Определение части речи слов в русском тексте (POS-tagging) на Python 3 / Хабр
Пусть, дано предложение “Съешьте еще этих мягких французских булок, да выпейте чаю.”, в котором нам нужно определить часть речи для каждого слова:
[('съешьте', 'глаг.'), ('еще', 'нареч.'), ('этих', 'местоим. прил.'), ('мягких', 'прил.'), ('французских', 'прил.'), ('булок', 'сущ.'), ('да', 'союз'), ('выпейте', 'глаг.'), ('чаю', 'сущ.')]
Зачем это нужно? Например, для автоматического определения тегов для блог-поста (для отбора существительных). Морфологическая разметка является одним из первых этапов компьютерного анализа текста.
Существующие решения
Конечно, все уже придумано до нас. Существует mystem от Яндекса, TreeTagger с поддержкой русского языка, на питоне есть nltk, а также pymorphy от kmike. Все эти утилиты отлично работают, правда, у pymorphy нет поддержки питона 3, а у nltk поддержка третей версии питона только в бете (и там вечно что-то отваливается). Но реальная цель для создания модуля — академическая, понять как работает морфологический анализатор.
Но реальная цель для создания модуля — академическая, понять как работает морфологический анализатор.
Алгоритм
Для начала разберемся, как обычный человек определяет к какой части речи относится слово.
- Обычно мы знаем к какой части речи относится знакомое нам слово. Например, мы знаем, что “съешьте” — это глагол.
- Если нам встречается слово, которое мы не знаем, то мы можем угадать часть речи, сравнивая с уже знакомыми словами. Например, мы можем догадаться, что слово “конгруэнтность” — это существительное, т.е. имеет окончание “
- Мы также можем догадаться какая это часть речи, проследив за цепочкой слов в предложении: “съешьте французских x” — в этом примере, х скорее всего будет существительным.
- Длина слова также может дать полезную информацию. Если слово состоит всего лишь из одной или двух букв, то скорее всего это предлог, местоимение или союз.

Конечно, для компьютера эта задача будет несколько сложнее, т.к. у него нет той базы знаний, которой обладает человек. Но мы постараемся смоделировать обучение компьютера, используя доступные нам данные.
Данные
Для обучения нашего скрипта я использовал национальный корпус русского языка. Часть корпуса, СинТагРус, представляет собой коллекцию текстов с размеченной информацией для каждого слова, такой как, часть речи, число, падеж, время глагола и т.д. Так выглядит часть корпуса в XML формате:
<se> <w><ana lex="между" gr="PR"></ana>М`ежду</w> <w><ana lex="то" gr="S-PRO,n,sg=ins"></ana>тем</w> <w><ana lex="конкурент" gr="S,m,anim=pl,nom"></ana>конкур`енты</w> <w><ana lex="наступать" gr="V,ipf,intr,act=pl,praes,3p,indic"></ana>наступ`ают</w> <w><ana lex="на" gr="PR"></ana>на</w> <w><ana lex="пятка" gr="S,f,inan=pl,acc"></ana>п`ятки</w> .</se> <se> <w><ana lex="вот" gr="PART"></ana>Вот</w> <w><ana lex="так" gr="ADV-PRO"></ana>так</w>, <w><ana lex="за" gr="PR"></ana>з`а</w> <w><ana lex="пять" gr="NUM=acc"></ana>пять</w> <w><ana lex="минута" gr="S,f,inan=pl,gen"></ana>мин`ут</w> <w><ana lex="до" gr="PR"></ana>до</w> <w><ana lex="съемка" gr="S,f,inan=pl,gen"></ana>съёмок</w> , <w><ana lex="родиться" gr="V,pf,intr,med=m,sg,praet,indic"></ana>род`илс`я</w> <w><ana lex="новый" gr="A=m,sg,nom,plen"></ana>н`овый</w> <w><ana lex="персонаж" gr="S,m,anim=sg,nom"></ana>персон`аж</w> . </se>

Предложения заключены в теги <se>, внутри которых расположены слова в теге <w>. Информация о каждом слове содержится в теге <ana>, аттрибут lex соответствует лексеме, gr — грамматические категории.
'S': 'сущ.',
'A': 'прил.',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.'
SVM
В качестве алгоритма обучения я выбрал метод опорных векторов (SVM). Если вы не знакомы с SVM или алгоритмами машинного обучения в общем, то представьте, что SVM это некий черный ящик, который принимает на вход характеристики данных, а на выходе классификацию по заранее заданным категориям. В качестве характеристик мы зададим, например, окончание слова, а в качестве категорий — части речи.
Чтобы черный ящик автоматически распознавал часть речи, для начала его нужно обучить, т. е. дать много характеристик примеров на вход, и соответствующие им части речи на выход. SVM построит модель, которая при достаточных данных будет в большинстве случаев корректно определять часть речи.
е. дать много характеристик примеров на вход, и соответствующие им части речи на выход. SVM построит модель, которая при достаточных данных будет в большинстве случаев корректно определять часть речи.
Даже в академических целях реализовать SVM лень, поэтому воспользуемся готовой библиотекой LIBLINEAR на С++, которая имеет обертку для питона. Для обучения модели используем функцию
'''
съешьте - глагол
выпейте - глагол
чаю - сущ.
