Мар 2015 |
| презентация | синтаксический разбор простого предложения | Рыхлик Нина Николаевна | 1 Апр 2015 |
| документ | Синтаксический разбор простого предложения | Чёрная Наталья Викторовна | 6 Апр 2015 |
| документ | Разбор простого предложения | Малышева Ольга Муратовна | 4 Апр 2015 |
| презентация, документ | Пунктуация простого осложнённого предложения | Маскаева Татьяна Васильевна | 1 Апр 2015 |
| документ | «Повторение простого и сложного предложения» | Мугтазирова Альфия Азатовна | 20 Ноя 2015 |
| документ | Разбор простого предложения | Дербышева Нина Николаевна | 8 Сен 2015 |
| презентация, документ | Синтаксический разбор простого предложения | Валентина Станиславовна Шаламбар | 17 Янв 2016 |
| документ | Синтаксический разбор простого предложения. | Иванова Ольга Валериевна | 24 Янв 2016 |
| КСП в 5 классе «Синтаксический разбор простого предложения» | Ососкова Анастасия Игоревна | 13 Дек 2016 | |
| документ | Памятка разбора предложения. | Сидненко Татьяна Николаевна | 1 Апр 2015 |
| документ | Предложения для грамматического разбора, 3 класс | Письменная Валентина Андреевна | 1 Апр 2015 |
| документ | Порядок разбора предложения | Полякова Елена Григорьевна | 9 Мар 2016 |
| документ | Тестовые задания по русскому языку для 7, 8 класса. Тестовые материалы по литературе 6 класс по учебнику «Год после детства» авторов Р.Н Бунеева и Е.В Бунеевой. Набор предложений для синтаксического разбора 5 класс. Тестовые материалы по литературе 6 класс по учебнику «Год после детства» авторов Р.Н Бунеева и Е.В Бунеевой. Набор предложений для синтаксического разбора 5 класс. | Бурдакова Татьяна Владимировна | 20 Мар 2015 |
| документ | Урок русского языка в 5 классе «ВТОРОСТЕПЕННЫЕ ЧЛЕНЫ ПРЕДЛОЖЕНИЯ (ОБОБЩЕНИЕ). РАЗБОР ПРОСТОГО ПРЕДЛОЖЕНИЯ» | Острая Татьяна Владимировна | 20 Мар 2015 |
| разное | Роль союза И для связи членов простого предложения и частей сложного союзного предложения | Федосеева Ирина Викторовна | 17 Янв 2016 |
Полный синтаксический разбор предложения — образец от эксперта и подробнейшая инструкция
Синтаксический анализ вызывает у новичка в этом вопросе большие трудности. Особенно пугает длинное предложение, которое имеет множество членов, предикативных частей. На деле выполнять решение не так страшно, и русский язык предельно логичен, как и его синтаксис. Из этой статьи вы узнаете о том, что такое полный синтаксический разбор предложения – образец анализа приведен подробно, в деталях.
Особенно пугает длинное предложение, которое имеет множество членов, предикативных частей. На деле выполнять решение не так страшно, и русский язык предельно логичен, как и его синтаксис. Из этой статьи вы узнаете о том, что такое полный синтаксический разбор предложения – образец анализа приведен подробно, в деталях.
Содержание
- Для чего нужен синтаксический анализ
- Типы простого предложения
- Типы сложного предложения
- Как составить схему предложения
- Образец простого разбора
- Образец сложного разбора
- 5 лучших онлайн сервисов
- Проблемы с синтаксическим разбором предложений
- Выводы
Для чего нужен синтаксический анализ
Синтаксический анализ – это выделение членов предложения по их функциональному значению и описание высказывания исходя из его целевых, эмоциональных, структурных особенностей.
Иногда его называют пунктуационным разбором. Такой анализ более глобален, чем орфографический, морфологический или фонетический.
Научившись самостоятельно делать синтаксический анализ на примере, можно разобраться в структуре высказывания, принципах его построения. Синтаксис и пунктуация взаимосвязаны, поэтому определение схемы дает знания о том, как расставлять знаки препинания.
