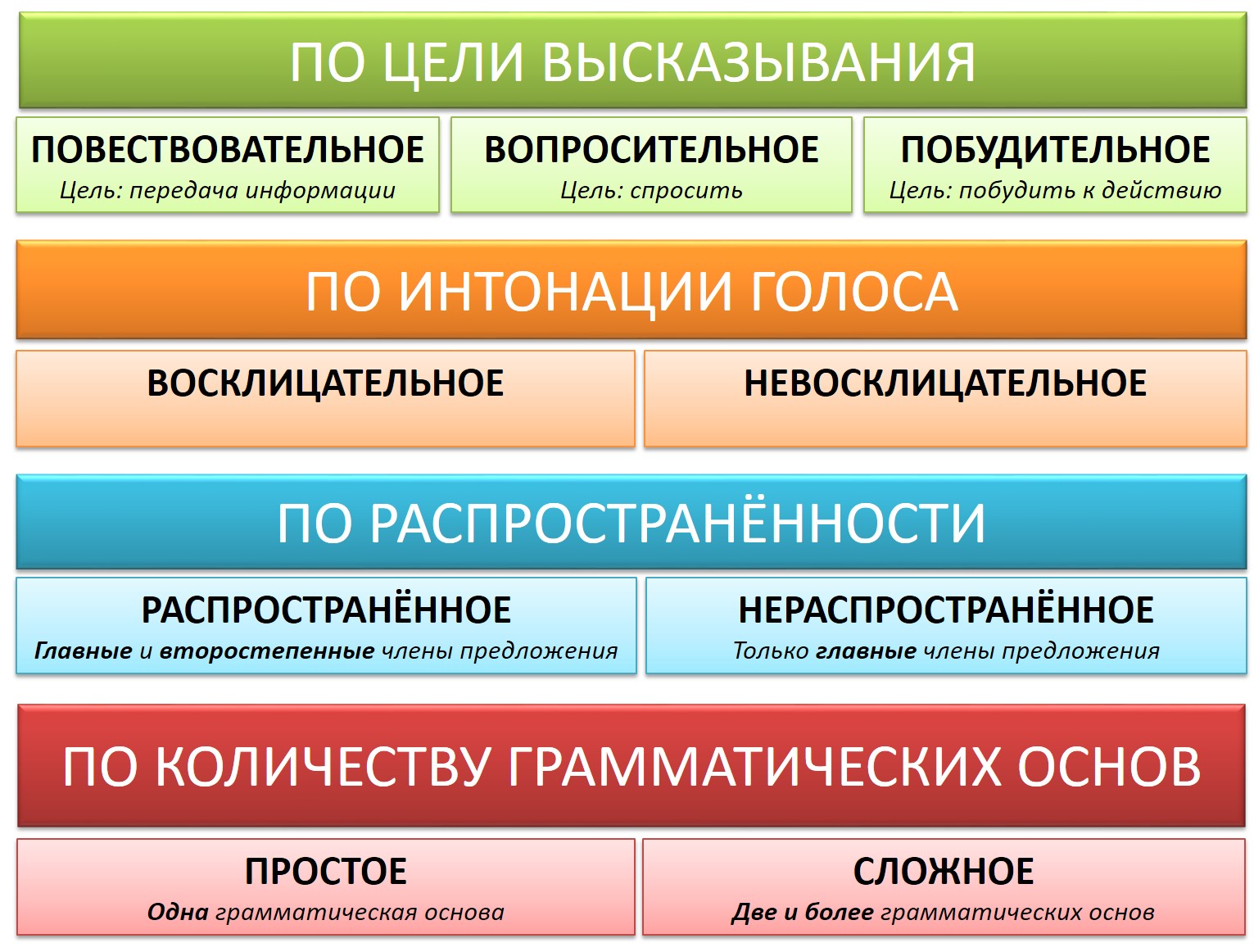
Разбор предложения по цели высказывания
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:
| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложенияПредложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное.
 Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное. - Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
Сказуемое
- Отмечаем, чем является сказуемое – простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое – какой формой глагола;
- составное глагольное – из чего оно состоит;
- составное именное – какая употреблена связка, чем выражается именная часть.

В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Для учащихся начальной школы
Скачать:
| Вложение | Размер |
|---|---|
| razbor_predlozheniy._pamyatka.doc | 32 КБ |
| pamyatki_dlya_urokov_rus.yaz_.fon_.razbor_-_kopiya.doc | 22 КБ |
Предварительный просмотр:
1. По цели высказывания: повествовательное, вопросительное, побудительное.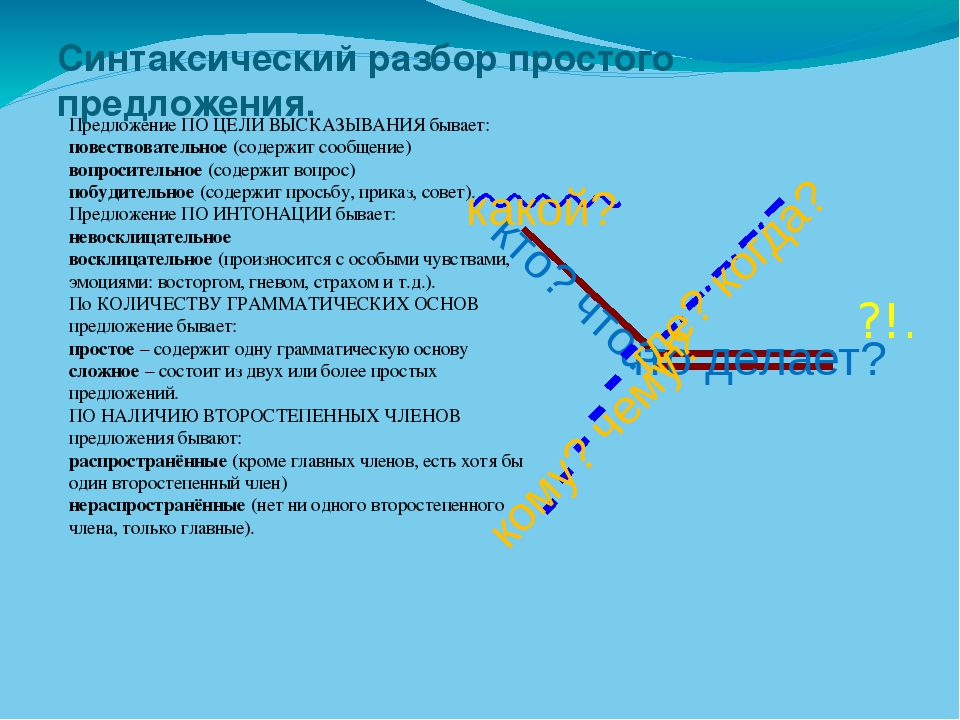
2. По интонации : восклицательное, невосклицательное.
3. Основа предложения: главные члены предложения – подлежащее и сказуемое .
4. Наличие второстепенных предложений: распространённое, не распространённое.
5. По структуре: простое, сложное
6. Установить связь членов предложений, поставить вопросы к второстепенным членам предложения и указать её стрелочками.
Наступила долгожданная весна. Повеств., невоскл., распр., прост.
Второстепенные члены предложения:
- дополнение (кого? чего? кому? чему? кем? чем? о ком? о чем?) ——–
- определение (какой? какая? какое? какие?) ﹏﹏﹏﹏
- обстоятельство (где? куда? откуда? как? когда?) ﹎ . ﹎ . ﹎ . ﹎
1. По цели высказывания: повествовательное, вопросительное, побудительное.
2. По интонации : восклицательное, невосклицательное.
3. Основа предложения: главные члены предложения – подлежащее и сказуемое .
4. Наличие второстепенных предложений: распространённое, не распространённое.
5. По структуре: простое, сложное
6. Установить связь членов предложений, поставить вопросы к второстепенным членам предложения и указать её стрелочками.
Наступила долгожданная весна. Повеств., невоскл., распр., прост.
Второстепенные члены предложения:
- дополнение (кого? чего? кому? чему? кем? чем? о ком? о чем?) ——–
- определение (какой? какая? какое? какие?) ﹏﹏﹏﹏
- обстоятельство (где? куда? откуда? как? когда?) ﹎ . ﹎ . ﹎ . ﹎
1. По цели высказывания: повествовательное, вопросительное, побудительное.
2. По интонации : восклицательное, невосклицательное.
3. Основа предложения: главные члены предложения – подлежащее и сказуемое .
4. Наличие второстепенных предложений: распространённое, не распространённое.
5. По структуре: простое, сложное
6. Установить связь членов предложений, поставить вопросы к второстепенным членам предложения и указать её стрелочками.
Наступила долгожданная весна. Повеств., невоскл., распр., прост.
Повеств., невоскл., распр., прост.
Второстепенные члены предложения:
- дополнение (кого? чего? кому? чему? кем? чем? о ком? о чем?) ——–
- определение (какой? какая? какое? какие?) ﹏﹏﹏﹏
- обстоятельство (где? куда? откуда? как? когда?) ﹎ . ﹎ . ﹎ . ﹎
1. По цели высказывания: повествовательное, вопросительное, побудительное.
2. По интонации : восклицательное, невосклицательное.
3. Основа предложения: главные члены предложения – подлежащее и сказуемое .
4. Наличие второстепенных предложений: распространённое, не распространённое.
5. По структуре: простое, сложное
6. Установить связь членов предложений, поставить вопросы к второстепенным членам предложения и указать её стрелочками.
Наступила долгожданная весна. Повеств., невоскл., распр., прост.
Второстепенные члены предложения:
- дополнение (кого? чего? кому? чему? кем? чем? о ком? о чем?) ——–
- определение (какой? какая? какое? какие?) ﹏﹏﹏﹏
- обстоятельство (где? куда? откуда? как? когда?) ﹎ .
 ﹎ . ﹎ . ﹎
﹎ . ﹎ . ﹎
Предварительный просмотр:
Фонетический разбор слова.
а о э ы у | м л н р й б д з ж в г
я ё е и ю | п т с ш ф к ц ч щ х ъь
О | ле’нь – 2 слога, 2 гл., 2 согл.,
л [л’] – согл., зв., непарн., мягк.
н [н’] – согл., зв., непарн., мягк.
По теме: методические разработки, презентации и конспекты
Как правильно и поэтапно объяснить ученикам полный синтаксический разбор предложения? Для этого предлагаю вам разработанную памятку, с помощью которой ребята смогут научиться делать синтаксический раз.
В памятке представлен образец письменного разбора предложения.
Памятка по разбору предложения.
В данной памятки дана классификация предложений по интонации , по видам высказывания.
В помощь ученику и родителю.
Полный разбор предложения по членам предложения, частям речи, с характеристикой является итогом работы с предложением в начальной школе и доступен ученикам 4 класса при условии освоенного умения.
Каждое предложение произносится или пишется с определенной целью – люди рассказывают что-то, спрашивают, советуют или просят что-то сделать. Цель высказывания – это сообщение, вопрос или просьба.
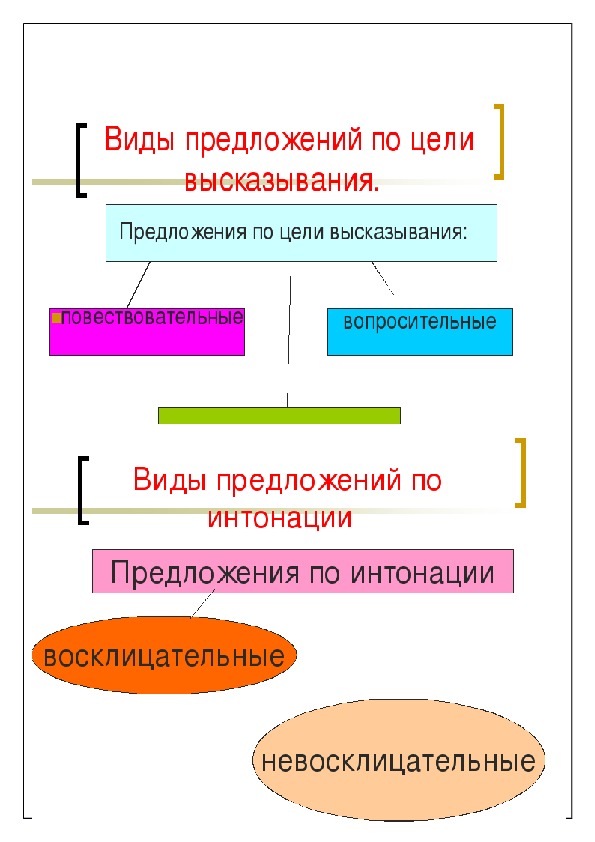
По цели высказывания предложения делятся на:
- повествовательные
- вопросительные
- побудительные
Повествовательное предложение – это предложение, в котором содержится сообщение о чем-то в виде утверждения или отрицания.
Например: Я очень люблю свежую землянику. Но я не хочу ее собирать.
В конце повествовательного предложения может стоять точка ( . ), восклицательный знак ( ! ) или многоточие ( . ).
Например: Вечереет. Наконец-то вечер! Вот и наступил вечер.
В повествовательном предложении голос говорящего повышается на одном из членов предложения и понижается к концу предложения. Это повествовательная интонация.
Это повествовательная интонация.
Вопросительное предложение – это предложение, в котором о чём-то спрашивают.
Например: Ты сможешь дочитать книгу сегодня?
В конце вопросительного предложения ставится вопросительный знак ( ? ). Когда предложение произносится с очень сильным чувством, в конце могут стоять сразу два знака – вопросительный и восклицательный ( ?! ).
Например: Когда ты сделаешь уроки? Как ты мог сделать это?!
Вопросительное предложение может содержать вопросительное слово или быть сформулировано без него.
Например: Что с тобой происходит? Ты идёшь с нами?
Для интонации вопросительного предложения характерно повышение тона голоса к концу предложения или на вопросительном слове. Это вопросительная интонация. Если вопросительного слова в предложении нет, то выделяется то слово, которое важно в смысловом плане именно в этом предложении.
Побудительное предложение – это предложение, содержащее просьбу, совет, приказ, требование или призыв к действию.
Подай мне книгу, пожалуйста. (просьба)
Позанимайся дополнительно. (совет)
Не отставай! (приказ, требование)
Берегите природу! (призыв)
В конце побудительного предложения ставится точка ( . ) или восклицательный знак ( ! ).
Например: Осторожнее! Включите свет, пожалуйста.
В побудительных предложениях очень часто употребляются обращения.
Например: Мама, налей мне супа, пожалуйста. Антон, отдай мяч!
Побудительное предложение произносится с повышением голоса, напряжённо. Это побудительная интонация.
Предложения, помимо смысловой нагрузки (сообщение, просьбы или вопроса), выражают еще эмоции говорящего или могут нейтрально передавать информацию. Это показывает эмоциональная окраска предложений.
Поделись с друзьями в социальных сетях:
Онлайн тест: Синтаксический разбор предложения с прямой речью
Прямая речь — это та тема, которая зачастую вызывает у школьников наибольшие затруднения. Причин этому две: во-первых, материал сам по себе довольно сложный и неоднозначный, а во-вторых, ему уделяется не так много времени во времени во время учебного процесса в целом. А между тем это очень важная тема, к которой не стоит относиться с пренебрежением.
Причин этому две: во-первых, материал сам по себе довольно сложный и неоднозначный, а во-вторых, ему уделяется не так много времени во времени во время учебного процесса в целом. А между тем это очень важная тема, к которой не стоит относиться с пренебрежением.
При прохождении предложенного теста важно не только знать, что она собой представляет, но и как с ней работать. В том числе необходимо знать такие вещи, как ее характеристика, какой она бывает. Что делать в том случае, если прямая речь состоит из двух предложений, как обозначать связь между ними. Важно разбираться в такое теме как «цели высказывания», уметь выбрать нужную категорию и правильно проанализировать само предложение, сопоставить прямую речь со словами автора. Оканчивается этот разор составлением схемы, ее тоже нужно уметь правильно нарисовать.
Как уже было сказано выше, это тема очень сложная, и многие в ней путаются. Возможно, конкретно в школьной жизни и при сдаче экзаменов знания по ней не очень сильно пригодятся, однако они важны для дальнейшей жизни. Это базовые правила русского языка, которыми нельзя пренебрегать. К тому же во время прохождения данного теста повторяется не только прямая речь как таковая, но еще и другие важные темы так или иначе связанные с нею, поэтому он может пригодиться многим.