'''
x = [{1001: 1, 2001: 1, 3001: 1}, # 1001 - съешьте, 2001 - ьте, 3001 - те
{1002: 1, 2002: 1, 3001: 1}, # 1002 - выпейте, 2002 - йте, 3001 - те
{1003: 1, 2003: 1, 3002: 1}] # 1003 - чаю, 2003 - чаю, 3002 - аю
y = [1, 1, 2] # 1 - глагол, 2 - сущ.
import liblinearutil as svm
problem = svm.problem(y, x) # создаем задачу
param = svm.parameter('-c 1 -s 4') # параметры обучения
model = svm.train(prob, param) # обучаем модель
# используем модель для распознания слова 'съешьте'
label, acc, vals = svm.predict([0], {1001: 1, 2001: 1, 3001: 1}, model, '') # [0] - обозначает, что часть речи нам неизвестна
В итоге наш алгоритм такой:
- Читаем файл корпуса и для каждого слова определяем его характеристики: само слово, окончание (2 и 3 последних буквы), приставка (2 и 3 первые буквы), а также части речи предыдущих слов
- Каждой части речи и характеристике присваиваем порядковый номер и создаем задачу для обучения SVM
- Обучаем модель SVM
- Используем обученную модель для определения части речи слов в предложении: для этого каждое слово нужно опять представить в виде характеристик и подать на вход SVM модели, которая подберет наиболее подходящий класс, т.е. часть речи.
Реализация
С исходными кодами можете ознакомиться здесь: github.
Корпус
Для начала нужно получить размеченный корпус. Национальный корпус русского языка распространяется очень загадочным образом. На самом сайте корпуса можно только производить поиск по текстам, но при этом скачать целиком корпус нельзя:
“Оффлайновая версия корпуса недоступна, однако для свободного пользования предоставляется случайная выборка предложений (с нарушенным порядком) из корпуса со снятой омонимией объёмом 180 тыс. словоупотреблений (90 тыс. – пресса, по 30 тыс. из художественных текстов, законодательства и научных текстов)”.
“The corpus will be made available off-line and distributed for non-commercial purposes, but currently due to some technical and/or copyright problems it is accessible only on-line.”
Хотя для наших целей пойдет и небольшая выборка из корпуса, доступная тут: www.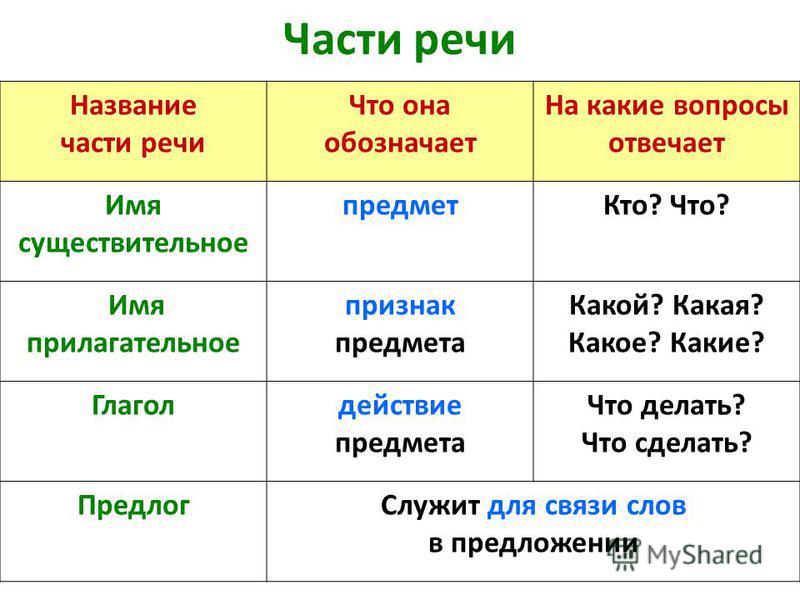 ruscorpora.ru/download/shuffled_rnc.zip
ruscorpora.ru/download/shuffled_rnc.zip
Файлы в полученном архиве нужно пропустить через утилиту convert-rnc.py, которая переводит текст в UTF-8 и исправляет XML разметку. После этого, возможно, еще нужно пофиксить XML вручную (xmllint вам в помощь). Файл rnc.py содержит простой класс Reader для чтения нормализованных XML файлов нац. корпуса.