Таблица или образец синтаксического разбора будут помогать как ребенку в начальной школе, так и студенту лингвистической специальности, изучающему русский язык.
Типы простого предложения
Простое предложение – это высказывание, где есть одно подлежащее и одно сказуемое. Также возможен вариант, когда есть только подлежащее или только сказуемое.
По цели бывают:
- повествовательными – автор делится информацией, есть точка в конце;
Катя решила сделать гимнастику.
- вопросительными – автор хочет узнать определенную информацию, есть вопрос в конце;
Когда уже наступит лето?
- побудительные – автор побуждает сделать что-либо, восклицательный знак в конце.

Не сорите в общественном месте!
Побудительные высказывания часто имеют лексические маркеры, которые дают подсказку: давай, будем, сделай, идемте и т.п.
Классификация по эмоциональной окраске включает в себя:
- восклицательные – есть восклицательный знак в конце;
Петя, почему ты не помыл руки?!
- невосклицательные – нет восклицательного знака в конце.
На дворе снежно и солнечно.
По наличию главных членов простые предложения принимают такой вид:
- односоставные – если есть подлежащее, но нет сказуемого, или наоборот;
В городе весна.
В столице пахнет осенью.
- двусоставные – есть и подлежащее, и сказуемое.
Зима настала в городе
Когда нет одного из главных членов:
- назывные – только подлежащее;
Здесь глушь.

- определенно-личные – только сказуемое, которое стоит в 1-м или 2-м лице;
Люблю кататься на коньках.
- неопределенно-личное – сказуемое стоит во множественном числе и 3-м лице;
К вам пришли.
- обобщенно-личное – грамматическая форма сказуемого не важна, важно только значение обобщенности и то, что высказывание можно отнести к любому человеку;
Работаешь, работаешь – и без результата.
- безличное – сказуемое может быть наречием, а также страдательным причастием прошедшего времени или безличным глаголом.
Мне нужно выйти. Ему не спится.
Обобщенно-личный тип включает прежде всего пословицы, поговорки, фразеологизмы и другие устойчивые сочетания.
По наличию второстепенных членов высказывания делятся на:
- нераспространенные – есть только грамматическая основа;
Корабль плывет.
- распространенные – есть другие члены предложения, кроме грамматической основы: обстоятельство, или дополнение, или определение, или все вместе.
Корабль величественно плывет по волнам.
По критерию полноты выражения предложение может быть:
- полным – все члены прописаны, нет недоговоренности;
Мое жилье располагается здесь.
- неполным – определенные члены могут подразумеваться, нередко на их месте стоит тире.
А мое жилье – здесь.
Учитывая все критерии, по которым делятся предложения, и их характеристики, можно сделать подробный синтаксический анализ по плану.
Типы сложного предложения
Сложное – это высказывание, в котором при идеальном раскладе есть два подлежащих и два сказуемых. Но иногда случается, что есть только два сказуемых или только два подлежащих, одно сказуемое и два подлежащих и т.п.
В сложном предложении с несколькими придаточными частями можно найти даже 3 или 4 грамматических основы, а не только 2.

Сложные высказывания делятся по цели и эмоциональной окраске так же, как и простые.
При определении типа сложного предложения нужно смотреть на наличие союза:
- союзное – союз есть;
Если бы на Земле не было воды, здесь бы не зародилась жизнь.
- бессоюзное – союз отсутствует, может стоять запятая или даже двоеточие;
Ярик не пошел в школу и остался дома: он болел.
В зависимости от союза высказывания бывают:
- сложносочиненные – союз сочинительный: сюда входят соединительные, противительные и разделительные;
Аня хотела хорошую оценку, но она не сделала домашнее задание.
- сложноподчиненные – союз подчинительный: все остальные союзные группы относятся к этому виду.
Аня должна была сделать домашнее задание, чтобы учитель поставил ей хорошую оценку.
Необходимо указывать, какой союз соединяет предикативные части высказывания; в бессоюзных предложениях это интонация.

После указания типа придаточной каждая из частей разбирается как простое предложение. Порядок синтаксического разбора такой же, но алгоритм начинается с критерия односоставности/двусоставности.