Это базовые правила русского языка, которыми нельзя пренебрегать. К тому же во время прохождения данного теста повторяется не только прямая речь как таковая, но еще и другие важные темы так или иначе связанные с нею, поэтому он может пригодиться многим.
Прийти этот тест могут как школьными, которые проходят заданную тему по учебной программе либо же хотят освежить знания, так и взрослым, которые стремятся наверстать упущенное. В нем всего пять вопросов, которые нацелены на базовые понимания ряда фундаментальных вопросов по теме. Они помогут сориентироваться в материале, лучше понять, чего человек не знает и что ему стоит повторить.
Пройти тест онлайн
Может быть интересно
Ещё никто не оставил комментария, вы будете первым.
Написать комментарий
Спасибо за комментарий, он будет опубликован после проверки
Виды предложения по цели высказывания.
 — Студопедия
— СтудопедияПо цели высказывания различаются повествовательные, вопросительные и побудительные предложения.
Повествовательные предложения –это такие предложения, в которых о чём-то сообщается, повествуется.
Вопросительные предложения – это такие предложения, в которых содержится вопрос.
Побудительные предложения – это такие предложения, в которых есть побуждение чего-либо к действию.
30. Восклицательные предложения –это такие предложения, которые произносятся с особой выразительной интонацией, выражающей сильные чувства.
Невосклицательные предложения – это такие предложения, которые произносятся спокойным тоном, без ярко выраженных чувств.
21. Второстепенные члены предложения –это такие члены предложения, которые поясняют, дополняют главные или другие второстепенные.
Подлежащее – это главный член предложения, который отвечает на вопросы или падежи кто? что?; обозначает предмет речи и выражено существительным или местоимением в И. П.
П.
Схема разбора подлежащего:
по определению
Сказуемое –это главный член предложения, который обозначает то, о чём говорится о предмете речи и отвечает на вопросы что делает предмет? какой предмет?что такое предмет?
Девочка любит брата.
Девочка опрятная.
Девочка – это ребёнок.
Сказуемое выражается глаголом, именем существительным, прилагательным в полной и краткой формах.
Если сказуемое выражено глаголом, то оно обозначается действие предмета, а если сказуемое выражено существительным или прилагательным, то оно обозначает качество предмета.
32. Нераспространённые предложения –это такие предложения, которые состоят только из главных членов.
Распространённые предложения – это такие предложения, в которых кроме главных членов есть второстепенные члены.
Дополнение – это второстепенный член предложения, который отвечает на вопросы косвенных падежей и обозначает предмет или лицо.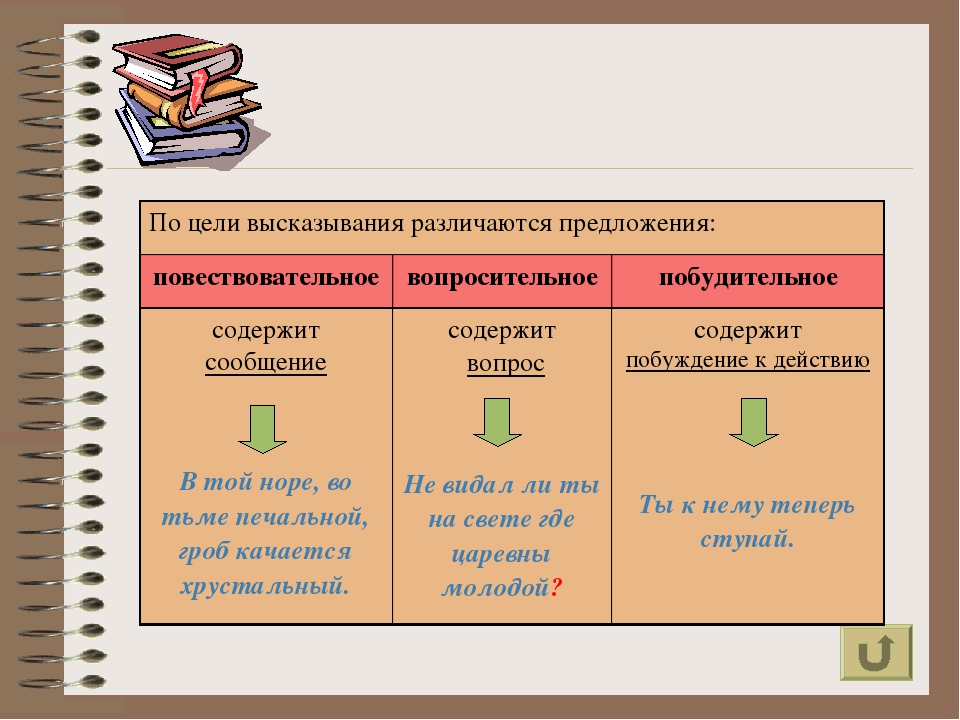 Дополнения обычно выражаются существительными или местоимениями в косвенном падеже.
Дополнения обычно выражаются существительными или местоимениями в косвенном падеже.
Определение – это второстепенный член предложения, который отвечает на вопросы какой? чей? и обозначает признак предмета. Определение обычно выражается прилагательным.
Обстоятельство – это второстепенный член предложения, который отвечает на вопросы где? зачем? куда? откуда? почему? когда? и как? Обстоятельства обозначают место, время и способ действия.
Обстоятельства обычно выражаются наречиями или существительными в косвенных падежах.
Однородные члены предложения –это такие члены предложения, которые отвечают на один и тот же вопрос и относятся к одному и тому же члену предложения.
Ласточки, грачи, дрозды, жаворонки и соловьи осенью улетают в тёплые края.
Однородные члены не зависят друг от друга и произносятся с интонацией перечисления. Однородными членами могут быть и главные, и второстепенные члены предложения.
Колхозница работала на холодном поле, на чёрной земле, на бескрайних русских просторах.
Однородные члены: — обстоятельство
— — подлежащее, — сказуемое,
— — определение, — дополнение.
Порядок ответа по второстепенным членам предложения
Ласточки, грачи, дрозды, жаворонки, соловьи – это однородные члены предложения, так как они относятся к одному и тому же сказуемому, отвечают на один и тот же вопрос (кто?), обозначают предмет речи и выражены именем существительным в И. п.
33. Синтаксическая роль слова – это то, каким членом предложения слово является.
Простое предложение – это такое предложение, в котором только одна грамматическая основа.
Я читаю интересную книгу. (простое)
Сложное предложение– это такое предложение, в котором две или более грамматических основ.
Я читаю книгу, а Наташа делает уроки (сложное).
Синтаксический разбор предложения – это характеристика предложения в целом.
Синтаксический разбор предложения (простого)
Порядок разбора
1. Вид предложения по наличию грамматических основ (простое или сложное).
2. Вид предложения по цели высказывания.
3. Вид предложения по интонации (восклицательное или невосклицательное).
4. Вид предложения по наличию второстепенных членов.
5. Второстепенные члены (если есть).
6. Однородные члены (если есть).
7. Обращения (если есть).
Я иду в кино. (простое, повествоват., невосклиц., распростран., ничем не осложнено)
Птицы и звери готовятся к зиме (простое, повествов., невосклиц., распростр., осложнено однородными членами).
Я, милая мама, хорошо учусь (простое, повествов., невосклиц., распростран., осложнено обращением).
34. Простые и сложные предложения.Знаки препинания в сложном предложении.
Сложное предложение состоит из двух или нескольких простых предложений. Сложное предложение, как и простое, представляет собой единое целое. Предложения, которые входят в его состав, связаны друг с другом по смыслу и интонацией. Основные средства связи простых предложений в составе сложного: 1. Интонация. 2. Союзы.
Предложения, которые входят в его состав, связаны друг с другом по смыслу и интонацией. Основные средства связи простых предложений в составе сложного: 1. Интонация. 2. Союзы.
В русском языке сложные предложения делятся на 3 группы:
1. Сложносочинённые.
2. Сложноподчинённые.
3. Бессоюзные сложные.
Признаки сложносочинённого предложения
1. Простые предложения в составе такого сложного предложения равноправны по смыслу, самостоятельны, они не зависят друг от друга, они легко употребляются друг без друга (одно без другого).
Всю зиму провела ласточка в подземелье, а девочка ухаживала за ней (сложносочинённое предложение).
2. От одного простого предложения в составе такого сложного предложения нельзя поставить вопрос к другому простому предложению.
3. Сочинительные союзы, используемые в сложносочинённом предложении, употребляются и для связи однородных членов предложения в простом предложении. Это союзы а, но, да, и.
Девочка смотрела на улетающую ласточку, и слёзы закапали у неё из глаз (сложносочинённое предложение).
Дюймовочка плакала и жалела ласточку (простое предложение).
а, но, да (=но) – перед ними всегда ставим запятую (если союзы соединяют однородные члены или простые предложения в составе сложного (сложносочинённого).
Перед союзом и в сложносочинённом предложении ставим запятую, если этот союз соединяет два простых предложения в составе сложного.
Признаки сложноподчинённого предложения.
1. В сложноподчинённом предложении есть главное и придаточное (зависимое) предложение.
2. От главного предложения к придаточному можно задать вопрос, так как одно простое предложение в таком сложном предложении подчинено по смыслу другому.
Ласточка рассказала Дюймовочке, что она поранила крыло о терновый куст (сложноподчин. предлож.).
3. Союз или союзное слово находятся в придаточном предложении.
4. Союзы и союзные слова сложноподчинённого предложения никогда не используются при однородных членах предложений.
Союзы и союзные слова, которые чаще всего используются в сложноподчинённых предложениях, — это подчинительные союзы. Перед ними всегда ставим запятую:
…., что…… …., чтобы…. …..,как будто……
…., если… …., как…. …., потому что…..
…., оттого что…. …, где…. …, когда….
…., который…..
5. Вопрос к придаточному предложению ставится от всего главного предложения или от одного слова в главном предложении.
6. Одно и то же придаточное предложение может стоять перед ними после главного предложения.
Если светит солнце, то на улице тепло (сложноподчин. предл.).
На улице тепло, если светит солнце (сложноподчинен. предлож.).
В сложноподчинённом предложении может быть несколько придаточных предложений.
Я живу в доме, который находится на улице Урицкого, где много зелёных насаждений.
Синтаксический разбор / Русский на 5
Синтаксический разбор — это разбор синтаксических единиц: словосочетаний и предложений. Естественно, характеристика словосочетания отличается от характеристики предложения, потому что словосочетание не является самостоятельной синтаксической единицей, как предложение. Оно устроено иначе.
Естественно, характеристика словосочетания отличается от характеристики предложения, потому что словосочетание не является самостоятельной синтаксической единицей, как предложение. Оно устроено иначе.
В разборе простых и сложных предложений много общего: нужно определить тип предложения по цели высказывания и эмоциональной окрашенности, произвести разбор по членам предложения. Но простое предложение имеет лишь одну грамматическую основу, а сложные — более одной. Поэтому для последних важно выявить характер синтаксической связи между частями. То есть схемы разбора простого и сложного предложения имеют важные различия. Приступая к разбору, важно понимать, какие единицы синтаксиса ты разбираешь и что для этого требуется.
Особенности синтаксического разбора
§1. Что такое синтаксический разбор, в чём его специфика
§2. Что нужно знать и уметь делать
§3. Порядок разбора синтаксических единицСоветы. Как приступить к делу
О чём важно подумать перед разбором предложения, что с чем не перепутать, в чём не ошибиться
Примеры и комментарии
Это то, чего не хватает в учебниках.
 Здесь на конкретных образцах показано, как разбирать словосочетания и предложения
Здесь на конкретных образцах показано, как разбирать словосочетания и предложения
§1. Словосочетание
§2. Простое предложение
§3. Сложное предложениеТипичные ошибки
Разберись с типичными ошибками и не повторяй их. Без этого знания будут неполными
§1. Ошибки при определении членов предложения
§2. Ошибки при разборе словосочетания
§3. Ошибки при разборе простого предложения
§4. Ошибки при разборе сложного предложенияПервые шаги. Подготовительные задания.
Учись выполнять отдельные важные операции, простые действия. Это поможет избежать множества проблем.
Темы:
Умение находить словосочетания в предложениях
Умение определять члены предложения
Умение определять границу между частями сложного предложения
Умение определять, как осложнена структура предложенияТренинг «Синтаксический разбор»
Полный синтаксический разбор предложений
Итоговый тест «Синтаксический разбор в формате ЕГЭ»
Пройди итоговые тесты по теме: Синтаксический разбор слова
Виды предложений по цели высказывания и по интонации
Каждое предложение произносится или пишется с какой-то целью: что-то рассказать, о чём-то спросить, попросить или приказать что-то сделать. По цели высказывания и интонации предложения делятся на виды:
По цели высказывания и интонации предложения делятся на виды:
Виды предложений по цели высказывания
Цель высказывания — это цель, с которой предложение произносится или пишется. Целью высказывания может быть сообщение, вопрос или просьба (приказ, побуждение к действию, совет).
Предложения с точки зрения выраженного в них содержания, то есть по цели высказывания, бывают повествовательные, вопросительные и побудительные.
- Повествовательное предложение — это предложение, в котором что-либо сообщается, что-либо утверждается или что-либо отрицается:
На улице плохая погода.
Дельфин – млекопитающее.
Дельфин – не рыба.
В конце повествовательного предложения ставится точка, восклицательный знак или многоточие:Нам пора домой.
Мы идём в кино!
А вот и рассвет.
Повествовательные предложения произносятся с повествовательной интонацией — повышение голоса на одном из членов предложения и понижение его к концу предложения. ..
.. - Вопросительное предложение — это предложение, которое содержит вопрос. В конце вопросительного предложения ставится вопросительный знак:
Что ты делаешь?
Вопросительное предложение может содержать вопросительные слова:Какой это цвет?
Где ты сегодня был?
Иногда вопрос выражается с помощью вопросительных частиц ли, ль, разве и др.:Не хочешь ли тоже поехать?
Тебе ль не знать?
Разве тебе уже можно?
Вопрос может выражаться только вопросительной интонацией, в этом случае вопросительных слов и частиц предложение содержать не будет. Повышение голоса будет падать на главное по смыслу слово в предложении:Поедешь с нами на дачу?
Вы Иванова ждёте?
Вопросительные предложения произносятся с вопросительной интонацией — повышение тона голоса на слове, с которым связан смысл вопроса, и к концу предложения:Вам нравится читать?
Вам нравится читать?
Вам нравится читать?
- Побудительное предложение — это предложение, которое содержит повеление, просьбу или запрет.
 В конце повелительного предложения, в зависимости от того, произносится оно спокойным или повышенным тоном, ставится точка или восклицательный знак:
В конце повелительного предложения, в зависимости от того, произносится оно спокойным или повышенным тоном, ставится точка или восклицательный знак:
Закройте дверь.
Не входить!
Побудительные предложения часто содержат обращения:Оля, закрой окно.
Примечание: побудительные предложения часто имеют только один главный член — сказуемое, выраженное глаголом в повелительном наклонении:Не ходите по мокрому полу.
Побудительные предложения произносятся с побудительной интонацией — с повышением голоса, напряжённо.
Виды предложений по интонации
По эмоциональной окраске (интонации) предложения делятся на восклицательные и невосклицательные:
- Восклицательное предложение — это предложение, в котором высказываемая мысль сопровождается сильным чувством (удивлением, восторгом, восхищением, радостью и т.
 п.). Восклицательное предложение произносится с особой восклицательной интонацией. В конце восклицательного предложения ставится восклицательный знак:
п.). Восклицательное предложение произносится с особой восклицательной интонацией. В конце восклицательного предложения ставится восклицательный знак:
Сегодня отличная погода!
Восклицательными могут быть повествовательные, вопросительные и побудительные предложения:Отличный фильм! — предложение по цели высказывания повествовательное, по эмоциональной окраске — восклицательное.
Что делать будем?! — предложение по цели высказывания вопросительное, по эмоциональной окраске — восклицательное.
Собирайся скорей! — предложение по цели высказывания побудительное, по эмоциональной окраске — восклицательное.