import xml.parsers.expat class Reader: def __init__(self): self._parser = xml.parsers.expat.ParserCreate() self._parser.StartElementHandler = self.start_element self._parser.EndElementHandler = self.end_element self._parser.CharacterDataHandler = self.char_data def start_element(self, name, attr): if name == 'ana': self._info = attr def end_element(self, name): if name == 'se': self._sentences.append(self._sentence) self._sentence = [] elif name == 'w': self._sentence.append((self._cdata, self._info)) elif name == 'ana': self._cdata = '' def char_data(self, content): self._cdata += content def read(self, filename): f = open(filename) content = f.read() f.close() self._sentences = [] self._sentence = [] self._cdata = '' self._info = '' self._parser.Parse(content) return self._sentences

Метод Reader.read(self, filename) читает файл и выдает список предложений:
[[('Вод`итель', {'lex': 'водитель', 'gr': 'S,m,anim=sg,nom'}), ('дес`ятки', {'lex': 'десятка', 'gr': 'S,f,inan=sg,gen'}), ('кот`орую', {'lex': 'который', 'gr': 'A-PRO=f,sg,acc'}), ('прест`упники', {'lex': 'преступник', 'gr': 'S,m,anim=pl,nom'}), ('пойм`али', {'lex': 'поймать', 'gr': 'V,pf,tran=pl,act,praet,indic'}), ('у', {'lex': 'у', 'gr': 'PR'}), ('ВВЦ', {'lex': 'ВВЦ', 'gr': 'S,m,inan,0=sg,gen'}), ('оказ`ал', {'lex': 'оказать', 'gr': 'V,pf,tran=m,sg,act,praet,indic'}), ('им', {'lex': 'они', 'gr': 'S-PRO,pl,3p=dat'}), ('`яростное', {'lex': 'яростный', 'gr': 'A=n,sg,acc,inan,plen'}), ('сопротивл`ение', {'lex': 'сопротивление', 'gr': 'S,n,inan=sg,acc'}), ('за', {'lex': 'за', 'gr': 'PR'}), ('что', {'lex': 'что', 'gr': 'S-PRO,n,sg=acc'}), ('поплат`ился', {'lex': 'поплатиться', 'gr': 'V,pf,intr,med=m,sg,praet,indic'}), ('ж`изнью', {'lex': 'жизнь', 'gr': 'S,f,inan=sg,ins'})]]
Обучение и разметка текста
Библиотеку SVM можно скачать тут: http://www. csie.ntu.edu.tw/~cjlin/liblinear/. Чтобы обертка под питон заработала под 3-й версией я написал небольшой патч.
csie.ntu.edu.tw/~cjlin/liblinear/. Чтобы обертка под питон заработала под 3-й версией я написал небольшой патч.
Файл pos.py содержит два основных класса: Tagger и TaggerFeatures. Tagger — это, собственно, класс, который осуществляет разметку текста, т.е. определяет для каждого слова его часть речи. Метод Tagger.train(self, sentences, labels) принимает в качестве аргументов список предложений (в том же формате, что и выдает rnc.Reader.read), а также список частей речи для каждого слова, после чего обучает SVM модель, используя библиотеку LIBLINEAR. Обученная модель впоследствии сохраняется (через метод Tagger.save), чтобы не обучать модель каждый раз. Метод Tagger.label(self, sentence) производит разметку предложения.