Как составить схему предложения
Рисовать схему нужно после выполнения самого синтаксического разбора. Произведите сперва обобщающий пунктационный разбор, иначе она рискует быть неполной или неверной.
Предлагаем составление схемы по следующей последовательности:
- рисуем скобки – в простом и сложносочиненном высказывании всегда нужны квадратные скобки, т.к. оно не имеет зависимых частей, а в сложноподчиненном –квадратными обозначается главная часть, а круглыми – зависимая;
- делаем графическое отображение предложения внутри, отмечая только грамматическую основу прямыми линиями в логическом порядке, никаких пунктирных или волнистых подчеркиваний.
- если есть союз или союзное слово, оно пишется буквами, а сверху подписывается с. или с.
 с.
с. - если сложноподчиненное, нужно нарисовать стрелку от главной части и подписать сверху вопрос к придаточной, на который она отвечает.
Например, схематический анализ сложноподчиненного предложения с разными видами связи выглядит так:
Я не хотел никого обидеть, но Саша надулся и сказал, что теперь он не будет со мной общаться.
[– =], но [– = и =], (что…).
Грамматическую основу рисуют только в главных частях, а союз в придаточной находится только внутри скобок, в отличие от независимых частей.
Образец простого разбора
Высшее общество всегда казалось ей неестественным, лживым и лицемерным.
Повествовательное, невосклицательное, простое, двусоставное, распространенное, полное.
Грамматическая основа: подлежащее – общество, сказуемое – казалось неестественным, лживым, лицемерным. Второстепенные члены: высшее – определение, ей – дополнение. Осложнено однородными составными глагольными сказуемыми.
Осложнено однородными составными глагольными сказуемыми.
Образец сложного разбора
Артур, уберись в своей комнате до прихода гостей, иначе я тебя накажу.
Побудительное, невосклицательное, сложносочиненное, состоит из двух предикативных частей, средство связи – сочинительный союз «иначе».
Первая часть: односоставное, определенно-личное, распространенное, полное. Сказуемое – уберись. В своей комнате до прихода гостей – обстоятельство. Осложнено обращением.
Вторая часть: двусоставное, распространенное, полное. Подлежащее – я, сказуемое – накажу. Тебя – дополнение. Ничем не осложнено.
5 лучших онлайн сервисов
Синтаксический разбор предложения и текста сегодня можно выполнить онлайн и бесплатно.
ТОП-5 сервисов для этого:
- ProgaOnline – делает подчеркивания, определяет не только части речи, но и их формы: падеж, число, лицо и др.;
- Rustxt – яркий понятный дизайн, предоставляет довольно подробный синтаксический анализ;
- Seosin – может выполнять синтаксический разбор не только словосочетание или предложение, но и текст, подчеркивает все члены, делает морфологический анализ;
- GoldLit – неограниченное количество символов, есть анализы художественной литературы, но выдает только полный анализ части речи;
- Школьный помощник – поможет только со справочной информацией по теме, есть схемы анализа и упражнения.

Необходимо помнить, что анализ, который выполняется любой программой, может содержать мелкие неточности.
Проблемы с синтаксическим разбором предложений
Самой распространенной проблемой для школьника становится разделение частей речи от их функций в высказывании. Отсюда вытекает неумение правильно подчеркнуть члены.
Важно помнить: существительное либо местоимение может быть как дополнением, так и подлежащим, для имени прилагательного определение не приговор, числительные могут выступать в любой функции, а предлоги зависимы и закреплены за другими членами.
Побудительные предложения иногда заканчиваются точкой, а повествовательные – восклицательным знаком. Чтобы не запутаться, нужно обратить внимание на семантический аспект (что оно означает), а не только на знаки препинания.
Возникают проблемы и с тем, какими членами может быть осложнено предложение.
Высказывание часто осложняется:
- вводными конструкциями;
- деепричастием с зависимыми словами;
- причастным оборотом;
- сравнением и другими обособленными оборотами;
- обращением;
- приложением, т.
 е. определением в форме существительного;
е. определением в форме существительного; - однородными членами.