- Невосклицательное предложение — это предложение, произносимое спокойным тоном, без ярко выраженных эмоций (чувств). На конце невосклицательных предложений ставится точка:
Как быстро прошло лето.
Предложение простое (синтаксический разбор: схема, пример) | сочинение, краткое содержание, анализ, биография, характеристика, тест, отзыв, статья, реферат, ГДЗ, книга, пересказ, сообщение, доклад, литература | Читать онлайн
Тема: Лингвистические термины и определения
Синтаксический разбор простого предложенияе (схема)
- Определить вид предложения по цели высказывания: повествовательное, вопросительное или побудительное.

- Определить вид предложения по интонации: восклицательное или невосклицательное.
- Найти главные члены предложения (грамматическую основу): подлежащее и сказуемое. Подчеркнуть их в предложении. Определить вид сказуемого.
- Указать, односоставное или двусоставное предложение. Если односоставное, определить его разновидность: определенно-личное, обобщенно-личное, неопределенно-личное, безличное или назывное.
- Указать, распространенное или нераспространенное предложение.
- Определить второстепенные члены предложения. Подчеркнуть их в предложении.
- Указать, полное или неполное предложение. Если предложение неполное, указать, какой член предложения пропущен.
- Указать, неосложненное или осложненное предложение. Если предложение осложненное, то указать, чем оно осложнено: однородными членами, обособленными членами, обращением, вводными конструкциями (вводными словами, вводными предложениями, вставными конструкциями), прямой речью.
 Материал с сайта //iEssay.ru
Материал с сайта //iEssay.ru
Синтаксический разбор простого предложенияе (пример)
На белых плюшевых щитках, освещенные скрытыми рефлекторами, горят разноцветные капли огня (А. И. Куприн).
Предложение повествовательное, невосклицательное, утвердительное.
По количеству грамматических основ — простое: одна грамматическая основа (капли горят). По наличию главных членов предложения — двусоставное: подлежащее — капли, сказуемое — горят (простое глагольное сказуемое).
По наличию второстепенных членов — распространенное.
По наличию пропущенных членов — полное.
По наличию осложняющих членов — осложненное обособленным определением (причастным оборотом). Освещенные скрытыми рефлекторами — обособленное определение, которое предшествует определяемому слову, между определяемым словом и определением расположены другие члены предложения.
На этой странице материал по темам:- пример восклицательного предложения с разбором
- что такое синтаксический разбор предложения примеры
- схема синтаксический разбор предложения примеры
- простые и двусоставные предложения примеры
- онлайн синтаксический разбор слов
Виды предложений по цели высказывания.
 Повествовательные предложения
Повествовательные предложенияСегодня мы ответим на такие вопросы.
· Какими бывают предложения?
· Что такое повествовательные предложения?
· Какая интонация в повествовательных предложениях?
Мы помним, что предложение – это слово или несколько слов, которые выражают законченную мысль. Предложение имеет интонацию завершённости.
Слова в предложении связаны по смыслу и грамматически. В предложении есть грамматическая основа. Грамматическая основа предложения может состоять из одного или двух главных членов.
У каждого из нас своя цель. Для чего мы выполняем какое-то действие?
У наших высказываний тоже есть цели.
Мы говорим для чего-то. Для чего?
Мне
рассказали о новом фильме. Наверное, он очень интересный. Рассмотрим это
высказывание. Какова его цель? Конечно, сообщить информацию.
Рассмотрим это
высказывание. Какова его цель? Конечно, сообщить информацию.
Рассмотрим ещё одно высказывание. А тебе рассказали о новом фильме? Как ты думаешь, он очень интересный? Цель изменилась. Теперь целью стало задать вопрос.
А вот и ещё одно высказывание. Расскажи мне о новом фильме! Пусть твой рассказ будет интересным. Цель вновь изменилась. Теперь мы побуждаем к действию.
Вы видите, что у каждого высказывания – своя цель. И поэтому все предложения делятся на виды по цели высказывания.
Они бывают повествовательными, вопросительными и побудительными.
В повествовательных предложениях мы сообщаем о чем-либо. Это видно даже из названия: повествовательные – от повествовать. Созвучно словам повесть, весть. Мы можем сообщать, повествовать о любой информации.
Представьте
себе телеведущего, который говорит что-нибудь подобное: «Сегодня в нашем
музее открылась необычная выставка. Посетители смогут посмотреть на старинные
ёлочные игрушки. Вас ждёт незабываемое зрелище!»
Посетители смогут посмотреть на старинные
ёлочные игрушки. Вас ждёт незабываемое зрелище!»
В вопросительных предложениях обязательно содержится вопрос. Вопросы могут быть самыми разнообразными. Теперь мы можем представить себе репортёра. Который живо интересуется всем вокруг. Он так и сыплет вопросами: «А вы видели, что произошло? Где все это случилось? Когда вы узнали об этом? Хотите поделиться своим мнением? Неужели вам не интересно? Почему вы улыбаетесь?» И ещё множество вопросов. И всё это – вопросительные предложения.
В побудительных предложениях мы стараемся побудить человека к действию. Мы приказываем что-нибудь или просим о чем-нибудь.
Здесь можно представить выступление оратора. Который хочет нас в чём-нибудь убедить. «Послушайте! Давайте поговорим о самом важном. Как можно чаще улыбайтесь. Будьте внимательны к окружающим людям. Не стесняйтесь говорить тёплые слова».
Все эти
предложения – побудительные.
Итак, по цели высказывания предложения бывают:
Повествовательные. В них сообщается информация.
Вопросительные. В них ставится вопрос, они обязательно содержат вопрос. Побудительные. Они содержат побуждение к действию. Например, приказ или просьбу.
Подробнее поговорим о повествовательных предложениях. Вам не кажется знакомым название?
Давайте-ка вспомним, где мы могли слышать что-то похожее? Ну, конечно. Когда мы говорили о типах речи. Помните – повествование, описание, рассуждение?
Так вот, ни в коем случае не следует путать повествование с повествовательными предложениями.
Это совершенно разные явления.
Повествовательные предложения могут встречаться нам в любом типе речи.
Составим небольшой текст. Например, такой:
Вчера
со мной произошла удивительная история. Я шёл из школы и внезапно увидел, как
по тротуару неторопливо шествует бегемот. Оказывается, утром он сбежал из
зоопарка. Такого раньше никогда не бывало в нашем городе!
Оказывается, утром он сбежал из
зоопарка. Такого раньше никогда не бывало в нашем городе!
В этом тексте мы рассказываем о каких-то событиях. Это повествование. И все предложения в этом тексте повествовательные.
Но и в описании все предложения могут быть повествовательными. Рассмотрим вот такой небольшой текст.
Бегемот – крупное, сильное животное. Большую часть жизни он проводит в воде. Туловище у бегемота напоминает бочку, поставленную на коротенькие ножки. Окрас у бегемотов обычно серо-коричневый. Шкура очень толстая – до четырёх сантиметров.
Тип речи – описание. Но все предложения – повествовательные. Ведь в каждом из них сообщается какая-то информация.
Но и рассуждение может полностью состоять из повествовательных предложений! Вот ещё один текст:
Мы
задумались над тем, что побудило бегемота сбежать из зоопарка. Возможно, с ним
плохо обращались. Может быть, ему просто захотелось немного прогуляться. Или
познакомиться с городом. Или совершить небольшой кросс.
Или
познакомиться с городом. Или совершить небольшой кросс.
Тип речи – рассуждение. Но все предложения – повествовательные. Ведь мы сообщаем информацию, а не задаём вопросы или не пытаемся кого-то побудить к действию.
У всех этих повествовательных предложений будет одинаковая интонация.
В начале повествовательных предложений мы сначала повышаем голос, потом делаем паузу и понижаем голос.
Подключим воображение. Схема интонации получается немного похожей на зонтик.
Итак, что нам требуется запомнить?
Предложения по цели высказывания бывают повествовательными, вопросительными и побудительными.
В повествовательных предложениях мы сообщаем информацию.
В начале повествовательных предложений мы повышаем голос. Потом делаем паузу. И понижаем голос.
Определение синтаксического анализа Merriam-Webster
\ ˈPärs , в основном британский ˈpärz \переходный глагол
1а : для разделения (предложения) на грамматические части и определения частей и их отношения друг к другу.
2 : для мелкого анализа : для критического анализа возникли проблемы с анализом при анализе … объяснения сокращения доли рынка — Р.С. Энсон
непереходный глагол
1 : для грамматического описания слова или группы слов.
2 : , чтобы признать анализ
: продукт или экземпляр синтаксического анализаграмматически укореняется с помощью деревьев синтаксического анализа | автор: Вайдехи Джоши | basecs
Грамматическое рутирование с помощью деревьев разбора! Размышления обо всех абстракциях, которые окружают нас в мире технологий, иногда могут быть непосильными. Это особенно верно, когда вы пытаетесь обдумать новую парадигму или распаковать слои одной или нескольких концепций, которые вы пытаетесь понять.
Это особенно верно, когда вы пытаетесь обдумать новую парадигму или распаковать слои одной или нескольких концепций, которые вы пытаетесь понять.
В контексте изучения информатики просто слишком много абстракций, чтобы знать, видеть или распознать их все, не говоря уже о том, чтобы можно было понять их все!
Абстракции — мощные вещи, когда вы можете видеть за их пределами и понимать, как что-то абстрагируется и почему может сделать вас лучшим программистом.Однако по той же причине каждая абстракция была создана по определенной причине: чтобы никому из нас не приходилось беспокоиться о них каждый день! Мы не должны постоянно думать об абстракциях, и по большей части очень немногие из нас действительно думают. Но вот в чем дело — одни абстракции более равны, чем другие. Большинство инженеров, вероятно, заботятся о том, как они общаются со своим компьютером, и о том, как их компьютер на самом деле понимает их .Даже если нам никому из нас никогда не придется писать алгоритм пузырьковой сортировки, если мы напишем код, тогда нам придется взаимодействовать с нашими машинами.
Что ж, пришло время нам наконец разобраться в этих загадках и понять абстракции, лежащие в основе наших рабочих процессов как программистов.
Древовидная структура данных постоянно появляется снова и снова в наших приключениях в области информатики. Мы видели, как они используются для хранения данных всех типов, мы видели, что они самобалансирующиеся, а другие были оптимизированы для хранения и хранения.Мы даже рассмотрели, как управлять деревьями, вращая и перекрашивая их, чтобы убедиться, что они соответствуют набору правил.
Но, несмотря на все эти различные формы флоры структур данных, есть одна конкретная итерация древовидной структуры данных, которую нам еще предстоит обнаружить. Даже если бы мы ничего не знали о компьютерных науках, о том, как сбалансировать дерево, или о том, как вообще работает древовидная структура данных, все программисты ежедневно взаимодействуют с одним типом древовидной структуры в силу того простого факта, что каждый разработчик, который пишет код необходимо убедиться, что их код понимается их машинами.
Эта структура данных называется деревом синтаксического анализа, и это (одна из) базовых абстракций, которые позволяют коду, который мы пишем как программисты, стать «читаемым» нашими компьютерами.
Дерево синтаксического анализа: определение.По своей сути дерево синтаксического анализа — это иллюстрированная графическая версия грамматической структуры предложения. Деревья синтаксического разбора на самом деле уходят корнями в область лингвистики, но они также используются в педагогике, которая является изучением преподавания.Деревья синтаксического разбора часто используются, чтобы научить студентов определять части предложения, и являются обычным способом введения грамматических понятий. Вполне вероятно, что каждый из нас взаимодействовал с ними благодаря настойчивому построению диаграмм предложений, чему некоторые из нас могли научиться в начальной школе.
Дерево синтаксического анализа — это на самом деле просто «схематическая» форма предложения; это предложение может быть написано на любом языке, а это значит, что оно может соответствовать любому набору грамматических правил.

Диаграмма предложений включает в себя разбиение одного предложения на самые мелкие и наиболее отчетливые части.Если мы подумаем о деревьях синтаксического анализа с точки зрения последовательного построения диаграмм предложений, мы быстро начнем понимать, что в зависимости от грамматики и языка предложения дерево синтаксического анализа действительно может быть построено множеством различных способов!
Но что такое компьютерная версия «предложения»? И как же нам это сделать?
Что ж, это помогает начать с примера того, что нам уже удобно, так что давайте освежим наши воспоминания, нарисовав обычное предложение на английском языке.
Простое построение диаграмм предложений с помощью деревьев синтаксического анализа. На показанной здесь иллюстрации у нас есть простое предложение: «Вайдехи съел пирог» . Поскольку мы знаем, что дерево синтаксического анализа — это просто предложение в виде диаграммы, мы можем построить дерево синтаксического анализа из этого примера предложения.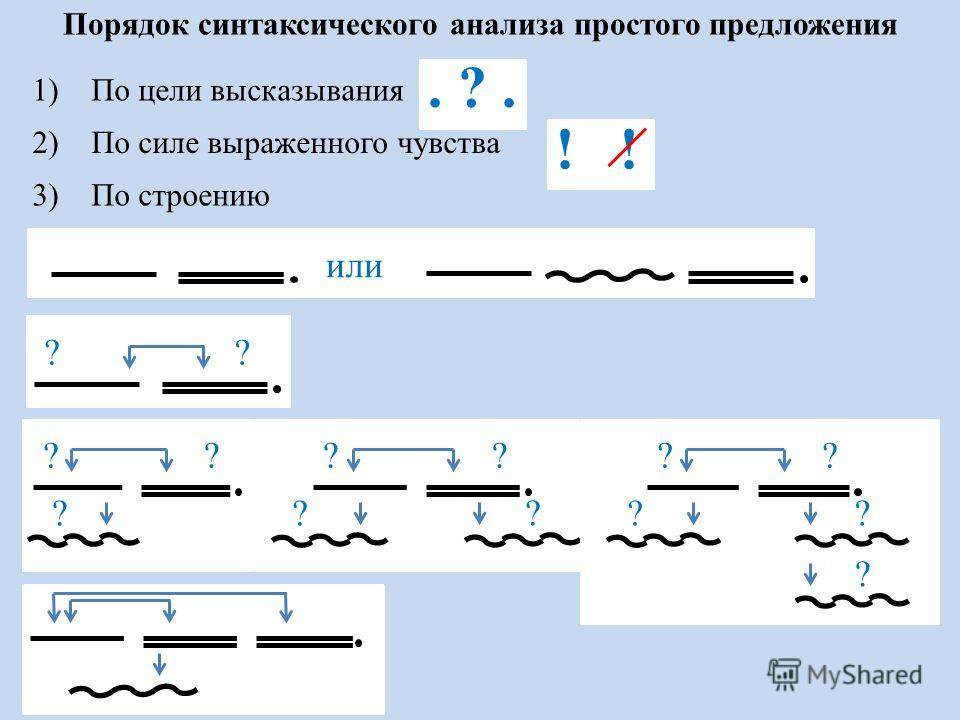 Помните, что на самом деле все, что мы пытаемся сделать, — это определить различные части этого предложения и разбить его на самые маленькие, самые отдельные части.
Помните, что на самом деле все, что мы пытаемся сделать, — это определить различные части этого предложения и разбить его на самые маленькие, самые отдельные части.
Мы можем начать с разделения предложения на две части: существительное , «Vaidehi» и глагольное словосочетание , «съел пирог» .Поскольку существительное не может быть далее разбито, оставим слово "Vaidehi" как есть. Другой способ подумать об этом заключается в том, что, поскольку мы не можем дальше разбивать существительное, от этого слова не будет дочерних узлов.
А как насчет глагольной фразы «съел пирог» ? Ну, эта фраза еще не дошла до самой простой формы, не так ли? Мы можем проанализировать это еще дальше. Во-первых, слово «съел», — это глагол, а «пирог», — скорее существительное, а точнее, существительное словосочетание .Если мы разделим «съел пирог» и , мы сможем разделить его на глагол и именную фразу. Поскольку глагол не может быть изображен на диаграмме с дополнительными деталями, слово
Поскольку глагол не может быть изображен на диаграмме с дополнительными деталями, слово «съел» станет листовым узлом в нашем дереве синтаксического анализа.
Хорошо, теперь осталось только словосочетание "пирог" . Мы можем разделить эту фразу на две отдельные части: существительное «пирог» и его определитель , который известен как любое слово-модификатор существительного. В данном случае определителем является слово «the» .