Класс TaggerFeatures предназначен для генерации характеристик для обучения и разметки. TaggerFeatures.from_body() возвращает характеристику по форме слова, т.е. возвращает ID слова в корпусе. TaggerFeatures.from_suffix() и TaggerFeatures.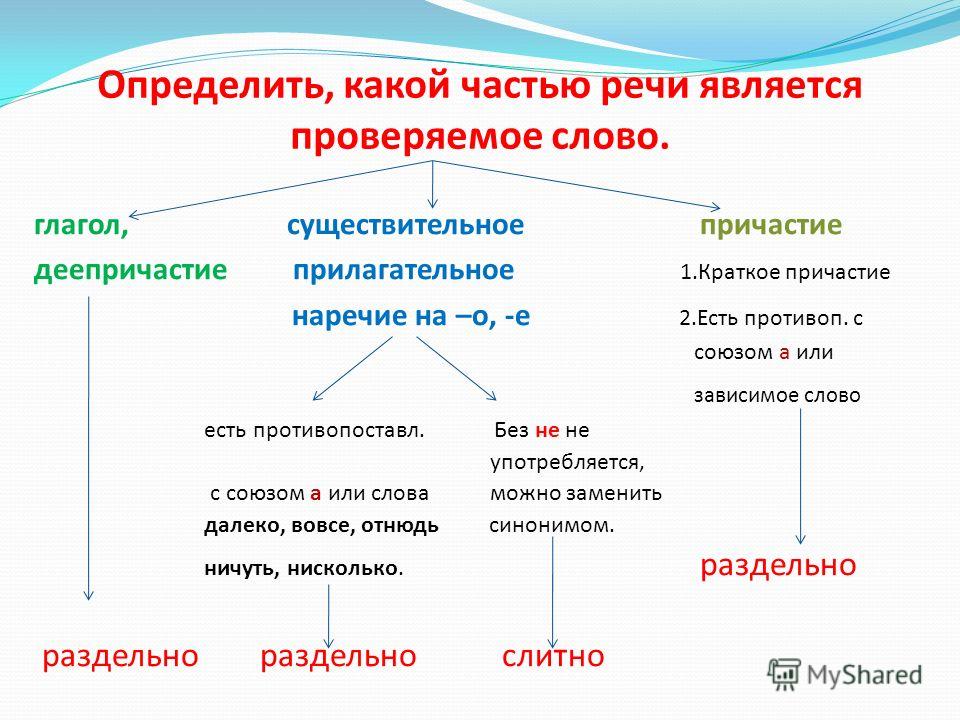 \w-]|$)’.format(‘|’.join(pos.tagset)))
tagger = pos.Tagger()
sentence_labels = []
sentence_words = []
for sentence in sentences:
labels = []
words = []
for word in sentence:
gr = word[1][‘gr’]
m = re_pos.match(gr)
if not m:
print(gr, file = sys.stderr)
pos = m.group(1)
if pos == ‘ANUM’:
pos = ‘A-NUM’
label = tagger.get_label_id(pos)
if not label:
print(gr, file = sys.stderr)
labels.append(label)
body = word[0].replace(‘`’, »)
words.append(body)
sentence_labels.append(labels)
sentence_words.append(words)
tagger.train(sentence_words, sentence_labels, True)
tagger.train(sentence_words, sentence_labels)
tagger.save(‘tmp/svm.model’, ‘tmp/ids.pickle’)
\w-]|$)’.format(‘|’.join(pos.tagset)))
tagger = pos.Tagger()
sentence_labels = []
sentence_words = []
for sentence in sentences:
labels = []
words = []
for word in sentence:
gr = word[1][‘gr’]
m = re_pos.match(gr)
if not m:
print(gr, file = sys.stderr)
pos = m.group(1)
if pos == ‘ANUM’:
pos = ‘A-NUM’
label = tagger.get_label_id(pos)
if not label:
print(gr, file = sys.stderr)
labels.append(label)
body = word[0].replace(‘`’, »)
words.append(body)
sentence_labels.append(labels)
sentence_words.append(words)
tagger.train(sentence_words, sentence_labels, True)
tagger.train(sentence_words, sentence_labels)
tagger.save(‘tmp/svm.model’, ‘tmp/ids.pickle’)
После того, как модель обучена и сохранена, мы, наконец, получили скрипт для разметки текста. Пример использования показан в test.py:
import sys
import pos
sentence = sys.argv[1].split(' ')
tagger = pos.Tagger()
tagger.load('tmp/svm.model', 'tmp/ids.pickle')
rus = {
'S': 'сущ.',
'A': 'прил.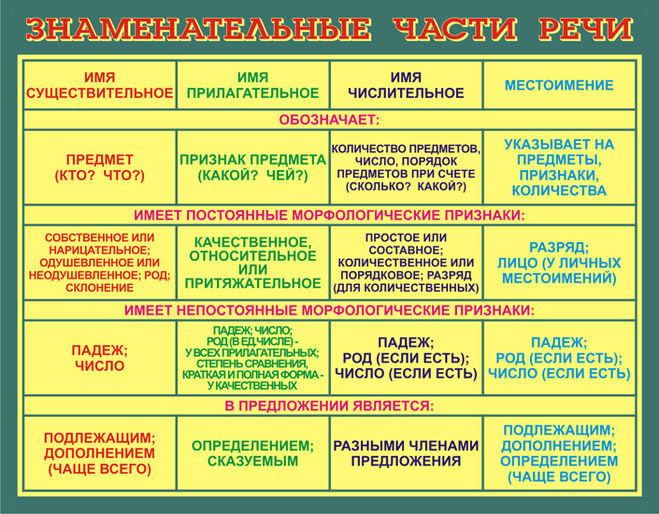 ',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.',
'INIT': 'инит',
'NONLEX': 'нонлекс'
}
tagged = []
for word, label in tagger.label(sentence):
tagged.append((word, rus[tagger.get_label(label)]))
print(tagged)
',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.',
'INIT': 'инит',
'NONLEX': 'нонлекс'
}
tagged = []
for word, label in tagger.label(sentence):
tagged.append((word, rus[tagger.get_label(label)]))
print(tagged)
Работает так:$ src/test.py "Съешьте еще этих мягких французских булок, да выпейте же чаю"
[('Съешьте', 'глаг.'), ('еще', 'нареч.'), ('этих', 'местоим. прил.'), ('мягких', 'прил.'), ('французских', 'прил.'), ('булок,', 'сущ.'), ('да', 'союз'), ('выпейте', 'глаг.'), ('же', 'частица'), ('чаю', 'сущ.')]