Выводы
В этом материале мы рассмотрели, как сделать синтаксический анализ (разбор) простых и сложных предложений, разобрали конкретные примеры письменного анализа, возможные трудности. С использованием такой пошаговой инструкции и памяткой проанализировать высказывание сможет даже новичок.
Синтаксический анализ / разбор групп с использованием алгоритма CYK в НЛП | от Мехул Гупта | Data Science в вашем кармане
Переходя от POS Tagged в моем последнем посте, на этот раз я буду изучать синтаксический анализ избирательного округа.
Разбор означает разложение предложения на составные части. Эти компоненты могут состоять из слова или группы слов.
Зачем нужны эти компоненты?
Нравится Маркировка POS уже дает нам много информации, как мы видели в последнем посте. Как нам поможет деление предложения на более крупные блоки?
Сначала вам понадобятся уроки английского!!
Вы слышали о словосочетаниях с существительными и глаголами ? Проверьте несколько примеров ниже:
- Красивый парень (Именительное словосочетание)
- Синий зонт (Именительное словосочетание)
- ….
 .пишет (Глагольное словосочетание)
.пишет (Глагольное словосочетание) - …..не может есть (Глагольное словосочетание)
Примечание → Существительное: группа слов, играющая роль существительного в предложении. Точно так же глагольная фраза представляет собой группу слов, действующих как глагол в предложении.
Когда мы проходили маркировку POS, мы пришли к пониманию одной вещи!! Используя его, мы можем генерировать POS-теги, соответствующие каждому слову. Но вносит ли это что-то, если мы посмотрим на более широкую картину? Он ничего не вносит, чтобы модель машинного обучения могла получить значение предложения. Значение любого предложения может быть получено только тогда, когда мы знаем, как эти слова сочетаются друг с другом в предложении .
Например, используя теги POS, мы могли бы получить следующий результат для
«синий зонт»:
«The»: определитель, «синий»: прилагательное, «зонт»: существительное
Но нигде не упоминается «синий» используется для «зонтик». Следовательно, нам нужна какая-то группировка, чтобы восстановить связь между словами предложения.
Следовательно, нам нужна какая-то группировка, чтобы восстановить связь между словами предложения.
Следовательно, синтаксический анализ важен.
Теперь вопрос,
Как это можно сделать?
Синтаксический анализ может быть выполнен с использованием 3 методов:
- Синтаксический анализ : Использование правил для разделения предложения на подфразы. Для предложения «Джон видит Билла» это будет выглядеть примерно так:
Древовидная структура, показанная выше, известна как дерево синтаксического анализа.
Дерево синтаксического анализа преобразует предложение в дерево, листья которого будут содержать POS-теги (соответствующие словам в предложении), но остальная часть дерева подскажет вам, как именно эти слова соединяются вместе, чтобы составить общее приговор.
Например, прилагательное и существительное могут быть объединены в «Фразу существительного» (синий зонт), которая может в сочетании с другим прилагательным образовать другую фразу существительного (например, порванный синий зонт)
2 . Анализ зависимостей : он направлен на то, чтобы разбить предложение в зависимости от отношения между словами, а не от любого предопределенного набора правил. То же предложение « Джон видит Билла » имеет следующий анализ зависимостей:
Анализ зависимостей : он направлен на то, чтобы разбить предложение в зависимости от отношения между словами, а не от любого предопределенного набора правил. То же предложение « Джон видит Билла » имеет следующий анализ зависимостей:
3. Семантический анализ : Самый крутой из всех!! оно направлено на преобразование предложения в логическое, формальное представление . Вы можете воспринимать это так, как если бы я получил предложение
«Сколько ранов забил Дхони в матче?», которое можно преобразовать в SQL-запрос (или любое другое формальное представление), например, SELECT работает из MATCH, где player=’DHONI’ ; (это просто пример формального представления, могут быть и другие формы)
Прежде чем двигаться дальше, мы должны понять, что такое Context-Free Grammar :
Он состоит из набора правил (называемых продукцией), каждое из которых выражает способы группировки и упорядочения символов языка, а также лексикона (словаря) слов и символов.