Как только мы разделим нашу именную фразу, мы закончим разделение нашего предложения! Другими словами, мы закончили построение схемы нашего дерева синтаксического анализа. Когда мы посмотрим на наше дерево синтаксического анализа, мы заметим, что наше предложение по-прежнему читается так же, и мы его вообще не изменили. Мы просто взяли данное нам предложение и использовали правила английской грамматики, чтобы разбить его на самые маленькие, самые отчетливые части.
Что на самом деле означает анализировать что-то?В случае английского языка самой маленькой «частью» каждого предложения является слово; слова могут быть объединены в фразы, такие как словосочетания с существительными или словосочетания с глаголами, которые, в свою очередь, могут быть объединены с другими фразами, чтобы создать выражение для предложения.
Однако это всего лишь один пример того, как одно конкретное предложение на одном конкретном языке с собственным набором грамматических правил может быть представлено в виде дерева синтаксического анализа. Это же предложение выглядело бы совершенно иначе на другом языке, особенно если бы оно следовало собственному набору грамматических правил.
В конечном итоге грамматика и синтаксис языка — включая способ структурирования предложений этого языка — становятся правилами, которые определяют, как этот язык определяется, как мы на нем пишем и как те из нас, кто говорят на языке, в конечном итоге понимают и интерпретируют его.
Интересно, что мы знали, как построить простое предложение «Вайдехи съел пирог». , потому что мы уже были знакомы с грамматикой английского языка. Представьте, если бы в нашем предложении вообще отсутствовало существительное или глагол? Что случилось бы? Что ж, мы, вероятно, прочитали это предложение в первый раз и быстро поняли, что это вообще не было предложением! Скорее, мы читали его и почти сразу видели, что имеем дело с фрагментом предложения или неполным фрагментом предложения.
Однако единственная причина, по которой мы сможем распознать фрагмент предложения, состоит в том, что мы знаем правила английского языка, а именно, что (почти) каждое предложение нуждается в существительном и глаголе, чтобы считаться действительным. Грамматика языка — это то, как мы можем проверить, действительно ли предложение на языке; этот процесс «проверки» на достоверность называется , анализирующим предложения.
Процесс синтаксического анализа предложения для его понимания, когда мы читаем его впервые, включает в себя те же мысленные шаги, что и построение диаграммы предложения, а построение диаграммы предложения включает те же шаги, что и построение дерева синтаксического анализа.Когда мы читаем предложение в первый раз, мы мысленно разбираем и разбираем его.
Оказывается, компьютеры делают то же самое с кодом, который мы пишем!
Хорошо, теперь мы знаем, как построить диаграмму и проанализировать предложение на английском языке. Но как это применимо к коду? А что вообще такое «предложение» в нашем коде?
Но как это применимо к коду? А что вообще такое «предложение» в нашем коде?
Что ж, мы можем рассматривать дерево синтаксического анализа как иллюстрированное «изображение» того, как выглядит наш код. Если мы представим наш код, нашу программу или даже простейший из скриптов в форме предложения, мы, вероятно, довольно быстро поймем, что весь код, который мы пишем, действительно можно просто упростить до наборов выражений.
Это становится более понятным на примере, поэтому давайте рассмотрим суперпростую программу-калькулятор. Используя одно выражение, мы можем использовать грамматические «правила» математики для создания дерева синтаксического анализа из этого выражения. Нам нужно будет найти самые простые, наиболее отчетливые единицы нашего выражения, а это значит, что нам нужно будет разбить наше выражение на более мелкие сегменты, как показано ниже.
Поиск грамматики в математических выражениях. Мы заметим, что у одного математического выражения есть свои собственные правила грамматики; даже простое выражение (например, два числа, которые умножаются вместе и затем добавляются к другому числу) можно разбить внутри себя на еще более простые выражения.
Но для начала давайте поработаем с простых вычислений. Как мы могли бы создать дерево синтаксического анализа, используя математическую грамматику для такого выражения, как 2 x 8 ?
Если мы подумаем о том, как на самом деле выглядит это выражение, мы увидим, что здесь есть три отдельных части: выражение слева, выражение справа и операция, которая умножает их вместе.
На изображении, показанном здесь, выражение 2 x 8 показано в виде дерева синтаксического анализа.Мы увидим, что оператор x — это часть выражения, которую нельзя упростить дальше, поэтому у нее нет дочерних узлов.
Выражения слева и справа можно упростить до конкретных терминов, а именно 2 и 8 . Подобно примеру предложения на английском языке, который мы рассмотрели ранее, одно математическое выражение может содержать внутренних выражений внутри него, а также отдельные терминов , например, фраза 2 x 8 , или множителей , например число 2 как отдельное выражение.
Но что происходит после создания этого дерева синтаксического анализа? Мы заметим, что иерархия дочерних узлов здесь немного менее очевидна, чем в нашем предыдущем примере предложения. оба 2 и 8 находятся на одном уровне, так как мы можем это интерпретировать?
Что ж, мы уже знаем, что существуют различные способы обхода дерева в глубину. В зависимости от того, как мы проходим через это дерево, это единственное математическое выражение 2 x 8 можно интерпретировать и читать разными способами.Например, если мы прошли через это дерево, используя в порядке обхода , мы прочитали левое дерево, корневой уровень, а затем правое дерево, в результате получилось 2 -> x -> 8 .
Но если бы мы решили пройти по этому дереву, используя предварительный порядок обхода , мы бы сначала прочитали значение на корневом уровне, затем в левом поддереве, а затем в правом поддереве, что даст нам x -> 2 - > 8 . И если бы мы использовали обход postorder , мы бы прочитали левое поддерево, правое поддерево, а затем, наконец, прочитали корневой уровень, что дало бы
И если бы мы использовали обход postorder , мы бы прочитали левое поддерево, правое поддерево, а затем, наконец, прочитали корневой уровень, что дало бы 2 -> 8 -> x .
Деревья синтаксического разбора показывают нам, как наши выражения выглядят как , раскрывая конкретный синтаксис наших выражений, который часто означает, что одно дерево синтаксического анализа может выражать «предложение» различными способами. По этой причине деревья синтаксического анализа также часто называют Конкретными деревьями синтаксиса или для краткости CST . Когда эти деревья интерпретируются или «читаются» нашими машинами, должны быть строгие правила в отношении того, как эти деревья анализируются, чтобы мы получили правильное выражение со всеми терминами в правильном порядке и в правильном место!
Но большинство выражений, с которыми мы имеем дело, сложнее, чем просто 2 x 8 .Даже для программы-калькулятора нам, вероятно, потребуются более сложные вычисления. Например, что произойдет, если мы захотим найти такое выражение, как
Например, что произойдет, если мы захотим найти такое выражение, как 5 + 1 x 12 ? Как бы выглядело наше дерево синтаксического анализа?
Что ж, как оказалось, проблема с деревьями синтаксического анализа в том, что иногда вы можете получить более одного.
Неоднозначная грамматика в (парсинге) действии!Более конкретно, может быть более одного результата для одного анализируемого выражения. Если мы предположим, что синтаксические деревья сначала считываются с самого нижнего уровня, мы можем начать видеть, как иерархия листовых узлов может заставить одно и то же выражение интерпретироваться двумя совершенно разными способами, давая в результате два совершенно разных значения.
Например, на иллюстрации выше есть два возможных дерева синтаксического анализа для выражения 5 + 1 x 12 . Как мы видим на левом дереве синтаксического анализа, иерархия узлов такова, что сначала будет вычислено выражение 1 x 12 , а затем будет продолжено сложение: 5 + (1 x 12) . С другой стороны, правильное дерево синтаксического анализа сильно отличается; иерархия узлов заставляет сначала происходить сложение (
С другой стороны, правильное дерево синтаксического анализа сильно отличается; иерархия узлов заставляет сначала происходить сложение ( 5 + 1 ), а затем перемещается вверх по дереву, чтобы продолжить умножение: (5 + 1) x 12 .
Неоднозначная грамматика в языке — это именно то, что вызывает такого рода ситуацию: когда неясно, как должно быть построено синтаксическое дерево, его можно построить (по крайней мере) более чем одним способом.
Борьба с неоднозначной грамматикой как компиляторНо вот загвоздка: неоднозначная грамматика — это проблема для компилятора!
Основываясь на правилах математики, которые большинство из нас изучали в школе, мы по своей сути знаем, что умножение всегда должно выполняться перед сложением.Другими словами, только левое дерево синтаксического анализа в приведенном выше примере действительно является правильным на основе грамматики математики. Помните: грамматика — это то, что определяет синтаксис и правила любого языка, будь то английское предложение или математическое выражение.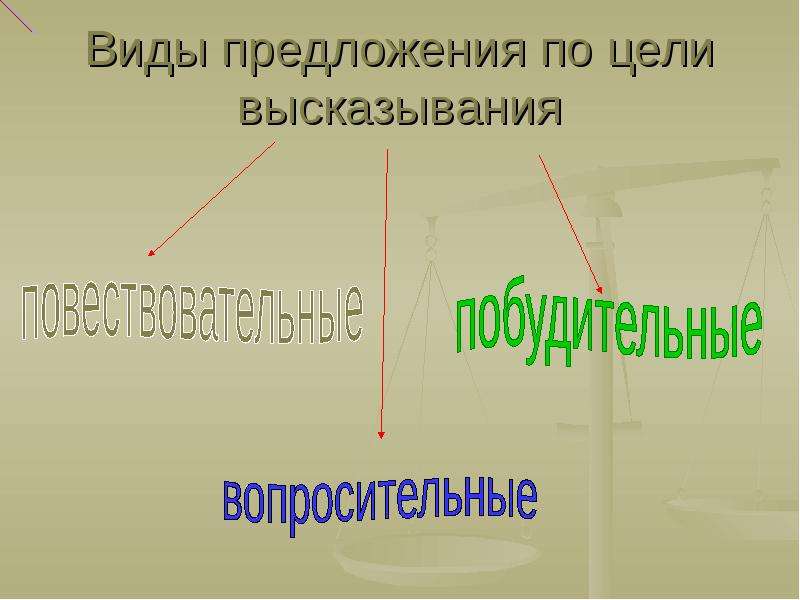
Но откуда компилятору изначально знать эти правила? Что ж, это просто невозможно! Компилятор не знал бы, каким образом читать код, который мы пишем, если мы не дадим ему грамматических правил, которым нужно следовать. Если бы компилятор увидел, что мы написали математическое выражение, например, которое может привести к двум различным деревьям синтаксического анализа, он не знал бы, какое из двух деревьев синтаксического анализа выбрать, и, следовательно, он не знал бы, как даже читать или интерпретировать наш код.
По этой причине в большинстве языков программирования обычно избегают неоднозначной грамматики. Фактически, большинство синтаксических анализаторов и языков программирования намеренно решают проблемы неоднозначности с самого начала. Язык программирования обычно имеет грамматику, которая обеспечивает приоритет , что заставляет некоторые операции или символы иметь более высокий вес / значение, чем другие. Примером этого является гарантия того, что всякий раз, когда создается дерево синтаксического анализа, умножение имеет более высокий приоритет, чем сложение, так что когда-либо может быть построено только одно дерево синтаксического анализа.
Еще один способ справиться с проблемами неоднозначности — это принудительное использование способа интерпретации грамматики. Например, в математике, если бы у нас было такое выражение, как 1 + 2 + 3 + 4 , мы по сути знаем, что должны начинать сложение слева и двигаться вправо. Если бы мы хотели, чтобы наш компилятор понимал, как это сделать с нашим собственным кодом, нам нужно было бы обеспечить левой ассоциативности , которая сузила бы наш компилятор так, чтобы при синтаксическом анализе нашего кода он создавал дерево синтаксического анализа, которое помещает фактор из 4 ниже в иерархии дерева синтаксического анализа, чем фактор 1 .
Эти два примера часто упоминаются как правила устранения неоднозначности в конструкции компилятора, поскольку они создают определенные синтаксические правила, гарантирующие, что мы никогда не получим неоднозначную грамматику, которая будет сильно сбивать с толку наш компилятор.
Если неоднозначность является корнем всего зла дерева синтаксического анализа, то ясность, несомненно, является предпочтительным режимом работы. Конечно, мы можем добавить правила устранения неоднозначности, чтобы избежать неоднозначных ситуаций, из-за которых наш бедный маленький компьютер будет в тупике, когда он читает наш код, но на самом деле мы делаем гораздо больше.Или, скорее, именно языки программирования, которые мы используем, делают самую тяжелую работу!
Позвольте мне объяснить. Мы можем думать об этом так: один из способов добавить ясности математическому выражению — использовать скобки. Фактически, это то, что большинство из нас, вероятно, поступило бы с выражением, с которым имели дело ранее: 5 + 1 x 12 . Мы, вероятно, прочитали бы это выражение и, вспомнив порядок действий, который мы выучили в школе, переписали бы его в своей голове как: 5 + (1 x 12) .Скобка () помогла нам прояснить само выражение и два выражения, которые по своей сути находятся в внутри . Эти два символа мы узнаем, и если бы мы поместили их в наше дерево синтаксического анализа, у них не было бы дочерних узлов, потому что их нельзя было бы разбить дальше.
Эти два символа мы узнаем, и если бы мы поместили их в наше дерево синтаксического анализа, у них не было бы дочерних узлов, потому что их нельзя было бы разбить дальше.
Это то, что мы называем терминалами , которые также широко известны как токенов . Они имеют решающее значение для всех языков программирования, потому что помогают нам понять, как части выражения связаны друг с другом, а также синтаксические отношения между отдельными элементами.Некоторые общие токены в программировании включают знаки операций ( + , - , x , /), круглые скобки ( () ) и зарезервированные условные слова (, если , , затем , иначе , конец ). Некоторые токены используются, чтобы помочь прояснить выражения, поскольку они могут указывать, как разные элементы связаны друг с другом.
Итак, что же все-таки есть в нашем дереве синтаксического анализа? У нас явно больше, чем знаков и + в нашем коде! Ну, нам также обычно приходится иметь дело с наборами из нетерминалов , которые являются выражениями, терминами и факторами, которые потенциально могут быть разбиты дальше. Это фразы / идеи, содержащие в себе другие выражения, например, выражение
Это фразы / идеи, содержащие в себе другие выражения, например, выражение (8 + 1) / 3 .
И терминалы, и нетерминалы имеют определенную связь с тем, где они появляются в дереве синтаксического анализа. Как можно предположить из их названия, символ терминала всегда будет являться листьями дерева синтаксического анализа; это означает, что «терминалами» являются не только операторы, круглые скобки и зарезервированные условные выражения, но и все значения факторов, которые представляют строку, число или концепцию, присутствующую в каждом листовом узле.Все, что разбито на мельчайшие кусочки, всегда будет «терминалом».
Определение уникальных частей синтаксического дерева.С другой стороны, внутренние узлы дерева синтаксического анализа — нелистовые узлы, которые являются родительскими узлами, — это нетерминальных символов , и именно они представляют собой применение правил грамматики языка программирования.
Дерево синтаксического анализа становится намного проще для понимания, визуализации и идентификации, когда мы понимаем, что это не более чем представление нашей программы и всех символов, концепций и выражений в ней.
Понимание роли парсераНо какова вообще ценность дерева синтаксического анализа? Мы, программисты, не думаем об этом, но оно должно существовать по какой-то причине, верно?
Ну, как оказалось, больше всего о дереве разбора заботится парсер , который является частью компилятора, который обрабатывает процесс синтаксического анализа всех кода, который мы пишем.
Процесс синтаксического анализа на самом деле просто принимает некоторые входные данные и строит из них дерево синтаксического анализа.Этот ввод может быть множеством разных вещей, например строкой, предложением, выражением или даже целой программой.
Независимо от того, какой ввод мы ему дадим, наш синтаксический анализатор проанализирует этот ввод на грамматические фразы и построит на их основе дерево синтаксического анализа. Синтаксический анализатор действительно выполняет две основные роли в контексте нашего компьютера и в процессе компиляции:
- Если задана допустимая последовательность токенов, он должен иметь возможность генерировать соответствующее дерево синтаксического анализа, следуя синтаксису языка.

- Когда задана недопустимая последовательность токенов, он должен быть в состоянии обнаружить синтаксическую ошибку и сообщить программисту, который написал код проблемы в своем коде.