Тестирование
Для оценки точности классификации работы алгоритма, метод обучения Tagger.train() имеет необязательного параметр cross_validation, который, если установлен как True, выполнит перекрестную проверку, т.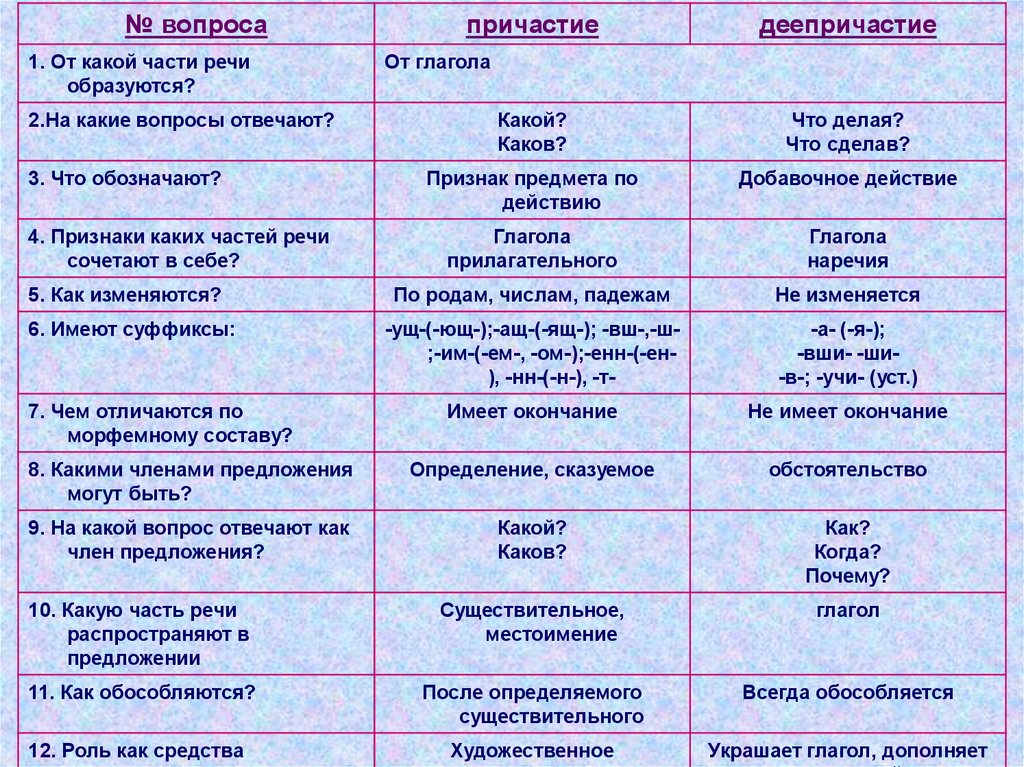 е. данные обучения разбиваются на K частей, после чего каждая часть по очереди используется для оценки работы метода, в то время как остальная часть используется для обучения. Мне удалось добиться средней точности в 92%, что вполне неплохо, учитывая, что была использована лишь доступная часть нац. корпуса. Обычно точность разметки части речи колеблется в пределах 96-98%.
е. данные обучения разбиваются на K частей, после чего каждая часть по очереди используется для оценки работы метода, в то время как остальная часть используется для обучения. Мне удалось добиться средней точности в 92%, что вполне неплохо, учитывая, что была использована лишь доступная часть нац. корпуса. Обычно точность разметки части речи колеблется в пределах 96-98%.
Заключение и планы на будущее
В общем, было интересно поработать с нац. корпусом. Видно, что работа над ним проделана большая, и в нем содержится большое количество информации, которую хотелось бы использовать в полной мере. Я послал запрос на получение полной версии, но ответа пока, к сожалению, нет.
Полученный скрипт разметки можно легко расширить, чтобы он также определял другие морфологические категории, например, число, род, падеж и др. Чем я и займусь в дальнейшем. В перспективе хотелось бы, конечно, написать синтаксический парсер русского языка, чтобы получить структуру предложения, но для этого нужна полная версия корпуса.
Буду рад ответить на вопросы и предложения.
Исходный код доступен здесь: github.com/irokez/Pyrus
Демо: http://vps11096.ovh.net:8080
Части речи 6 класс онлайн-подготовка на Ростелеком Лицей
Самостоятельные части речи
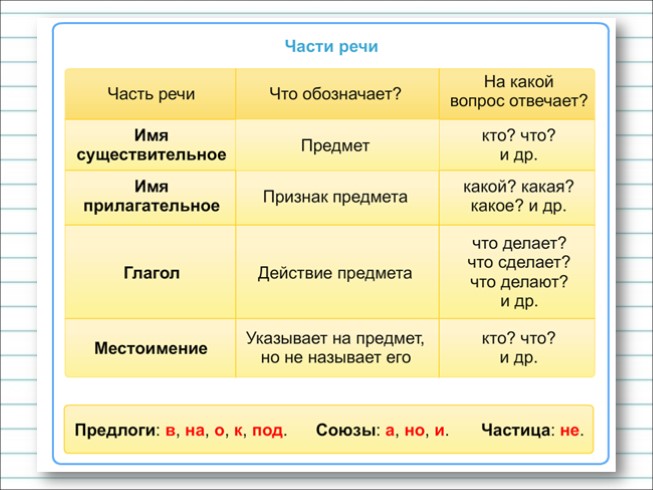
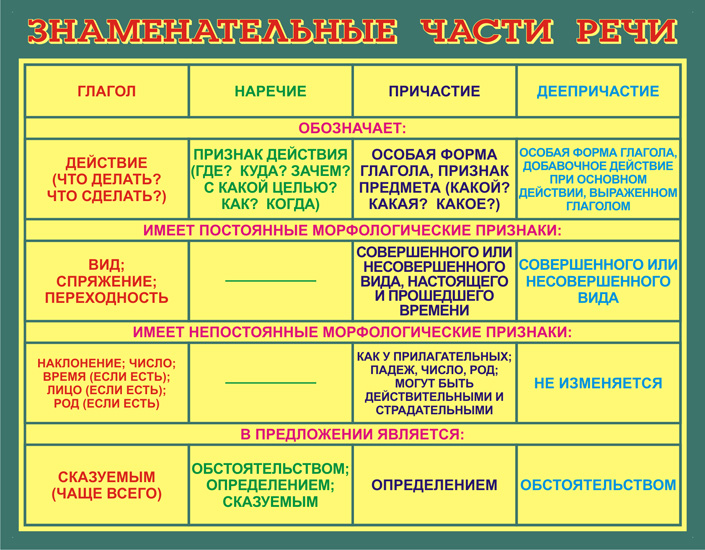
Все части речи в русском языке можно разделить на 3 группы:
1) самостоятельные части речи
2) служебные части речи
3) междометия
Самостоятельные части характеризуются рядом признаков.