Чертовски запутался?
Примеры всегда помогут!! Однако изучите грамматические термины, упомянутые ниже.
В CFG (контекстно-свободная грамматика), предположим, нам даны следующие правила/продукции:
- NP (именная группа) →Det (Определитель) Номинал
- NP →Существительное собственное
- Именное → Существительное | Номинальное существительное
- Det → ‘a’
- Существительное → ‘полет’
…… И многие другие
Здесь термины до слева от → могут составить термины справа, т. е. если мы встретим Noun_Phrase ( NP), оно может составлять «Det», за которым следует «Номинальное» (правило 1) или «Имя собственное» (правило 2).
Исследуйте здесь для лучшего понимания.
Точно так же Det — ‘a’ утверждает, что Det может составлять ‘a’ (слово/символ. Их можно рассматривать как наименьшие единицы, которые не могут быть заменены каким-либо термином, т. е. они никогда не могут находиться слева от → ). У нас может быть два типа терминов в CFG.
е. они никогда не могут находиться слева от → ). У нас может быть два типа терминов в CFG.
- Терминал : Термины, которые нельзя заменить («a», «рейс» в приведенном выше примере. Они всегда занимают конечную позицию в дереве синтаксического анализа. Как только они встречаются, они не могут составлять ничего другого. . Можно рассматривать как константы)
- Нетерминальные: Термины, которые могут быть заменены другими терминами (NP, Nominal в приведенном выше примере. Они никогда не могут находиться на листе дерева синтаксического анализа. -клеммы или терминалы)
Ниже перечислены компоненты CFG:
Здесь β просто представляет все термины (объединение терминальных и нетерминальных элементов) в CFG. S — начальный символ дерева синтаксического анализа.
Прежде чем перейти к созданию дерева анализа с помощью CFG, мы должны знать, как генерируются эти правила. Несмотря на то, что для создания CFG не используется какой-либо существенный алгоритм, в основном они извлекаются с использованием TreeBank с некоторыми модификациями, если это необходимо.
A TreeBank представляет собой корпус, в котором все предложения синтаксически аннотированы т. е. каждое предложение имеет соответствующее дерево разбора. Следует отметить, что эти корпуса аннотированы человеком (все деревья синтаксического анализа создаются либо полностью, либо частично путем ручной маркировки). В качестве примера можно рассмотреть PennTreeBank.
- Преобразование CFG в нормальную форму Хомского .
CFG находится в CNF, если все продукции/правила соответствуют следующим критериям:
A → B|C ( Нетерминал, порождающий два нетерминала )
A → ‘ a’ ( Нетерминал, генерирующий терминал )
S → ε (Начальный символ, генерирующий 90 02 ε относится к нулевому производству i.0e пусто) одно из продукционных правил гласит: A →A |B| C где A, B, C. не являются терминалами
Это может быть введено в CNF с помощью A → A|X, X → B|C, где мы создали новое правило
X → B|C.
Примечание: «|» представляет собой «или»
Для лучшего понимания см. пример здесь: Пример CNF
Примечание. Прежде чем двигаться дальше, необходимо иметь четкое представление о CFG и CNF. :
Забронируйте рейс через Хьюстон
Давайте вместе с CNF добавим наши грамматические правила
Помните, что эта таблица не включает некоторые очень очевидные правила, такие как Глагол → Книга, Имя собственное → Хьюстон, Дет → The, Preprostion →Through, существительное →Flight и т. д. Поэтому, если вы чувствуете, что какой-либо термин отсутствует на рисунках ниже, предположим, что он был принят во внимание.
Примечание. Все правила, упомянутые ниже, взяты из таблицы CNF (справа), а не из исходной таблицы грамматики
Нам нужно настроить матрицу, как показано ниже, с размером N X N (N = количество слов ) с каждым столбцом, представляющим слова предложения в той же последовательности.
___________Book______The_______Flight____Through___Houston
Черные стрелки показывают нам направление, откуда мы начнем заполнять эту матрицу.