Вот и все! Это может показаться очень простым, но если мы начнем рассматривать, насколько массивными и сложными могут быть некоторые программы, мы быстро начнем понимать, насколько четко должны быть вещи, чтобы синтаксический анализатор действительно выполнял эти две, казалось бы, простые роли.
Например, даже простому синтаксическому анализатору нужно много сделать, чтобы обработать синтаксис выражения вроде 1 + 2 + 3 x 4 .
- Во-первых, ему нужно построить дерево синтаксического анализа на основе этого выражения. Входная строка, которую получает синтаксический анализатор, может не показывать никакой связи между операциями, но синтаксическому анализатору необходимо создать дерево синтаксического анализа, которое это делает.

- Однако для этого ему необходимо знать синтаксис языка и правила грамматики, которым нужно следовать.
- Как только он сможет фактически создать одно дерево синтаксического анализа (без двусмысленности), он должен иметь возможность извлекать токены и нетерминальные символы и упорядочивать их так, чтобы иерархия дерева синтаксического анализа была правильной.
- Наконец, синтаксический анализатор должен гарантировать, что при оценке этого дерева оно будет оцениваться слева направо с операторами того же приоритета.
- Но подождите! Также необходимо убедиться, что при обходе этого дерева с использованием метода обхода inorder снизу не возникает ни одной синтаксической ошибки!
- Конечно, если делает ошибку , синтаксический анализатор должен посмотреть на ввод, выяснить, где он сломается, а затем сообщить об этом программисту.
Если это кажется ужасно большим объемом работы, то это потому, что это так. Но не беспокойтесь о том, чтобы сделать все это, потому что это работа парсера, и большая часть ее абстрагируется. К счастью, синтаксическому анализатору помогают другие части компилятора. Подробнее об этом на следующей неделе!
К счастью, синтаксическому анализатору помогают другие части компилятора. Подробнее об этом на следующей неделе!
К счастью для нас, дизайну компилятора хорошо учат почти в каждой учебной программе по информатике, и есть приличное количество надежных ресурсов, которые помогут нам понять различные части компилятора, включая синтаксический анализатор и синтаксический анализ. дерево.Однако, как и в случае с большинством CS-контента, многое из этого может быть трудно переварить, особенно если вы не знакомы с используемыми концепциями или жаргоном. Ниже приведены еще несколько удобных для новичков ресурсов, которые все еще хорошо объясняют деревья синтаксического анализа, если вы обнаружите, что хотите узнать еще больше.
- Дерево синтаксического анализа, интерактивный Python
- Грамматики, синтаксический анализ, обход дерева, профессора Дэвид Грис и Дуг Джеймс
- Давайте создадим простой интерпретатор, часть 7, Руслан Спивак
- Руководство по синтаксическому анализу: алгоритмы и терминология, Габриэле Томассетти
- Лекция 2: Абстрактный и конкретный синтаксис, Аарне Ранта
- Компиляторы и интерпретаторы, профессор Чжун Шао
- Основы компилятора — синтаксический анализатор, Джеймс Алан Фаррелл
Лаборатория 6: CKY Parser
Лаборатория 6: CKY ParserSI425, осень 2017
Срок сдачи : начало занятий, 9 ноября
Milestone : 26 октября, диагональ с унарными правилами
Веха : 2 ноября, шаги 1–4 завершены («Шаги для заблудших» ниже)
Мотивация
Синтаксический анализ сегодня используется в большинстве передовых приложений НЛП. От машинного перевода до извлечения информации и классификации документов синтаксическая структура предложения дает вашим алгоритмам обучения гораздо больше полезной информации, чем одни только слова. Вы напишете стандартный алгоритм CKY для разбора предложений.
От машинного перевода до извлечения информации и классификации документов синтаксическая структура предложения дает вашим алгоритмам обучения гораздо больше полезной информации, чем одни только слова. Вы напишете стандартный алгоритм CKY для разбора предложений.
Цель
Вы напишете алгоритм CKY. Большая часть кода для создания самого PCFG уже написана для вас. Вам просто нужно прочитать корпус предложений с их деревьями синтаксического анализа, преобразовать деревья в двоичный вид (я даже даю вам двоичный код), и PCFG создан для вас.Учитывая этот PCFG, напишите алгоритм CKY.
Алгоритм CKY
Входными данными для вашей программы являются список деревьев обучения и список деревьев тестирования. Ваш алгоритм будет оцениваться на основе того, насколько его результат (ваши угаданные деревья) похож на золотой ответ (деревья, созданные вручную). Класс CKYParser.java — это то место, куда будет помещен ваш код. Есть две функции: train (Список) и getBestParse (Список) . Ваша реализация CKY идет в getBestParse .Вы строите грамматику и ее вероятности в train () .
Ваша реализация CKY идет в getBestParse .Вы строите грамматику и ее вероятности в train () .
Базовый синтаксический анализатор . Существует класс BaselineParser, который создает простые деревья для каждого предложения. Это сделано для того, чтобы помочь вам понять, как использовать инфраструктуру кода. Эта базовая линия берет предложение, маркирует каждое слово его наиболее вероятным тегом (т. Е. Тегом unigram), а затем ищет вхождения последовательности тегов в обучающем наборе. Если он находит точное совпадение, он отвечает с помощью обучающего синтаксического анализа соответствующего обучающего предложения.Если совпадения не найдено, он строит дерево с ветвлением вправо с метками узлов, выбранными независимо, при условии только длины диапазона узла. Если это звучит странно (и ужасно), значит, так и должно быть.
Лексикон . Посмотрите Lexicon.java . Здесь хранятся все унарные правила тега Part of Speech со словами: NNS-> cats. Используйте его для поиска этих правил.
Используйте его для поиска этих правил.
PCFG . Посмотрите Grammar.java . Это твой друг. Это вычисляет вероятности правил в вашем PCFG.Он просто устанавливает каждую вероятность следующим образом:
P (N -> XX) = C (N -> XX) / Sum_YY (C (N-> YY))
Ваша функция train () просто создаст экземпляр Grammar и инициализирует этот объект с помощью обучающих деревьев. Он вычислит для вас указанные выше вероятности.
CKY . Вы должны правильно реализовать алгоритм CKY, но вы также должны реализовать его с умом. Ваш синтаксический анализатор не должен занимать минуты для обработки каждого предложения. Перед тем как начать, хорошо подумайте, какие структуры данных вы будете использовать.Некоторые подсказки:
- Я предоставил вам псевдокод CKY. Эта ссылка — ваш друг. Не перебирайте все нетерминалы , как этот псевдокод. Это псевдокод по какой-то причине … не следуйте ему вслепую. Логика правильная, поэтому следуйте ей, но будьте осторожны с структурами данных и вызовами методов.

- Таблица CKY представляет собой матрицу размера n x n. Подумайте об использовании двойного массива . Двойной массив чего? Создайте класс java для представления одной ячейки в таблице. Каждая ячейка в массиве должна хранить нетерминалы и их вероятности … а также обратные указатели на ячейки, которым соответствуют правые части правил. Пусть все это сделает ваш собственный класс java.
- Каталог util / содержит несколько полезных классов, например Pair.java и Triplet.java . Если вам нужно сохранить две вещи вместе (название правила и его вероятность?), Это может сработать для вас. Однако вам не обязательно их использовать.
- Унарные правила.Не забывайте, что после того, как вы заполнили ячейку таблицы в алгоритме CKY, вам все равно нужно искать унарные правила, которые могут применяться к тому, что у вас там есть. Напишите функцию под названием handleUnaries (cell) , которая сделает это за вас. Опять же, см.
 Псевдокод выше.
Псевдокод выше.
miniTest : Заставьте ваш парсер работать на miniTest, прежде чем пытаться использовать наборы данных treebank. Набор данных miniTest состоит из 3 обучающих предложения и 1 тестовое предложение из игрушечной грамматики.Обучающий набор содержит всего достаточно примеров, чтобы создать неоднозначность PP-прикрепления в тестовом предложении. Вы должны набрать 100% на этом единственном тестовом дереве.
Правила бинаризации : Как мы обсуждали в классе, большинству синтаксических анализаторов требуется, чтобы грамматики имели не более
бинарные правила ветвления. Вы можете преобразовать в двоичную форму и отключить деревья с помощью класса TreeAnnotations.
Вызовите TreeAnnotations.binarizeTree (tree) , чтобы преобразовать дерево в двоичную форму, и TreeAnnotations.unBinarizeTree (дерево) преобразовать из двоичного кода обратно в нормальный.
Вызовите эту функцию и выведите деревья до / после, чтобы увидеть, что она делает. После бинаризации ваших обучающих деревьев вы можете использовать Grammar.java для сборки PCFG.
После бинаризации ваших обучающих деревьев вы можете использовать Grammar.java для сборки PCFG.
Учебные данные : загляните в некоторые текстовые файлы в data / genia и data / bioie, чтобы получить представление о сложности этих предложений и их деревьев синтаксического анализа. Вы заметите, что в грамматике относительно мало нетерминальных символов (27 плюс теги части речи), но есть тысячи правил, много тройных ветвлений или длиннее.
Шаги для заблудших
- Написать поезд ()
- Запишите первую часть getBestParse () в , заполните только диагональ таблицы CKY . Возьмите каждое слово, найдите его правила тегов POS в лексиконе (используя Lexicon.java) и заполните диагональ. Напишите операторы печати, чтобы убедиться в их правильности.
- Записать handleUnaries () из псевдокода. Используйте Grammar.java. Добавьте его к диагональному коду, который вы только что закончили. Распечатать выписки. Это правильно?
- Запишите оставшуюся часть псевдокода, заполнив всю таблицу.

- Напишите buildTree () для создания древовидной структуры из заполненной таблицы.
Milestone 1 Goal: miniTest диагональ
Для вехи, вот как должна выглядеть диагональ вашего стола для «кошки царапают стены когтями». В каждой ячейке есть 6 правил с правильными вероятностями.
| @PP -> _ P = 0,311, V = 0,064, P = 0,048, N = 0,350, NP = 0,311, @VP -> _ V = 0,207 | ||||
| @PP -> _ P = 0.057, V = 0,619, P = 0,051, N = 0,064, NP = 0,057, @VP -> _ V = 0,038 | ||||
| @PP -> _ P = 0,167, V = 0,077, P = 0,058, N = 0,188, NP = 0,167, @VP -> _ V = 0,111 | ||||
| @PP -> _ P = 0,057, V = 0,068, P = 0,876, N = 0,064, NP = 0,057, @VP -> _ V = 0,038 | ||||
@PP -> _ P = 0,240, V = 0,068, P = 0,051, N = 0,270, NP = 0,240, @VP -> _ V = 0. 160 160 |
Детали кода
CKYParser.java : введите здесь свой код.
BaselineParser.java : тупой парсер, но его код может вам помочь.
Lexicon.java : вызовите getAllTags () , чтобы получить все теги POS, замеченные при обучении. Вызовите getRuleProbability (POStag, word) , чтобы получить P (word | tag).
Grammar.java : Создайте новую грамматику, полностью обученную вероятностям, просто произнеся new Grammar (binaryRules) .Вызовите getBinaryRulesByLeftChild («DT») , чтобы получить список объектов BinaryRule, где левый дочерний элемент их правой стороны был «DT». Вызовите getUnaryRulesByOnlyChild («NN») , чтобы получить все унарные правила, которые генерируют тег «NN».
TreeAnnotations.java : вызовите TreeAnnotations.binarizeTree (дерево) , чтобы преобразовать дерево в двоичную форму, и TreeAnnotations.unBinarizeTree (дерево) преобразовать из двоичного кода обратно в нормальный.
Дерево.java : Найдите в этом файле его полезные функции. Обратите внимание, что вы можете создать собственное дерево:
новое дерево (nonTerminal, children) , где nonTerminal — это имя правила, такое как «NP», а children — это список других деревьев, List
UnaryRule : имеет родителя («NP») и единственного дочернего элемента («NN») и оценку вероятности.
BinaryRule : имеет родителя («NP»), левого дочернего элемента («DT»), правого дочернего элемента («NN») и оценку вероятности.
Настройка кода
Предоставляется стартовый код Java, а также данные для обучения и тестирования. Убедитесь, что у вас есть доступ к следующим каталогам:
/ course / nchamber / nlp / lab6 / java /: код Java, предоставленный для этого курса
/ курсы / nchamber / nlp / lab6 / data /: наборы данных, используемые в этом задании
Создайте каталог lab6 в вашем локальном пространстве и скопируйте в него lab6 / java / ( cp -R / курсы / nchamber / nlp / lab6 / java lab6 / ). Есть сборка .xml , поэтому просто введите ant в каталоге java /. Убедитесь, что он компилируется без ошибок. Ant компилирует все файлы .java в этой структуре каталогов, так что в противном случае вам не придется изменять build.xml. Убедитесь, что вы можете запустить код. Есть сценарий run , который сделает это за вас!
Есть сборка .xml , поэтому просто введите ant в каталоге java /. Убедитесь, что он компилируется без ошибок. Ant компилирует все файлы .java в этой структуре каталогов, так что в противном случае вам не придется изменять build.xml. Убедитесь, что вы можете запустить код. Есть сценарий run , который сделает это за вас!
Настройка Eclipse: нажмите «Создать» -> «Проект» -> «Проект Java из существующего файла сборки Ant». Найдите файл build.xml в новом каталоге lab6. Вы готовы к работе! Откройте CKYParser.java, чтобы увидеть, где вы разместите свой код.
Как запустить код
Используйте сценарий run , и это очень просто. Есть три режима:
run -data miniTest Запускает ваш код на основе одного тестового предложения. Также принимает bioie, genia, combo
run -parser usna.parser.CKYParser Запускает ваш синтаксический анализатор, а не базовый уровень.
Что сдать
- Два файла: out-genia.
 txt и out-bioie.txt, запустив парсер дважды и сохранив результат:
txt и out-bioie.txt, запустив парсер дважды и сохранив результат:
run -data genia -parser usna.parser.CKYParser | & tee out-genia.txt
run -data bioie -parser usna.parser.CKYParser | & tee out-bioie.txt - Ваш каталог lab6 / , содержащий только ваш подкаталог java / . Код, разумеется, должен компилироваться и запускаться с предоставленным вам сценарием run .
Как сдать
Используйте сценарий отправки: / курсы / nchamber / submit
Создайте каталог для своей лаборатории с именем lab6 (, все строчные буквы, ).Когда вы будете готовы ввести свой код, выполните следующую команду из каталога на один уровень выше lab6:
/ курсы / nchamber / submit lab6
Дважды проверьте выходные данные этого сценария, чтобы убедиться, что ваша лабораторная работа была отправлена. Вы несете ответственность, если сценарий не сработал, и вы не заметили этого. Сценарий распечатает «Отправка успешно». в самом конце его вывода. Если вы этого не видите, ваша лаборатория не была отправлена.
Сценарий распечатает «Отправка успешно». в самом конце его вывода. Если вы этого не видите, ваша лаборатория не была отправлена.
Оценка
Этап 1 Мет: 4 очка
Milestone 2 Met: 4 очка
CKY Алгоритм: 50 баллов
Код прокомментирован: 2 балла
Штраф за компиляцию: ваш код не компилируется: -10 баллов
Дополнительный кредит: Реализуйте вертикальную марковизацию: 5 баллов !
Всего: 60 баллов
Разбор с помощью Prolog | CSCI 431
(Обратите внимание: SWI-Prolog должен запускаться с флагом - традиционный для работы с примерами ниже.)