Во-первых, самостоятельные части называют предметы, признаки, действия, количества. Во-вторых, самостоятельные части речи отвечают на определенные вопросы.
В-третьих, самостоятельные части речи в предложении являются либо главными, либо второстепенными членами.
Самостоятельные части речи в русском языке – это:
- имя существительное (мама, папа, книга, школа),
- имя прилагательное (добрый, веселый, радостный),
- имя числительное (пять, семь, второй, третий),
- местоимение (я, ты, мы, вы),
- глагол (читать, говорить, рисовать, думать),
- наречие (громко, слева, завтра, издалека),
- причастие (прилетевший, мечтающий),
- деепричастие (думая, прочитав).
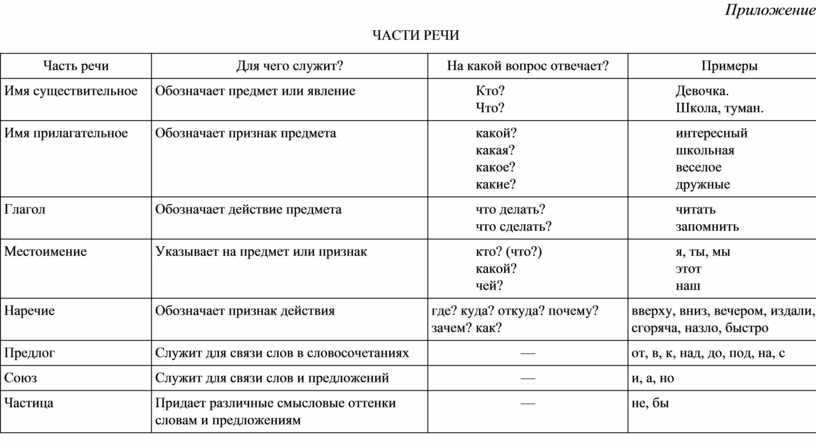
Примечание. Некоторые ученые считают причастие и деепричастие особыми формами глагола.
Отличительные признаки частей речи
Имя существительное – самостоятельная часть речи, которая обозначает предмет и отвечает на вопросы кто? или что?
Имя прилагательное – самостоятельная часть речи, которая обозначает признак предмета и отвечает на вопросы какой? какая? какое? какие? чей? чья? чьё? чьи? Имена прилагательные похожи на разноцветные карандаши художника, делающие наш мир ярким и красочным.
Имя числительное – самостоятельная часть речи, которая обозначает количество предметов (одиннадцать, шестнадцать) или их порядок при счете (четырнадцатый,первый) и отвечает на вопросы сколько? какой по счету?Имя числительное похоже на калькулятор, при помощи которого можно сосчитать количество предметов.
Местоимение – самостоятельная часть речи, которая указывает на предмет, признак, но не называет их. Местоимения напоминают запасных игроков во время футбольного матча. Они выходят на поле только тогда, когда вынужденно освобождают игру – получают травму, чересчур устают – имена существительные и прилагательные.
Местоимения напоминают запасных игроков во время футбольного матча. Они выходят на поле только тогда, когда вынужденно освобождают игру – получают травму, чересчур устают – имена существительные и прилагательные.
Глагол– самостоятельная часть речи, которая обозначает действие предмета и отвечает на вопросы что делать? что сделать? Это самая трудолюбивая часть, которая похожа на Золушку, потому что не может сидеть без дела и трудится 365 дней в году, 24 часа в сутки, 7 дней в неделю.
Наречие – самостоятельная часть речи, которая обозначает признак действия (громко, тихо) или признак признака (очень, чересчур) и отвечает на вопросы где? куда?откуда? как? почему? зачем? когда?Наречие – это любопытная бабушка, которая любит мучить внуков вопросами: где был? куда идешь? откуда пришел? как зовут твоих друзей? когда вернешься? Именно по вопросам любопытной бабушки наречие без труда можно отыскать в предложении.
Деепричастие – самостоятельная часть речи, которая обозначает добавочное действие, отвечает на вопросы что делая? что сделав? и объединяет признаки наречия и глагола. Деепричастие можно сравнить с букетом, который преподносят в дополнение к подарку.
Причастие – самостоятельная часть речи, которая обозначает признак предмета по действию, отвечает на вопросы что делающий? что сделавший?какой? и объединяет в себе свойства прилагательного и глагола. Причастие можно заменить сочетанием КОТОРЫЙ + глагол. Прилетевший -+ который прилетел.
Предлоги служат для связи слов в предложении и словосочетании.
Союзы связывают между собой однородные члены или простые предложения в составе сложного.
Частицы вносят в предложение эмоциональные оттенки (не, даже) или служат для образования форм слов (хотел бы).