Окончательный результат будет выглядеть так:
- Начиная с [4,5], т.е. «Хьюстон», глядя на правила, его можно получить, используя NP (10-е правило, CNF) и имя собственное (существительное собственное → Хьюстон).
2. Основные вещи начинаются, когда мы движемся на шаг вверх, т.е. к [3,4], представляющему «сквозь». Его можно получить с помощью Prep(Prep/Preposition →Through).
3. Надо помнить, что по мере того, как мы переходим в правую часть ряда, нам нужно в той же последовательности присоединить следующие слова к уже заполненным словам в левой части и найти правила, производящие эта группа слов в целом.
4. Следовательно, в [3,5] нам нужно выяснить правил, генерирующих «через Хьюстон», а не только «Хьюстон» . Теперь для этого нам нужна помощь от [3,4], представляющего «сквозь», и [4,5], представляющего «Хьюстон».
Мы будем стремиться найти тегов @ [3,4] (Prep) X тегов @ [4,5] (NP, имя собственное) . Следовательно, это приводит к образованию пар «Prep Np» и «Prep Proper-Noun». Теперь, если какие-либо из них могут быть получены из приведенных выше произведений, заполните эти правила в [3,5]. Если вы посмотрите, Prep NP может быть сгенерирован с использованием 21-го правила, то есть PP → Prep NP. Отсюда [3,5]=PP
5. Переход к [2,3], «полет» можно получить с помощью 12-го правила (имя →полет) и существительное →полет. Переходя к [2,4], мы попытаемся создать «полет через », для чего мы найдем пары тегов, полученные путем скрещивания [2,3] (существительное, номинальное) с [3,4] (приготовительное). Следовательно, найдите правило, производящее «Подготовку именных» или «Подготовку существительных». Правило отсутствует!!! оставьте это поле пустым.
6. Переход к [2,5]. Нам нужно выяснить «рейс через Хьюстон».
Здесь мы попытаемся определить группы тегов, образованные [2,3](полет) x [3,5](через Хьюстон) или [2,4](полет) x [4,5](Хьюстон). Надо понимать, что мы пытаемся создать текущий сегмент предложения, используя ранее нарисованные сегменты предложения . Следовательно, « рейс через Хьюстон» может быть разбит как «рейс через» + «Хьюстон» или «рейс» + «через Хьюстон» . Поскольку «прохождение через» не может быть получено и, следовательно, пусто, мы можем легко отказаться от этой сегментации. Следовательно, [2,3]x[3,5] дает нам «Номинальный PP» и «Существительное PP». Правило 14 гласит: «Номинальный → номинальный PP». и, следовательно, [2,5]=номинальное
7. Учитывая [1,5]= ‘ полет через Хьюстон’ можно разбить как
‘+’рейс через Хьюстон'([1,2] x [2,5])
‘рейс’ + ‘через Хьюстон’ ([1,3]x[3 ,5])
‘перелет через’ +’Хьюстон’ ([1,4]x[4,5])
Теперь создайте соответствующие пары тегов и определите правила создания этих пар.
Заполните ячейку всеми правилами, производящими любую из этих пар.
Аналогично попробуйте заполнить всю матрицу до [0,0].
Обратите внимание, что ячейки в начале строки заполняются непосредственно с использованием продукции, упомянутой в таблице CNF (ячейки, представляющие отдельные слова, без слов слева)
Ни за что!!
Нам нужно внести это важное изменение.
- Когда мы заполняем приведенную выше матрицу, создайте указатель для каждой ячейки (представляющей нетерминалы), сохраняющей позиции, из которых он был получен. Нетерминалы относятся к тегам POS, в то время как терминалы относятся к словам-предложениям («книга», «эта», «полет», «сквозь», «Хьюстон»). Для позиции [2,5] сохраните «Номинальный PP»
- . Если мы найдем несколько правил, удовлетворяющих парам тегов, нам нужно сохранить вышеуказанные указатели для каждого нетерминала ячейки
- Достигнув [0,0], проследите все нетерминалы в [0,0], используя значения указателя, сохраненные с помощью рекурсии, пока не будут достигнуты все листья (нетерминалы)
- Если [0,0] равно пусто, это означает, что предложение грамматически/синтаксически неверно.