Одной из первоначальных целей разработки Prolog была поддержка обработки естественного языка, включая синтаксический анализ строк. Prolog поддерживает удобный синтаксис, известный как «грамматики с определенными предложениями» (DCG). Набор правил DCG выглядит как Форма Бэкуса-Наура. Они преобразуются в предикаты, которые разбивают входную строку на список символов, и каждый предикат, полученный в результате преобразования DCG, занимает часть списка символов и оставляет после себя остаток, который соответствует другому правилу (или сам рекурсивно).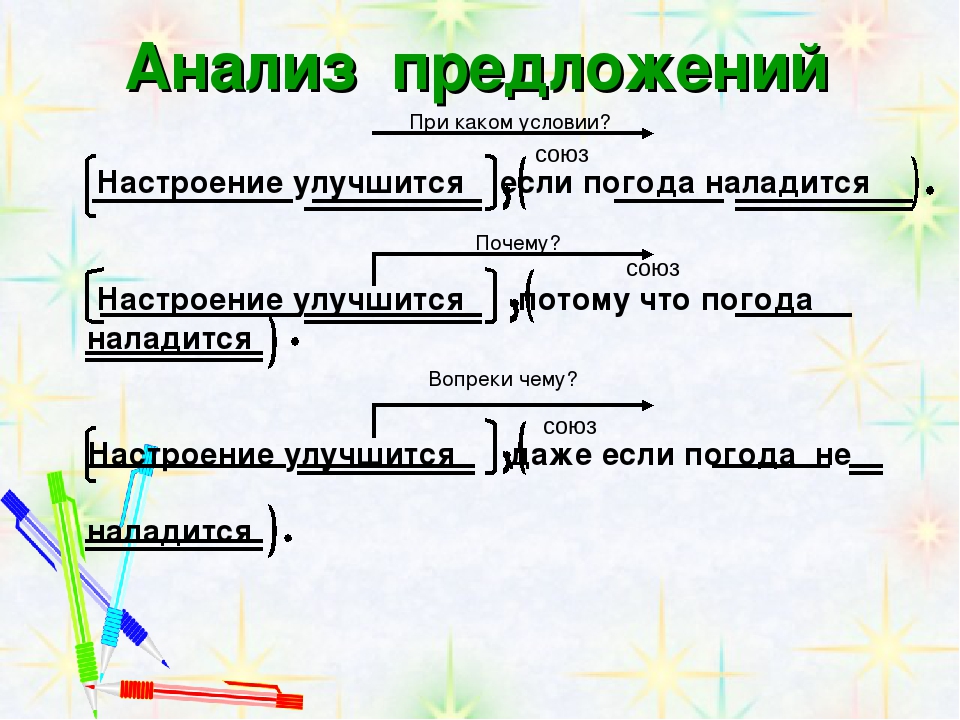 Например, простой синтаксический анализатор предложений на английском языке может быть определен следующим образом.
Например, простой синтаксический анализатор предложений на английском языке может быть определен следующим образом.
предложение -> nounPhrase, "", verbPhrase, ".".
nounPhrase -> определитель, "", существительное.
verbPhrase -> глагол, "", существительноеPhrase.
verbPhrase -> глагол.
определитель -> "the".
определитель -> "а".
существительное -> "кот".
существительное -> "собака".
глагол -> "погони".
глагол -> «избегает».
Поскольку синтаксический анализ с помощью DCG в Prolog эквивалентен поиску соответствующих разделений списка кодов символов, мы можем использовать возможности двунаправленных вычислений Prolog, чтобы дать частичные аргументы и позволить Prolog заполнить остальные.Например, разбор такого предложения, как «кошка избегает собаки», возвращает «истина», т. Е. Предикат предложения совпадает, но мы также можем сгенерировать другие окончания предложения, оставив конец переменной предложения (обозначенной Rest ):
append («кот избегает», Отдых, S), предложение (S, []).
Запрос дает возможные варианты завершения «кошка», «собака», «кошка» и т. Д. Обратите внимание, что мы добавляем [] в качестве второго аргумента к предикату предложения, чтобы указать, что мы не хотим, чтобы после синтаксического анализа оставались символы.
DCG также могут быть записаны таким образом, чтобы они могли накапливать «состояние» во время синтаксического анализа. Например, мы можем написать грамматику, состоящую только из букв «а» и «б», и подсчитать количество а и б:
с (CountA, CountB) -> "a", s (PriorCountA, CountB), {CountA равно PriorCountA + 1}.
s (CountA, CountB) -> «b», s (CountA, PriorCountB), {CountB равен PriorCountB + 1}.
s (0, 0) -> [].
Аргументы CountA и CountB предшествуют обычным аргументам для синтаксического анализа при построении запроса:
с (CountA, CountB, «aa», []). Результат:
Еще одна попытка:
с (CountA, CountB, "aabba", []).
Результат:
Обратите внимание, что {CountA is PriorCountA + 1} часть грамматики является нормальным кодом Prolog. Ограничения {} могут появляться в любом месте грамматики в зависимости от того, когда переменная должна быть ограничена или вычислена. В этой ситуации CountA не может быть вычислено из PriorCountA до тех пор, пока не завершится с (PriorCountA, CountB) , потому что в противном случае мы еще не знаем значение PriorCountA .Это также относится к PriorCountB . Таким образом, ограничения появляются после рекурсивного вызова.
Мы можем определить другую версию предиката s всего с одним дополнительным аргументом (а не двумя), который требует, чтобы количество a и b было одинаковым:
с (CountAB) -> s (CountAB, CountAB).
И запустите такой запрос:
Результат:
Еще одна попытка:
с (CountAB, "aabbab", []).
Результат:
Наконец, если мы попытаемся использовать грамматику двузначно, указав счетчик, но не строку, мы получим бесконечную рекурсию:
s2 (3, Строка, []).% ой, бесконечная рекурсия!
Это связано с тем, что переменные счетчика не ограничены должным образом. Нам нужно использовать программирование логики ограничений для библиотеки конечных доменов (clpfd), чтобы установить границы для счетчиков. Кроме того, нам нужно, чтобы ограничения появлялись в начале правил грамматики, а не в конце, чтобы ограничения были установлены до того, как мы перейдем к рекурсивному глубокому погружению:
: - use_module (библиотека (clpfd)).
s2 (CountAB) ->
{CountAB в 0..20},
s2 (CountAB, CountAB).
s2 (CountA, CountB) ->
{PriorCountA в 0..10, CountA # = PriorCountA + 1},
«а», s2 (PriorCountA, CountB).
s2 (CountA, CountB) ->
{PriorCountB в 0..10, CountB # = PriorCountB + 1},
«b», s2 (CountA, PriorCountB). s2 (0, 0) -> [].
s2 (0, 0) -> [].
Сначала проверим, работает ли обычный синтаксический анализ (дедуктивный анализ):
s2 (CountAB, "aabbab", []).
Первый результат:
Второй результат:
Пока все хорошо.Теперь давайте попробуем абдуктивный (обратный) запрос, то есть мы даем счет, а Пролог генерирует строку:
s2 (3, String, []), формат ("~ s ~ n", [String]).
Первый результат:
Второй результат:
И так далее. Посчитаем, сколько у нас результатов:
setof (String, s2 (3, String, []), AllStrings), длина (AllStrings, L).
По всей видимости, таких строк 20 с тремя а и тремя б. Математически, если мы ограничим количество a и b до «n», то у нас будет (2n)! / (N! N!) Вариаций.
Таким образом, мы определили грамматику, которая накапливает состояние (количество а и б), а также обеспечивает ограничение для этого состояния. Синтаксический анализатор может использоваться в прямом и обратном направлениях, то есть для подсчета a и b из строки или создания строки, которая имеет заданное количество a и b. Как бы то ни было, один и тот же код можно также попросить создать все строки и все подсчеты, которые работают (то есть, не давая никакой информации заранее).
Синтаксический анализатор может использоваться в прямом и обратном направлениях, то есть для подсчета a и b из строки или создания строки, которая имеет заданное количество a и b. Как бы то ни было, один и тот же код можно также попросить создать все строки и все подсчеты, которые работают (то есть, не давая никакой информации заранее).
Грамматика, определяющая равенство a’s и b’s, не зависит от контекста.Мы можем обновить код, чтобы проанализировать неконтекстно-свободную грамматику, например, потребовав серию букв a, за которыми следует серия b, за которыми следует то же количество a, что и в первой серии, и, кроме того, требуя, чтобы b было больше, чем a :
s3 (CountA, CountB) -> s3a (CountA, CountB).
s3a (CountA, CountB) ->
{PriorCountA в 0..10, CountA # = PriorCountA + 1, CountB в 0..10, CountB #> = CountA},
«а», s3a (PriorCountA, CountB), «a».
s3a (0, CountB) -> s3b (CountB).s3a (0, 0) -> [].
s3b (CountB) ->
{PriorCountB в 0..10, CountB # = PriorCountB + 1},
«b», s3b (PriorCountB). s3b (0) -> [].
s3b (0) -> [].
Приведенный выше код поддерживает следующие запросы:
s3 (CA, CB, «aabbbbbbaa», []).
==> Результат: CA = 2, CB = 6
s3 (3, 5, String, []), формат ("~ s ~ n", [String]).
==> Результат: aaabbbbbaaa
setof ((CA, CB, String), s3 (CA, CB, String, []), Result), length (Result, L).
==> Результат: L = 67
Последний запрос показывает, что 67 строк соответствуют грамматике.Конечно, их было бы бесконечно много, если бы мы удалили пределы CountA в 0..10 и CountB в 0..10.
Анализ выражений и операторов — HaskellWiki
Мы используем библиотеку Parsec для синтаксического анализа небольшой грамматики выражений и операторов. Основная цель — продемонстрировать makeTokenParser и buildExpressionParser , которые охватывают большой класс общих приложений.
Мы будем использовать эти модули:
> Контроль импорта.Аппликативный ((<*)) > импортировать Text.Parsec > импортировать Text.Parsec.String > импортировать Text.Parsec.Expr > импортировать Text.Parsec.Token > импортировать Text.Parsec.Language
Пример грамматики
Вот грамматика выражения:
expr :: = var | const | ( выражение ) | unop expr | выражение дуоп выражение
var :: = letter { letter | цифра } * const :: = true | ложный
unop :: = ~
duop :: = & | знак равно
Приоритет операторов сверху вниз: ~, &, =.Оба бинарных оператора левоассоциативны.
Вот грамматика оператора:
stmt :: = nop | var : = expr | if expr then stmt else stmt fi | в то время как expr do stmt od
| stmt {; stmt } + В дополнение к этим грамматикам мы также разрешим блочные комментарии, такие как {- это комментарий -}.
Мы проанализируем эти грамматики во внутреннее представление (абстрактное синтаксическое дерево).(В некоторых приложениях вы пропускаете внутреннее представление и сразу переходите к оценке или генерации кода или … но давайте исправим здесь только одну цель.) Вот внутреннее представление:
> data Expr = Var String | Con Bool | Уно Уноп Экспр | Duo Duop Expr Expr > производное шоу > data Unop = Не выводить Показать > Дуоп данных = И | Iff производное шоу > данные Stmt = Nop | Строка: = Выражение | Если Expr Stmt Stmt | Хотя Expr Stmt > | Seq [Stmt] > производное шоу
Образец парсера
Вот план.Заполните запись, чтобы указать комментарии, роли персонажей (что входит в идентификаторы, что входит в операторы), зарезервированные слова, зарезервированные операторы. Передайте эту запись makeTokenParser и получите запись служебных парсеров, которые позволяют нам работать на уровне токена (а не на уровне персонажа). Синтаксический анализатор выражений получается с помощью buildExpressionParser . Парсер операторов написан как парсер рекурсивного спуска.
Парсер операторов написан как парсер рекурсивного спуска.
Определить символы
LanguageDef — это имя типа записи, которую мы должны заполнить.Предусмотрено множество предустановок, поэтому мы можем выбрать один и просто настроить несколько полей. Минималистский пресет — emptyDef , и мы меняем его с помощью:
def = emptyDef {commentStart = "{-"
, commentEnd = "-}"
, identityStart = буква
, identityLetter = alphaNum
, opStart = oneOf "~ & =:"
, opLetter = oneOf "~ & =:"
, reservedOpNames = ["~", "&", "=", ": ="]
, reservedNames = ["истина", "ложь", "нет",
«если», «то», «еще», «фи»,
«пока», «делать», «од»]
}
Сделать анализатор токенов
Когда мы передаем вышеуказанную запись в makeTokenParser , возвращаемое значение - это запись типа TokenParser . Его поля - это небольшие парсеры, которые мы можем использовать. Они анализируют и возвращают различные токены (идентификаторы, операторы, зарезервированные вещи, всевозможные скобки) и пропускают комментарии, как мы указали. Они также едят пробелы после токенов. Используя их, наш синтаксический анализатор выражений и синтаксический анализатор операторов можно писать на уровне токенов, не беспокоясь о пробелах. Единственное предостережение: они не едят пробелы в самом, самом, самом начале, и мы должны делать это сами, но даже это делается легко.
Его поля - это небольшие парсеры, которые мы можем использовать. Они анализируют и возвращают различные токены (идентификаторы, операторы, зарезервированные вещи, всевозможные скобки) и пропускают комментарии, как мы указали. Они также едят пробелы после токенов. Используя их, наш синтаксический анализатор выражений и синтаксический анализатор операторов можно писать на уровне токенов, не беспокоясь о пробелах. Единственное предостережение: они не едят пробелы в самом, самом, самом начале, и мы должны делать это сами, но даже это делается легко.
Из множества предоставленных синтаксических анализаторов мы будем здесь использовать лишь несколько. Используя сопоставление с образцом записи, мы вызываем makeTokenParser def и выбираем только те, которые нам нужны:
TokenParser {parens = m_parens
, идентификатор = m_identifier
, reservedOp = m_reservedOp
, зарезервировано = m_reserved
, semiSep1 = m_semiSep1
, whiteSpace = m_whiteSpace} = makeTokenParser def
Вот обзор того, что делают эти парсеры:
- m_parens
-
m_parens pанализирует открытую скобку, затем запускаетp, затем анализирует закрывающую скобку и возвращает то, что возвращаетp.
- m_identifier
- анализирует и возвращает идентификатор, проверяя, что он не конфликтует с зарезервированным словом.
- m_reservedOp Пример
- :
m_reservedOp ": ="проверяет, что следующим токеном является зарезервированный оператор: =. - м_зарезервировано Например,
- :
m_reserved "od"проверяет, что следующий токен является зарезервированным словомod. - м_semiSep1
-
m_semiSep1 pанализирует и возвращает разделенную точкой с запятой последовательность из одного или несколькихp. - m_whiteSpace
- ест пробелы.
Предлагаем вам изучить эти и другие синтаксические анализаторы, представленные в записи. Все они очень удобны.
Анализатор выражений
Синтаксический анализатор выражений получается из buildExpressionParser .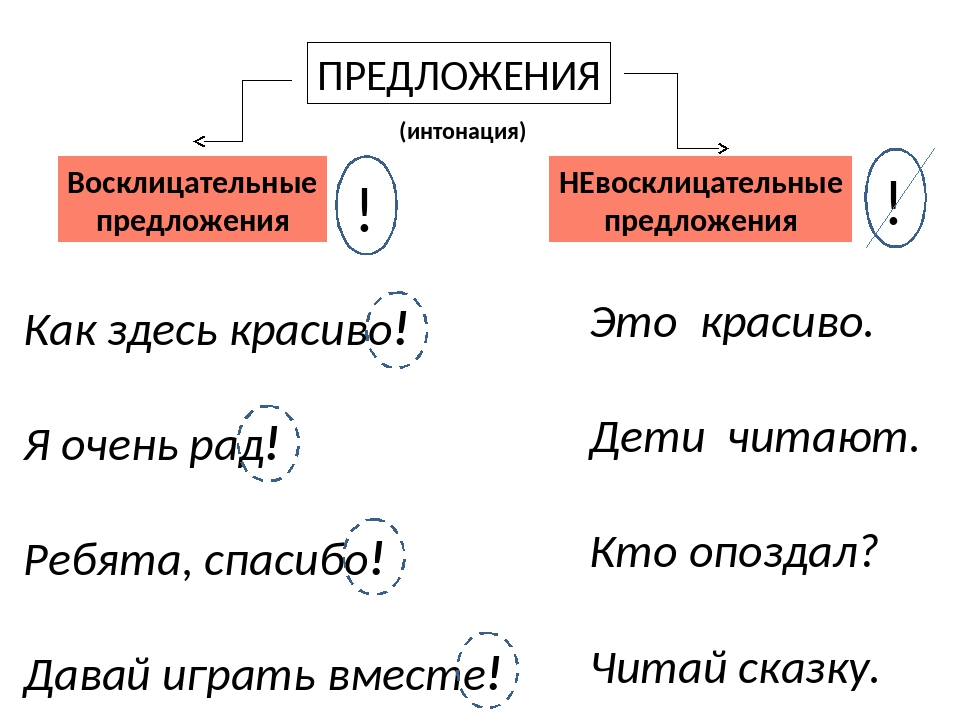 Нам не нужно писать собственный парсер рекурсивного спуска или выполнять левое / правое факторинг.