Междометия выражают чувства, но не называют их. Для выражения изумления мы используем междометие ах, для выражения страха или боли – ой, чувства холода – бр-р.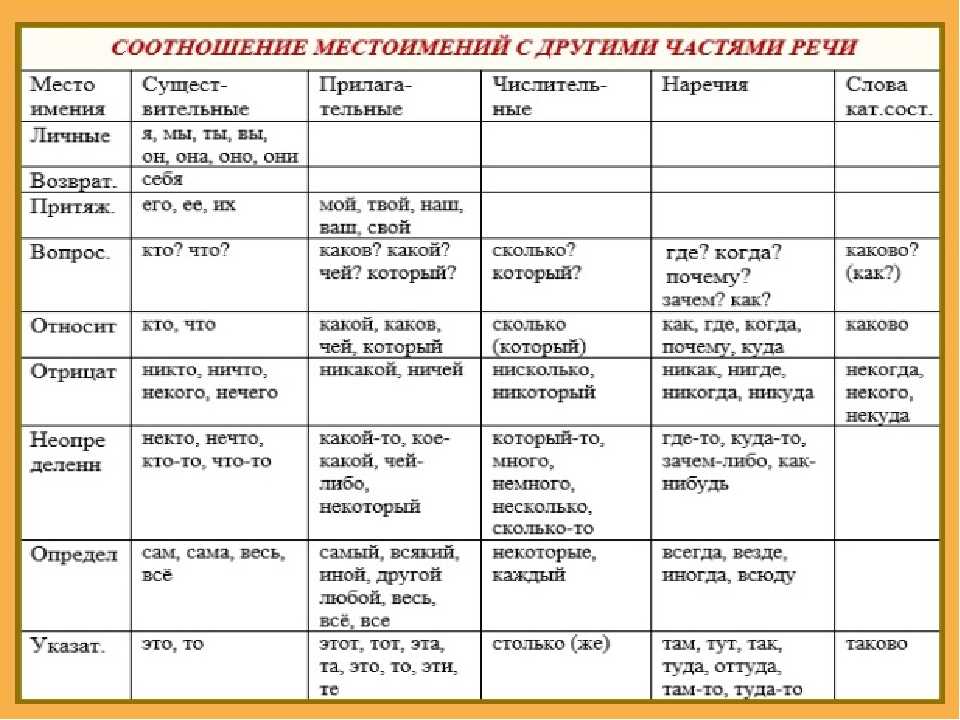
Раздел науки о языке, который изучает слово как часть речи, – это МОРФОЛОГИЯ.
Список литературы
- Русский язык. 6 класс: Баранов М. Т. и др. – М.: Просвещение, 2008.
- Русский язык. Теория. 5–9 кл.: В. В. Бабайцева, Л. Д. Чеснокова – М.: Дрофа, 2008.
- Русский язык. 6 кл.: под ред. М. М. Разумовской, П. А. Леканта – М.: Дрофа, 2010.
Дополнительные рекомендованные ссылки на ресурсы Интернет
- Издательство Лицей (Источник)
- Интернет-портал «gramota.ru» (Источник)
Домашнее задание
Задание № 1
Составьте три предложения, в каждом используйте по пять частей речи.
Задание № 2
Составьте цепочку однокоренных слов, принадлежащих к разным частям речи.
Образец:
Игра – играть – игриво – игральный (в цепочке 4 слова разных частей речи: существительное, глагол, наречие, прилагательное).
Это — Грамматика английского языка сегодня
Грамматика > Существительные, местоимения и определители > Местоимения > That
That — очень распространенное слово как в письменной, так и в устной речи. Мы используем его как определитель, указательное местоимение и относительное местоимение. Мы также используем его как союз, чтобы ввести , что -предложения.
Мы используем , что чаще всего, чтобы указать на вещь или человека. Мы используем его с существительными в единственном числе. Вещь или человек часто находятся далеко от говорящего, а иногда ближе к слушателю или не видны ни говорящему, ни слушающему:
Можешь передать мне вон ту зеленую миску? (определитель)
[указывая на один из вариантов красок]
Мне очень нравится этот.
Это Гарольд в белой рубашке, не так ли? (местоимение)
Мы также используем , что , чтобы обратиться к целому предложению:
A:
У нас есть несколько друзей на ужин.
Вы хотите приехать?
B:
Это звучит прекрасно .
Почему бы тебе не прийти около 8? Это даст мне время подготовиться.
A:
Можешь сказать Кэт поторопиться? Мы должны выйти в 11 .
Б:
Я уже сказал ей что .
Мы используем , что , чтобы обратиться к чему-то, о чем уже говорилось или писалось:
Если он получит эту работу в Лондоне, то сможет чаще навещать нас.
Мы используем и для введения определяющих относительных предложений. Мы можем использовать that вместо who, who или which для обозначения людей, животных и предметов. Этот более неформален, чем который или который :
Она взяла расческу, которую оставила на кровати.
Он был первым директором Национального научного фонда и финансировал научные исследования с годовым бюджетом, который вырос до 500 миллионов долларов.