Дерево синтаксического анализа не существует
- Если мы получаем несколько деревьев синтаксического анализа, предложение неоднозначно (из которого можно извлечь множество значений, как показано в приведенном ниже примере)
Рассмотрим предложение:
‘мужчины и женщины всех возрастов’
Здесь у нас может быть два значения.
‘мужчины всех возрастов и (возрастные) женщины’
или
‘мужчины всех возрастов и (без возрастных барьеров, все возрастные группы) женщины’
Следовательно, это предложение может иметь несколько деревьев разбора, соответствующих каждому значению если мы используем алгоритм CYK (как упоминалось выше).
А вот и Вероятностная контекстно-свободная грамматика !!
Существует очень небольшая разница между CFG и PCFG. В PCFG мы доступны с вероятностью, соответствующей каждой продукции. Например, если у нас есть A → BC, в PCFG это будет A → BC( β ), где β — вероятность правила.
Когда наблюдается несколько деревьев синтаксического анализа, с использованием алгоритма Витерби выбирается наиболее заметное дерево.
Не буду вдаваться в подробности!!
Осталась последняя тема. Потерпите еще немного!!
Частичный синтаксический анализ относится к более детализированной сегментации по сравнению с синтаксическим синтаксическим анализом, где сегментация достаточно точная
Рассмотрите возможность распознавания именованных объектов (извлечение именованных объектов, таких как имена людей, названия городов, страны, местоположения и т. д. из предложения).
Зачем мне выполнять такую утомительную задачу (создание дерева синтаксического анализа — трудоемкая вычислительная задача) по созданию дерева синтаксического анализа для всего предложения, когда меня интересует только некоторая информация из предложения ? и, следовательно, в этом случае мы будем выполнять частичный разбор
Приходит роль разбивки!!
Фрагментирование помогает нам в частичном анализе предложения, необходимого для извлечения информации в НЛП (примером извлечения информации является распознавание именованных объектов).
В основном, сегментация предложения на неперекрывающихся фраз, а именно: именная фраза NP (наиболее распространенная), глагольная фраза VP, прилагательная фраза AP и предложная фраза PP . Под непересекающимися я подразумеваю, что ни одно слово не должно быть общим в любых двух сегментах.
Учитывая приведенное ниже предложение:
«Утренний рейс из Денвера прибыл » можно разделить на:
[ NP Утренний рейс] [ PP from] [ NP Den] ver [ NP Den] ver
0170 VP прибыл.]Обратите внимание, что мы стремимся найти менее подробное дерево синтаксического анализа, в котором мы не определяем отношения между «имеется» и «прибыло» в последнем сегменте. Они сегментированы как единое целое.
Пока нет моделей ML?
Мы можем использовать контролируемое обучение для фрагментации!!
Нам нужны обучающие данные. Тем не менее, мы добавим дополнительную информацию помимо тегов, назначенных в приведенном выше примере.
Мы будем производить выходные данные, используя IOB Тегирование , где мы вводим тег для начала (B) и внутри (I) каждого типа фрагмента, а также один для токенов вне (O) любого фрагмента наряду с грамматическими тегами.
Пример ниже объясняет это лучше.
Здесь B_NP представляет собой начало фрагмента, который является именной фразой. Точно так же I_NP представляет, что это слово находится внутри фрагмента (отмеченного самой последней буквой B), который является фразой существительного.
Мы используем модель маркировки последовательностей (обученную на наборе данных), как показано ниже для фрагментации.
Это принимает тег POS, соответствующий каждому слову, и назначает теги IOB после обучения. Следовательно, мы обучаем модель, используя теги POS, для создания тегов IOB.
Не буду вдаваться в подробности!!
Более чем достаточно на день!!