Нам не нужно писать собственный парсер рекурсивного спуска или выполнять левое / правое факторинг.
exprparser :: Parser Expr
exprparser = buildExpressionParser термин таблицы "выражение"
table = [[Prefix (m_reservedOp "~" >> return (Uno Not))]
, [Infix (m_reservedOp "&" >> return (Duo And)) AssocLeft]
, [Infix (m_reservedOp "=" >> return (Duo Iff)) AssocLeft]
]
термин = m_parens exprparser
<|> fmap Var m_identifier
<|> (m_reserved "true" >> return (Con True))
<|> (m_reserved "false" >> return (Con False))
Мы даем приоритет операторам (упорядочивая их в таблице), ассоциацию, «семантическое действие» и способ анализа «атомарного термина», включая регистр в скобках (единственное место, где мы выполняем рекурсивный спуск, и это тривиально).Можно разместить несколько операторов с одинаковым приоритетом, хотя здесь это не показано. Общий формат таблицы трудно объяснить, но легко проиллюстрировать и скопировать.
Анализатор операторов
Синтаксический анализатор операторов лучше всего выполнять путем рекурсивного спуска со специальной обработкой списка, разделенного точкой с запятой (легко с m_semiSep1 ), с использованием удобных синтаксических анализаторов токенов и синтаксического анализатора выражений. Мы также не забываем пропускать пробелы только один раз в самом, самом, самом начале:
Мы также не забываем пропускать пробелы только один раз в самом, самом, самом начале:
mainparser :: Parser Stmt
mainparser = m_whiteSpace >> stmtparser <* eof
куда
stmtparser :: Parser Stmt
stmtparser = fmap Seq (m_semiSep1 stmt1)
stmt1 = (m_reserved "nop" >> вернуть Nop)
<|> сделать {v <- m_identifier
; m_reservedOp ": ="
; e <- exprparser
; возврат (v: = e)
}
<|> сделать {m_reserved "если"
; b <- exprparser
; m_reserved "тогда"
; p <- stmtparser
; m_reserved "еще"
; q <- stmtparser
; m_reserved "фи"
; return (Если b p q)
}
<|> сделать {m_reserved "пока"
; b <- exprparser
; m_reserved "делать"
; p <- stmtparser
; m_reserved "od"
; возврат (пока б п)
}
Пример использования
Наконец, вот небольшой фрагмент кода для случайного тестирования. Эта функция анализирует строковый параметр и выводит либо ошибку синтаксического анализа, либо ответ.
Эта функция анализирует строковый параметр и выводит либо ошибку синтаксического анализа, либо ответ.
> воспроизведение :: Строка -> IO ()
> play inp = case parse mainparser "" inp of
> {Ошибка влево -> ошибка печати
>; Правый ответ -> распечатать ответ
>}
Введение в NLP
Обработка естественного языка (NLP) - это область информатики и искусственного интеллекта, связанная с взаимодействием между компьютерами и людьми на естественном языке. Конечная цель НЛП - помочь компьютерам понимать язык так же хорошо, как и мы. Это движущая сила таких вещей, как виртуальные помощники, распознавание речи, анализ тональности, автоматическое суммирование текста, машинный перевод и многое другое. В этом посте мы рассмотрим основы обработки естественного языка, погрузимся в некоторые из ее методов, а также узнаем, как НЛП помогло последним достижениям в области глубокого обучения.
Содержание
- Введение
- Почему НЛП сложно
- Синтаксический и семантический анализ
- Методы НЛП
- Глубокое обучение и НЛП
- Ссылки
I.
 Введение
ВведениеОбработка естественного языка (NLP) - это пересечение компьютерных наук, лингвистики и машинного обучения. Эта область фокусируется на общении между компьютерами и людьми на естественном языке, а НЛП - на том, чтобы заставить компьютеры понимать и генерировать человеческий язык. Применения методов НЛП включают голосовых помощников, таких как Amazon Alexa и Apple Siri, а также такие вещи, как машинный перевод и фильтрация текста.
НЛП в значительной степени извлекло выгоду из последних достижений в области машинного обучения, особенно из методов глубокого обучения.Поле разделено на три части:
- Распознавание речи - Перевод разговорной речи в текст.
- Natural Language Understanding - Способность компьютера понимать, что мы говорим.
- Генерация естественного языка - Генерация естественного языка компьютером.
II. Почему НЛП сложно
Человеческий язык особенный по нескольким причинам. Он специально разработан, чтобы передать смысл говорящего / писателя.Это сложная система, хотя маленькие дети могут освоить ее довольно быстро.
Он специально разработан, чтобы передать смысл говорящего / писателя.Это сложная система, хотя маленькие дети могут освоить ее довольно быстро.
Еще одна замечательная вещь в человеческом языке - это то, что все дело в символах. По словам Криса Мэннинга, профессора машинного обучения в Стэнфорде, это дискретная, символическая, категориальная сигнальная система. Это означает, что мы можем передавать одно и то же значение разными способами (например, речь, жест, знаки и т. Д.). Кодирование человеческим мозгом - это непрерывный паттерн активации, посредством которого символы передаются через непрерывные звуковые и визуальные сигналы.
Понимание человеческого языка считается сложной задачей из-за ее сложности. Например, существует бесконечное количество различных способов расположить слова в предложении. Кроме того, слова могут иметь несколько значений, и для правильной интерпретации предложений необходима контекстная информация. Каждый язык более или менее уникален и неоднозначен. Достаточно взглянуть на следующий заголовок в газете «Папа папа наступает на геев». У этого предложения явно есть две очень разные интерпретации, что является довольно хорошим примером проблем в НЛП.
Достаточно взглянуть на следующий заголовок в газете «Папа папа наступает на геев». У этого предложения явно есть две очень разные интерпретации, что является довольно хорошим примером проблем в НЛП.
Обратите внимание, что идеальное понимание языка компьютером приведет к созданию ИИ, способного обрабатывать всю информацию, доступную в Интернете, что, в свою очередь, может привести к созданию общего искусственного интеллекта.
III. Синтаксический и семантический анализ
Синтаксический анализ (синтаксис) и семантический анализ (семантический) - это два основных метода, которые приводят к пониманию естественного языка. Язык - это набор правильных предложений, но что делает предложение действительным? Синтаксис и семантика.
Синтаксис - это грамматическая структура текста, а семантика - это передаваемое значение. Однако синтаксически правильное предложение не всегда является семантически правильным. Например, фраза «коровы в высшей степени текут» грамматически корректна (подлежащее - глагол - наречие), но не имеет никакого смысла.
Синтаксический анализ, также называемый синтаксическим анализом или синтаксическим анализом, представляет собой процесс анализа естественного языка с использованием правил формальной грамматики.Грамматические правила применяются к категориям и группам слов, а не к отдельным словам. Синтаксический анализ в основном придает тексту семантическую структуру.
Например, предложение включает подлежащее и предикат, где подлежащее - это существительная фраза, а предикат - это глагольная фраза. Взгляните на следующее предложение: «Собака (существительная фраза) ушла (глагольная фраза)». Обратите внимание, как мы можем комбинировать каждую именную фразу с глагольной фразой. Опять же, важно повторить, что предложение может быть синтаксически правильным, но не иметь смысла.
Семантический анализ То, как мы понимаем сказанное кем-то, - это бессознательный процесс, основанный на нашей интуиции и знаниях о самом языке. Другими словами, то, как мы понимаем язык, во многом зависит от значения и контекста. Однако к компьютерам нужен другой подход. Слово «семантический» является лингвистическим термином и означает «относящийся к значению или логике».
Другими словами, то, как мы понимаем язык, во многом зависит от значения и контекста. Однако к компьютерам нужен другой подход. Слово «семантический» является лингвистическим термином и означает «относящийся к значению или логике».
Семантический анализ - это процесс понимания значения и интерпретации слов, знаков и структуры предложения.Это позволяет компьютерам частично понимать естественный язык так, как это делают люди. Я говорю отчасти потому, что семантический анализ - одна из самых сложных частей НЛП, и она еще не решена полностью.
Распознавание речи, например, стало очень хорошим и работает почти безупречно, но нам все еще не хватает такого уровня знаний в понимании естественного языка. Ваш телефон в основном понимает то, что вы сказали, но часто ничего не может с этим поделать, потому что не понимает стоящего за этим смысла. Кроме того, некоторые технологии только заставляют вас думать, что они понимают значение текста.Подход, основанный на ключевых словах или статистике, или даже на чистом машинном обучении, может использовать метод сопоставления или частоты для подсказок относительно того, «о чем» текст. Эти методы ограничены, потому что они не смотрят на реальный смысл.
Эти методы ограничены, потому что они не смотрят на реальный смысл.
IV. Методы понимания текста
Давайте рассмотрим некоторые из наиболее популярных методов, используемых при обработке естественного языка. Обратите внимание, как некоторые из них тесно взаимосвязаны и служат только подзадачами для решения более крупных проблем.
ПарсингЧто такое парсинг? Согласно словарю, синтаксический анализ означает «разложить предложение на составные части и описать их синтаксические роли.”
Это действительно помогло, но могло бы быть немного более полным. Под синтаксическим анализом понимается формальный анализ предложения компьютером на его составные части, в результате которого создается дерево синтаксического анализа, показывающее их синтаксические отношения друг с другом в визуальной форме, которое можно использовать для дальнейшей обработки и понимания.
Ниже представлено дерево синтаксического анализа для предложения «Вор ограбил квартиру». Включено описание трех различных типов информации, передаваемых в предложении.
Включено описание трех различных типов информации, передаваемых в предложении.
Буквы, расположенные непосредственно над отдельными словами, показывают части речи для каждого слова (существительное, глагол и определитель). Уровень выше - это некая иерархическая группировка слов во фразы. Например, «вор» - это существительное, «ограбил квартиру» - глагольное словосочетание, и, сложив вместе эти две фразы, образуют предложение, которое отмечается на один уровень выше.
Но что на самом деле означает существительное или глагольная фраза? Существительные словосочетания - это одно или несколько слов, которые содержат существительное и, возможно, некоторые дескрипторы, глаголы или наречия.Идея состоит в том, чтобы сгруппировать существительные со словами, которые к ним относятся.
Дерево синтаксического анализа также предоставляет нам информацию о грамматических отношениях слов из-за структуры их представления. Например, мы видим в структуре, что «вор» является субъектом «ограблен».
Под структурой я подразумеваю, что у нас есть глагол («ограблен»), который отмечен буквой «V» над ним и «VP» над ним, который связан буквой «S» с подлежащим («вор "), над которым есть" NP ".Это похоже на шаблон для отношений подлежащее-глагол, и есть много других для других типов отношений.
СтеммингСтемминг - это метод, основанный на морфологии и поиске информации, который используется в НЛП для предварительной обработки и повышения эффективности. В словаре это определяется как «происходить из или быть вызванным».
По сути, основа - это процесс сокращения слов до их основы. «Основа» - это часть слова, которая остается после удаления всех аффиксов.Например, основа слова «тронут» - «прикоснуться». «Прикосновение» также является основой «прикосновения» и так далее.
Вы можете спросить себя, зачем нам вообще ствол? Что ж, основа нужна, потому что мы встретим разные варианты слов, которые на самом деле имеют одну основу и одинаковое значение. Например:
Например:
Я ехал на машине.
Я ехал в машине.
Эти два предложения означают одно и то же, и использование этого слова идентично.
А теперь представьте себе все английские слова в словаре со всеми их различными фиксациями в конце. Для их хранения потребуется огромная база данных, содержащая множество слов, которые на самом деле имеют одинаковое значение. Это решается путем сосредоточения внимания только на основе слова. Популярные алгоритмы выделения включают алгоритм вывода Портера 1979 года, который до сих пор хорошо работает.
Сегментация текста Сегментация текста в НЛП - это процесс преобразования текста в значимые единицы, такие как слова, предложения, различные темы, лежащее в основе намерение и многое другое.В основном текст разбивается на составляющие слова, что может быть сложной задачей в зависимости от языка. Это опять же из-за сложности человеческого языка. Например, в английском относительно хорошо работает разделение слов пробелами, за исключением таких слов, как «icebox», которые принадлежат друг другу, но разделены пробелом. Проблема в том, что люди иногда также пишут это как «ледяной ящик».
Проблема в том, что люди иногда также пишут это как «ледяной ящик».
Признание именованного объекта
Распознавание именованного объекта (NER) концентрируется на определении того, какие элементы в тексте (т.е. «именованные объекты») могут быть расположены и классифицированы по заранее определенным категориям. Эти категории могут варьироваться от имен людей, организаций и местоположений до денежных значений и процентов.
Например:
До NER: Мартин купил 300 акций SAP в 2016 году.
После NER: [Мартин] Человек купил 300 акций организации [SAP] в [2016] Время.
Извлечение отношений
Извлечение отношений берет названные объекты NER и пытается идентифицировать семантические отношения между ними.Это может означать, например, выяснение, кто с кем женат, что человек работает в определенной компании и так далее. Эта проблема также может быть преобразована в проблему классификации, и модель машинного обучения может быть обучена для каждого типа отношений.
Анализ тональности
С помощью анализа тональности мы хотим определить отношение (то есть настроение) говорящего или писателя по отношению к документу, взаимодействию или событию. Следовательно, это проблема обработки естественного языка, когда текст должен быть понят, чтобы предсказать основное намерение.Настроения в основном делятся на положительные, отрицательные и нейтральные категории.
С помощью анализа настроений, например, мы можем захотеть спрогнозировать мнение и отношение клиента к продукту на основе написанного ими обзора. Анализ тональности широко применяется к обзорам, опросам, документам и многому другому.
Если вам интересно использовать некоторые из этих методов с Python, взгляните на Jupyter Notebook о наборе инструментов естественного языка Python (NLTK), который я создал.Вы также можете ознакомиться с моим сообщением в блоге о построении нейронных сетей с помощью Keras, где я обучаю нейронную сеть выполнять анализ настроений.
V. Глубокое обучение и NLP
Центральным элементом глубокого обучения и естественного языка является «значение слова», где слово и особенно его значение представлены как вектор действительных чисел. С помощью этих векторов, которые представляют слова, мы помещаем слова в многомерное пространство. Интересно то, что слова, представленные векторами, будут действовать как семантическое пространство.Это просто означает, что слова, которые похожи и имеют похожее значение, имеют тенденцию группироваться вместе в этом многомерном векторном пространстве. Вы можете увидеть визуальное представление значения слова ниже:
Вы можете узнать, что означает группа сгруппированных слов, выполнив анализ главных компонентов (PCA) или уменьшение размерности с помощью T-SNE, но иногда это может вводить в заблуждение, потому что они упростите и оставьте много информации на стороне. Это хороший способ начать работу (например, логистическая или линейная регрессия в науке о данных), но он не является передовым и можно сделать это лучше.
Мы также можем думать о частях слов как о векторах, которые представляют их значение. Представьте себе слово «нежелательность». Используя морфологический подход, который включает в себя различные части, которые есть в слове, мы могли бы думать, что оно состоит из морфем (частей слова), например: «Un + желание + способность + ity». Каждая морфема получает свой вектор. Исходя из этого, мы можем построить нейронную сеть, которая может составить значение более крупной единицы, которая, в свою очередь, состоит из всех морфем.
Глубокое обучение также может определять структуру предложений с помощью синтаксических анализаторов.Google использует подобные методы анализа зависимостей, хотя и в более сложной и широкой манере, с их «McParseface» и «SyntaxNet».
Зная структуру предложений, мы можем начать попытки понять смысл предложений. Мы начинаем со значения слов, являющихся векторами, но мы также можем сделать это с целыми фразами и предложениями, где значение также представлено в виде векторов. И если мы хотим знать отношения между предложениями, мы обучаем нейронную сеть принимать эти решения за нас.
И если мы хотим знать отношения между предложениями, мы обучаем нейронную сеть принимать эти решения за нас.