См. Также:
Относительные положения
Мы также используем , которые , чтобы представить , которые -clauses после некоторых глаголов, прилагательных и существенных:
I Admit, которые были ошибками. (глагол + что -пункт)
Вы уверены, что мужчиной в машине был Ник? (прилагательное + , что -предложение)
Название компании иллюстрирует мою веру в то, что язык жестов является увлекательной формой общения. (существительное + , что -Clause)
См. Также:
, который -clauses
Мы используем , что + прилагательное (например, , что хорошо, это хорошо, что великое, что великое, что , это ужасно ) ответить на что-то, что нам говорят, чтобы показать, что мы слушаем:
A:
Они застряли в пробке по дороге в аэропорт и опоздали на самолет .
B:
О , это ужасно .

Мы используем , а не + прилагательное для обозначения «не очень» или «не так… как вы говорите». Ставим устное ударение на , что :
А:
Я думал, что еда была вкусной .
B:
У меня не было , что приятно . (Моя еда была не такой вкусной, как вы говорите. Моя еда была не вкусной.)
A:
Я не удивлюсь, если Эмили станет актрисой .
Б:
Я не думаю, что она что хорошо .
См. также:
Этот , тот , этот , those
Relative clauses
It , this and that in paragraphs
Verb patterns: verb + that -clause
That -clauses
- 01 Формальный и неформальный язык
- 02 Который
- 03 Дискурсивные маркеры (так, правильно, хорошо)
- 04 Интонация
- 05 Настоящее простое (я работаю)
- 06 Предложить
- 07 Ненавижу, люблю, люблю и предпочитаю
- 08 Прошедшее длительное или прошедшее простое?
- 09 Классы слов и классы фраз
- 10 Инверсия
Проверьте свой словарный запас с помощью наших веселых викторин по картинкам
- {{randomImageQuizHook.
 copyright1}}
copyright1}} - {{randomImageQuizHook.copyright2}}
Авторы изображений
Попробуйте пройти викторину
Слово дня
решетка
Великобритания
Ваш браузер не поддерживает аудио HTML5
/ˈɡrɪd.aɪən/
НАС
Ваш браузер не поддерживает аудио HTML5
/ˈɡrɪd.aɪrn/
поле, разрисованное линиями для американского футбола
Об этом
Блог
Валять, бить и колотить: глаголы для прикосновения и удара (2)
Подробнее
Новые Слова
супернюх
Больше новых слов
Какой частью речи является «Это»
Слово « THAT » может использоваться как определенный артикль, союз, наречие, местоимение и прилагательное. Взгляните на определения и примеры ниже, чтобы узнать, как « THAT » работает как разные части речи.
- Определенный артикул
“ That ” классифицируется как определенный артикль, когда он используется для обозначения чего-то/кого-то определенного, что слушатели или читатели уже знают. Например, прочитайте образец предложения ниже:
«Поднимите тот , закажите на полу».
Человек, с которым разговаривают, точно знает, о какой «книге» говорит говорящий.
Определение:
а. относится к конкретному лицу или предмету, при условии, что лицо, к которому обращаются, понимает или знакомо с ним
- Примеры:
- Посмотрите на ту старуху
- Она жила в Нью-Йорке по адресу , , время .
- Где этот друг твой?
2. Союз
Иногда «это» также может служить союзом, объединяя два предложения. Например, в предложении:
«Я купил материалы , что требуются по проекту ».
« That » используется для введения пункта «…необходимы для проекта». Он объединяет зависимое предложение с независимым: «Я купил материалы…»
Определение :
a. используется для введения предложения, которое является подлежащим или объектом глагола
- Примеры:
- Он сказал что он был голоден.
б. используется для введения предложения, которое завершает или объясняет значение предыдущего существительного, прилагательного или местоимения it
- Примеры:
- Она была так измотана что не могла ясно мыслить .
в. используется для введения пункта, в котором указывается причина или цель
- Примеры:
- Кажется, босс доволен тем, что я хотел продолжить обучение .
3. Наречие
Это слово также может использоваться как наречие, особенно в устной коммуникации. Обычно он используется, чтобы показать силу конкретного прилагательного. Возьмем, к примеру, следующее предложение:
«Он тот старый. »
В этом образце предложения слово « тот » как-то усиливается и показывает степень прилагательного «старый».
Определение:
а. в той степени, которая заявлена или предложена
- Примеры:
- Это не было , что сложное .
б. в степени или пределах, обозначенных жестом
- Примеры:
- Она не пойдет что далеко .
с. в значительной степени
- Примеры:
- Это было , что шириной , возможно, даже шире.
4. Местоимение
В некоторых случаях слово «тот» также функционирует как отдельное местоимение. Посмотрите на пример предложения ниже:
» Это именно то, что я думал».
Можно предположить, что слово » что ” представляет или заменяет конкретную мысль.
Определение:
а. используется для идентификации конкретного человека или предмета, наблюдаемого говорящим
- Примеры:
- Этот мой брат на новой машине.
б. относится к ранее упомянутому, известному или понятному предмету
- Примеры:
- Это не так плохо, как все что .
- Все люди , которые остались позади , заразились вирусом.
5. Прилагательное
Слово «тот» действует как прилагательное, когда оно используется для модификации существительного. Это также полезно для уточнения того, какое существительное имеет в виду говорящий в предложении. Возьмем, к примеру, предложение ниже:
» Этот кот такой очаровательный.