Если вам понравилась эта статья, вам наверняка понравятся и другие:
- Распознавание именованных сущностей с использованием CRF
- Алгоритмы разбора зависимостей
- POS Tagging using HMM & Viterbi algorithm
- Tokenization algorithm in NLP
- Reinforcement Learning Basics (5 parts)
- Starting off with Time-Series (7 parts)
- How чтобы получить первого стажера по науке о данных
- Обнаружение объектов с помощью YOLO (3 части)
- Tensorflow для начинающих (концепции + примеры) (4 части)
- Предварительная обработка временных рядов (с кодами)
- Аналитика данных для начинающих
- Статистика для начинающих (4 части)
1 | Semantic Scholar
- Идентификатор корпуса: 61135912
@inproceedings{Wilcox1983ParsingNL, title={Синтаксический анализ естественного языка}, автор={Л.Э. Уилкокс}, год = {1983} }
- Л. Э. Уилкокс
- Опубликовано в 1983 г.
- Информатика
Людей уже давно интересует возможность использования компьютера для «понимания» естественного языка. Большинство исследователей, пытающихся решить эту проблему, начали свои усилия с попытки заставить компьютер распознавать лежащую в основе синтаксическую форму (дерево синтаксического анализа) предложения. Эта диссертация представляет собой обзор истории синтаксического анализа естественного языка и сравнивает основные методы, которые использовались. Лингвистически описаны две недавние грамматики…
scholarworks.rit.edu
SHOWING 1-10 OF 24 REFERENCES
SORT BYRelevanceMost Influenced PapersRecency
Flexible Parsing
- P. Hayes, G. Mouradian
Computer Science
ACL
- 1980
Описан набор гибких возможностей синтаксического анализа для ограниченного ввода на естественном языке в компьютерную систему с ограниченным доменом, а также разработан и реализован восходящий анализатор сопоставления с образцом для обеспечения этих гибких возможностей.
LINGOL: отчет о проделанной работе
- В. Пратт
Информатика
IJCAI 1975
- 1975
- 1975
Новая фраза не существует, чтобы гарантировать продолжение алгоритма разбора. предложение, увиденное до сих пор, в котором фраза играет роль в некоторой поверхностной структуре этого предложения.
Сетевые грамматики перехода для анализа естественного языка
- W. Woods
Информатика
CACM
- 1970
Описано использование грамматик расширенной переходной сети для анализа предложений естественного языка, а действия по построению структуры, связанные с дугами грамматической сети, обеспечивают мощную избирательность, которая может исключать бессмысленный анализ и использовать семантическую информацию для управления синтаксическим анализом.
Понимание естественного языка
- Виноград Т.
Информатика
- 1972
Компьютерная система для понимания английского языка, содержащая синтаксический анализатор, грамматику распознавания английского языка, программы семантического анализа и общую систему решения проблем, основанную на убеждении, что при моделировании понимания языка должны комплексно работать со всеми аспектами языка — синтаксисом, семантикой и выводом.
Теория синтаксического распознавания естественного языка
- М. Маркус
Информатика
- 1978
Будет показано, что эта гипотеза «детерминизма», исследуемая в контексте грамматики английского языка, приводит к простому механизму — интерпретатору грамматики.
Программа по синтаксическому анализу английских предложений
- H. Dewar, P. Bratley, J. P. Thorne
Linguistic
CACM
- 1969
A Программа, которая, как это создает Syntactes Analys, Analize Analyes Sentrences с Analyes Analyes.
относительно трансформационной грамматики, которая использует только ограниченный словарь английских слов и использует все пути анализа одновременно, обрабатывая предложение слева направо.
Процедурные системные грамматики
- М. МакКорд
Информатика, лингвистика
Междунар. Дж. Ман Мах. Стад.
- 1977
Аргументы для не трансформационной грамматики
- R. Hudson
Linguistics
- 1976
Рисустика A. Hudson Outtrines «Dieprenderified». и предлагает эмпирические причины предпочтения ее любой версии трансформационной грамматики.
Эффективный алгоритм анализа без контекста
- Дж. Эрли
Информатика
CACM
- 1983
превосходить алгоритмы «сверху вниз» и «снизу вверх», изученные Гриффитсом и Петриком.
Формальные языки: истоки и направления
Замечено, что одни и те же важные идеи возникли независимо друг от друга для автоматического анализа и перевода как естественных, так и искусственных языков в XIX веке.