Глубокое обучение также хорошо подходит для анализа настроений. Возьмем, к примеру, этот обзор фильма: «Этот фильм не заботится об остроумии, с каким-либо другим умным юмором». Традиционный подход попался бы в ловушку, полагая, что это положительный отзыв, потому что «сообразительность или любой другой вид умного юмора» звучит как положительное намерение, но нейронная сеть распознала бы его реальное значение. Другие приложения - это чат-боты, машинный перевод, Siri, предлагаемые ответы Google Inbox и так далее.
В машинном переводе также произошел огромный прогресс благодаря появлению рекуррентных нейронных сетей, о которых я также написал сообщение в блоге.
В машинном переводе, выполняемом с помощью алгоритмов глубокого обучения, язык переводится, начиная с предложения и генерируя векторные представления, которые его представляют. Затем он начинает генерировать слова на другом языке, содержащие ту же информацию.
Подводя итог, НЛП в сочетании с глубоким обучением - это все о векторах, которые представляют слова, фразы и т. Д.и до некоторой степени их значения.
VI. Ссылки
Никлас Донгес - предприниматель, технический писатель и эксперт в области искусственного интеллекта. В течение 1,5 лет он работал в команде SAP в области ИИ, после чего основал компанию Markov Solutions. Компания из Берлина специализируется на искусственном интеллекте, машинном обучении и глубоком обучении, предлагая индивидуальные программные решения на базе искусственного интеллекта и консультационные программы для различных компаний.
СвязанныеПодробнее о Data Science
Parse Trees
Завершив реализацию нашей древовидной структуры данных, теперь посмотрим
на примере того, как дерево можно использовать для решения некоторых реальных задач.В
В этом разделе мы рассмотрим деревья разбора. Деревья разбора можно использовать для
представляют собой конструкции реального мира, такие как предложения или математические
выражения.
На схеме ниже показана иерархическая структура простое предложение. Представление предложения в виде древовидной структуры позволяет нам работать с отдельными частями предложения с помощью поддеревьев.
Дерево синтаксического анализа для простого предложения
Мы также можем представить математическое выражение, такое как ((7 + 3) × (5−2)) ((7 + 3) \ times (5-2)) ((7 + 3) × (5−2)) как дерево синтаксического анализа, как показано ниже.
Дерево синтаксического анализа для (7 + 3) * (5-2)
Мы уже рассмотрели полностью
заключенные в скобки выражения, так что мы знаем об этом выражении? Мы
знайте, что умножение имеет более высокий приоритет, чем сложение или
вычитание. Благодаря круглым скобкам мы знаем, что прежде чем мы сможем сделать
умножение, мы должны оценить сложение в скобках и
выражения вычитания. Иерархия дерева помогает нам понять
порядок оценки всего выражения. Прежде чем мы сможем оценить
умножение верхнего уровня, мы должны оценить сложение и
вычитание в поддеревьях. Дополнение, которое является левым поддеревом,
принимает значение 10. Вычитание, которое является правым поддеревом, оценивает
на 3. Используя иерархическую структуру деревьев, мы можем просто заменить
целое поддерево с одним узлом после того, как мы вычислили выражения
в детях. Применение этой процедуры замены дает нам
упрощенное дерево показано ниже.
Дополнение, которое является левым поддеревом,
принимает значение 10. Вычитание, которое является правым поддеревом, оценивает
на 3. Используя иерархическую структуру деревьев, мы можем просто заменить
целое поддерево с одним узлом после того, как мы вычислили выражения
в детях. Применение этой процедуры замены дает нам
упрощенное дерево показано ниже.
Упрощенное дерево синтаксического анализа для (7 + 3) * (5-2)
В оставшейся части этого раздела мы рассмотрим деревья синтаксического анализа более подробно. деталь.В частности, мы рассмотрим, как построить дерево синтаксического анализа из математического выражения, заключенного в круглые скобки, и как оценить выражение, хранящееся в дереве синтаксического анализа.
Первым шагом в построении дерева синтаксического анализа является разбиение выражения
строка в список токенов. Есть четыре разных вида токенов
на рассмотрение: левые круглые скобки, правые круглые скобки, операторы и
операнды. Мы знаем, что всякий раз, когда мы читаем левую скобку, мы
начало нового выражения, и, следовательно, мы должны создать новое дерево для
соответствуют этому выражению.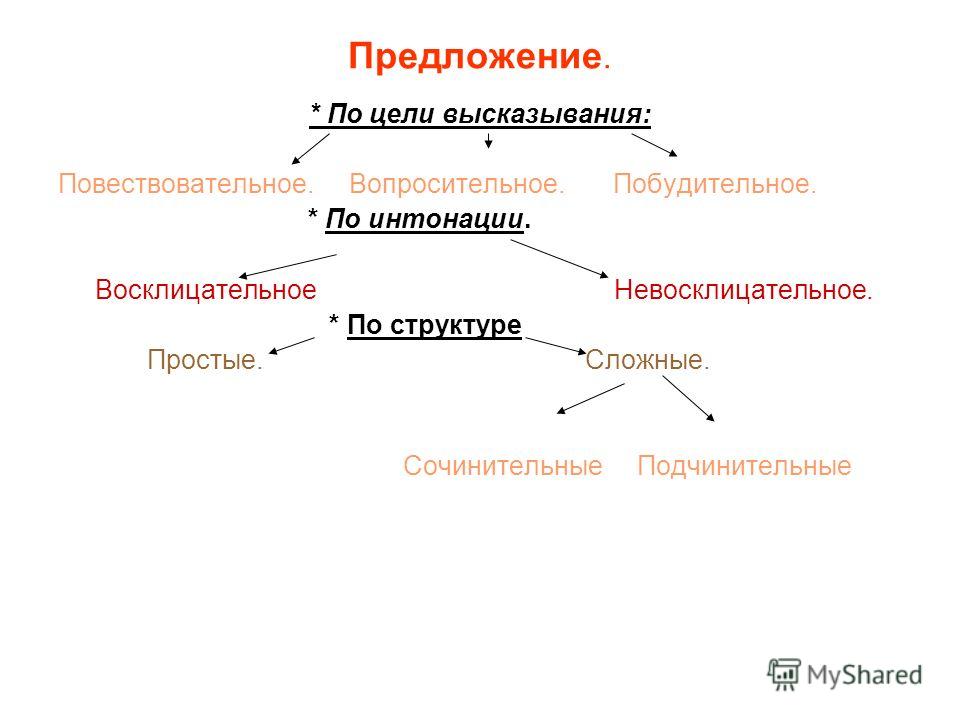 И наоборот, всякий раз, когда мы читаем право
скобки, мы закончили выражение. Мы также знаем, что операнды
будут листовыми узлами и потомками своих операторов. Наконец, мы
знайте, что у каждого оператора будет и левый, и правый потомок.
И наоборот, всякий раз, когда мы читаем право
скобки, мы закончили выражение. Мы также знаем, что операнды
будут листовыми узлами и потомками своих операторов. Наконец, мы
знайте, что у каждого оператора будет и левый, и правый потомок.
Используя информацию выше, мы можем определить четыре правила следующим образом:
- Если текущий токен -
'(', добавить новый узел в качестве левого дочернего элемента текущий узел и спуститесь к левому дочернему элементу. - Если текущий токен находится в списке
['+', '-', '/', '*'], установите корневое значение текущего узла для оператора, представленного текущий токен.Добавить новый узел в качестве правого потомка текущего узла и спуститесь к правому ребенку. - Если текущий токен является числом, установить корневое значение текущего узел к числу и вернуться к родительскому.
- Если текущий токен -
')', перейдите к родительскому элементу текущий узел.
Прежде чем писать код Python, давайте рассмотрим пример правил
изложенное выше в действии. Мы будем использовать выражение (3+ (4 × 5)) (3 + (4 \ times 5)) (3+ (4 × 5)). Мы
проанализирует это выражение в следующем списке токенов символов
Мы будем использовать выражение (3+ (4 × 5)) (3 + (4 \ times 5)) (3+ (4 × 5)). Мы
проанализирует это выражение в следующем списке токенов символов ['(', '3', '+', '(', '4', '*', '5', ')', ')'] .Первоначально мы будем
начните с дерева синтаксического анализа, которое состоит из пустого корневого узла.
Рисунки ниже иллюстрируют структуру и содержание.
дерева синтаксического анализа по мере обработки каждого нового токена.
Построение дерева синтаксического анализа трассировки
Используя приведенное выше, давайте рассмотрим пример шаг за шагом:
- Создайте пустое дерево.
- Прочтите (как первый токен.По правилу 1 создайте новый узел как левый дочерний элемент корня. Сделайте текущий узел этим новым дочерним элементом.
- Прочтите 3 как следующий токен. По правилу 3 установите корневое значение
текущий узел на 3 и вернуться вверх по дереву к родительскому.

- Прочтите + как следующий токен. По правилу 2 установите корневое значение текущий узел в + и добавить новый узел в качестве правого дочернего элемента. Новый правый дочерний элемент становится текущим узлом.
- Прочтите (как следующий токен. По правилу 1 создайте новый узел как левый дочерний элемент текущего узла.Новый левый ребенок становится текущий узел.
- Прочтите 4 как следующий токен. По правилу 3 установите значение текущего node в 4. Сделайте родительский элемент 4 текущим узлом.
- Прочитать * как следующий токен. По правилу 2 установите корневое значение текущий узел на * и создать новый правый дочерний элемент. Новый правый ребенок становится текущим узлом.
- Считайте 5 как следующий жетон. По правилу 3 установите корневое значение текущий узел равен 5. Сделать родительский узел 5 текущим узлом.
- Read) в качестве следующего токена.По правилу 4 мы делаем родителем * текущий узел.
- Read) в качестве следующего токена.
 По правилу 4 мы делаем родительский элемент +
текущий узел. На этом этапе для + нет родителя, так что все готово.
По правилу 4 мы делаем родительский элемент +
текущий узел. На этом этапе для + нет родителя, так что все готово.
Из приведенного выше примера ясно, что нам нужно отслеживать текущие узел, а также родительский узел текущего узла. Простое решение для хранения отслеживание родителей при обходе дерева заключается в использовании стека. Когда мы хотим чтобы спуститься к дочернему элементу текущего узла, мы сначала нажимаем текущий узел на стек.Когда мы хотим вернуться к родительскому элементу текущего узла, мы открываем родитель вне стека.
Используя правила, описанные выше, вместе с абстрактным стеком и двоичным деревом типы данных, теперь мы готовы написать функцию Python для создания синтаксического анализа дерево. Код для нашего построителя дерева синтаксического анализа представлен ниже.
оператор импорта
ОПЕРАТОРЫ = {
'+': operator.add,
'-': operator.sub,
'*': operator.mul,
'/': operator.truediv
}
LEFT_PAREN = '('
RIGHT_PAREN = ')'
def build_parse_tree (выражение):
дерево = {}
стек = [дерево]
узел = дерево
для токена в выражении:
если токен == LEFT_PAREN:
узел ['left'] = {}
куча. добавить (узел)
узел = узел ['влево']
токен elif == RIGHT_PAREN:
узел = stack.pop ()
токен elif в ОПЕРАТОРАХ:
узел ['val'] = токен
узел ['right'] = {}
stack.append (узел)
узел = узел ['право']
еще:
узел ['val'] = int (токен)
родительский = stack.pop ()
узел = родитель
дерево возврата
добавить (узел)
узел = узел ['влево']
токен elif == RIGHT_PAREN:
узел = stack.pop ()
токен elif в ОПЕРАТОРАХ:
узел ['val'] = токен
узел ['right'] = {}
stack.append (узел)
узел = узел ['право']
еще:
узел ['val'] = int (токен)
родительский = stack.pop ()
узел = родитель
дерево возврата
Четыре правила построения дерева синтаксического анализа закодированы как четыре предложения
из заявления if выше.В каждом случае вы можете видеть, что код реализует
правило.
Теперь, когда мы построили дерево синтаксического анализа, мы можем написать функцию для его оценки, возвращает числовой результат. Чтобы написать эту функцию, мы будем использовать иерархическая природа дерева для написания алгоритма, который оценивает анализировать дерево путем рекурсивной оценки каждого поддерева.
Естественным базовым случаем для рекурсивных алгоритмов, работающих с деревьями, является проверка
для листового узла. В дереве синтаксического анализа листовые узлы всегда будут операндами.Поскольку числовые объекты, такие как целые числа и числа с плавающей запятой, больше не требуют
интерпретация, функция
В дереве синтаксического анализа листовые узлы всегда будут операндами.Поскольку числовые объекты, такие как целые числа и числа с плавающей запятой, больше не требуют
интерпретация, функция оценки может просто вернуть значение, хранящееся в
листовой узел. Рекурсивный шаг, который перемещает функцию к базовому случаю
вызывает и оценивает как для левого, так и для правого потомков текущего
узел. Рекурсивный вызов эффективно перемещает нас вниз по дереву к листу
узел.
Чтобы объединить результаты двух рекурсивных вызовов, мы можем просто применить оператор, хранящийся в родительском узле, для результатов, возвращаемых при оценке оба ребенка.В приведенном выше примере мы видим, что два дочерних элемента root вычислить себе, а именно 10 и 3. Применяя умножение оператор дает нам окончательный результат 30.
Код для рекурсивной функции оценки показан ниже. Сначала получаем
ссылки на левый и правый дочерние элементы текущего узла. Если оба
левый и правый дочерние элементы оцениваются как
Если оба
левый и правый дочерние элементы оцениваются как Нет , тогда мы знаем, что текущий узел
действительно листовой узел. Если текущий узел не является листовым, найдите
в текущем узле и примените его к результатам рекурсивно
оценивая левых и правых детей.
Для реализации арифметики используем словарь с клавишами '+', '-', '*' и '/' . Значения, хранящиеся в словаре:
функции из модуля оператора Python. Модуль оператора предоставляет нам
с функциональными версиями многих часто используемых операторов. Когда мы
найти оператор в словаре, соответствующий объект функции
извлекается. Поскольку полученный объект является функцией, мы можем назвать его
обычным способом функция (param1, param2) .Итак, поиск ОПЕРАТОРЫ ['+'] (2, 2) эквивалентно operator.add (2, 2) .
def оценить (дерево):
пытаться:
operation = ОПЕРАТОРЫ [дерево ['val']]
возвратите операцию (оцените (дерево ['слева']), оцените (дерево ['справа']))
кроме KeyError:
дерево возврата ['val']
Наконец, мы проследим функцию оценивать в дереве синтаксического анализа, которое мы создали. над. Когда мы впервые вызываем
над. Когда мы впервые вызываем оценивать , мы передаем корень всего дерева как
параметр parse_tree .Тогда, поскольку левый и правый потомки существуют, мы
найдите оператор в корне дерева, который равен '+' , и который отображает
в оператор . добавьте функцию . Как обычно при вызове функции Python, первый
то, что делает Python, - это оценка параметров, которые передаются в
функция. В этом случае оба параметра являются рекурсивными вызовами функций нашего оценить функцию . Используя вычисление слева направо, первый рекурсивный вызов
идет налево. В первом рекурсивном вызове задается функция оценки левое поддерево.Мы обнаруживаем, что у узла нет левых или правых потомков, поэтому мы
находятся в листовом узле. Когда мы находимся в листовом узле, мы просто возвращаем сохраненное значение
в листовом узле в результате оценки. В этом случае мы возвращаем
целое число 3.
На этом этапе у нас есть один оцененный параметр для нашего вызова верхнего уровня оператор.. Но мы еще не закончили. Продолжая слева направо
оценки параметров, теперь мы делаем рекурсивный вызов для оценки
правый дочерний элемент корня. Мы обнаруживаем, что узел имеет как левый, так и
правый дочерний элемент, поэтому мы ищем оператор, хранящийся в этом узле,  Добавить
Добавить '*' , и
вызовите эту функцию, используя в качестве параметров левого и правого дочерних элементов.На этом этапе вы можете видеть, что оба рекурсивных вызова будут обращаться к листу
узлы, которые будут оценивать целые числа четыре и пять соответственно.
После оценки двух параметров мы возвращаем результат operator.mul (4, 5) . На этом этапе мы оценили операнды для
оператор верхнего уровня '+' , и все, что осталось сделать, это закончить
Звоните на оператора. добавить (3, 20) . Результат оценки всего
дерево выражений для (3+ (4 × 5)) (3 + (4 \ times 5)) (3+ (4 × 5)) равно 23.
